
Содержание страницы
Привет!
Эта статья является кратким справочником по различным инструментам обработки данных, построения pipelines, системам для управления процессом разработки и т.д.
Моя цель — создать короткую статью-обзор, прочитав/просмотрев которую Вы будете примерно представлять весь спектр инструментов для работы с данными на языке Python. В основном упор будет сделан на обработку данных, но также будут упомянуты и другие библиотеки (web разработка, асинхронное программирование, принципы написания кода и т.д.), которые возможно пригодятся для выполнения поставленных перед Вами задач.
Если Вы ищите литературу по направлению Python или Power BI (разработка аналитических приложений), то загляните обязательно в мой Telegram канал @python_powerbi (пишу про разработку на Python, построение аналитических отчетов на Power BI) 😉
Итак, приступим. Начнем с библиотек обработки данных.
Обзор библиотек Python для обработки данных, анализа и визуализации данных
- Numpy — это библиотека языка Python, которая позволяет работать с многомерными массивами и матрицами, в том числе внутри библиотеки есть большой выбор математических функций для выполнения операций над массивами и матрицами.
- Pandas — это библиотека для работы с данными, а именно для анализа данных, трансформации данных (обработки данных), загрузки данных из различных источников и сохранения данных в разных форматах как в файловую систему, так и в базу данных. В качестве структуры данных используется Pandas DataFrame или Pandas Series.
- pyodbc — это Python модуль/библиотека, драйвер для подключения к базе данных через ODBC.
- pymssql — это библиотека Python для подключения к базе данных на MSSQL (но можно использовать и pyodbc).
- SQLAlchemy — это очень популярная библиотека Python для работы с реляционными СУБД для выполнения SQL или для использования технологии ORM (Object-Relational Mapping или объектно-реляционное отображение). ORM необходим для объектно-ориентированных языков программирования. С помощью ORM классы могут быть сопоставлены с базой данных, что позволяет с самого начала четко связать объектную модель и схему базы данных.
- Alembic — это инструмент миграции баз данных, написанный автором SQLAlchemy. Также может использоваться для создания таблиц, их удаления, добавления или удаления полей таблиц.
- SciPy — это пакет прикладных математических процедур (или научных инструментов), основанный на расширении Numpy Python. Содержит модули для оптимизации, интегрирования, специальных функций, обработки сигналов, обработки изображений, генетических алгоритмов, решения обыкновенных дифференциальных уравнений и других задач, обычно решаемых в науке и при инженерной разработке.
- Plotly — это графическая библиотека Python (с открытым исходным кодом), с помощью которой можно создавать интерактивную визуализацию (scatter plots, box plots, 3D графики, bar charts, heatmaps, дендрограммы и т.д.). Если коротко, то эту библиотеку можно охарактеризовать как «Красочное интерактивное отображение датасета в одну строку».
- Dash — это передовой web‑фреймворк Python с открытым исходным кодом, предназначенный для создания реактивных веб-приложений / аналитических веб-приложений. С помощью Dash можно создать интерактивное приложения для аналитических отчетов и просматривать приложение в браузере, при этом не нужно использовать в приложении JavaScript или HTML. Для привязки пользовательского кода анализа данных к пользовательскому интерфейсу в Dash используется реактивный декоратор. С его помощью можно фильтровать DataFrame Pandas, выполнить SQL‑запрос, запустить расчет и т.д.
- Seaborn — это
- json — это модуль python, который позволяет кодировать и декодировать данные в удобном формате. Входит в стандартную библиотеку Python и является эффективным средством взаимодействия с JSON (JavaScript Object Notation).
Библиотеки Python для парсинга страниц web сайтов (Web Scraping) и работа с API сайтов
- Requests — это библиотека, с помощью которой можно отправлять все виды HTTP-запросов к различным ресурсам в сети интернет (сайты, API различных сервисов, поисковики). После выполнения запроса Вы получите ответ от сервера (данные, контент страницы сайта). По сути, с помощью этой библиотеки Вы можете автоматизировать обмен данными с такими ресурсами, как Yandex Метрика, Bitrix24, Мой Склад, Google Analytics, Google BigQuery, AmoCRM, Binance и др.
- Beautiful Soup — это библиотека Python, парсер для синтаксического разбора файлов HTML/XML. Может преобразовать даже неправильную разметку в дерево, состоящее из тегов, элементов, атрибутов и значений.
- Selenium — это это инструмент для автоматизации действий веб-браузера. В большинстве случаев используется для тестирования Web-приложений, но этим не ограничивается. Selenium представляет собой драйвер, который управляет поведением браузера. Состоит из нескольких продуктов: Selenium WebDriver, Selenium RC, Selenium Server, Selenium Grid, Selenium IDE.
- Lxml — это библиотека для парсинга сайтов и документов с разметкой XML и HTML. С её помощью можно разложить элементы документа/страницы в дерево. Обработка производится через XPath (язык запросов к элементам xml или html документа).
- Scrapy — это быстрый бесплатный фреймворк для веб-краулинга (веб-паук, поисковый робот, т.е. для работ по перебору страниц сайта и занесения информации в базу данных) или веб-скрейпинга (получение веб-данных путем извлечения их со страниц веб-ресурсов). С его помощью можно извлечь данные с веб-страниц сайтов с помощью селекторов на основе XPath.
Многопоточность, параллелизм, многопроцессорная обработка — библиотеки Python
В операционной системе существует два типа многозадачности:
- На основе процессов: несколько потоков, работающих в одной ОС одновременно.
- На основе потоков: один процесс, состоящий из отдельных задач.
- AsyncIO — это библиотека Python для написания параллельного кода. Библиотека asyncio позволяет вам писать код, который выглядит и чувствует себя синхронно, но работает асинхронно. Модуль asyncio предоставляет инфраструктуру для написания однопоточного параллельного кода с использованием сопрограмм, мультиплексирования доступа ввода-вывода через сокеты и другие ресурсы, запуска сетевых клиентов и серверов и других связанных примитивов.
- Threading — это стандартная библиотека Python, которая содержит необходимые классы для работы с потоками. Модуль threading значительно упрощает работу с потоками и позволяет программировать запуск нескольких задач одновременно. Python содержит Global Interpreter Lock (GIL), который запускает все потоки внутри главного потока. Если Вы запустите несколько интенсивных операций с потоками, то программа будет работать достаточно медленно, т.к. запуск потоков производится только на одном процессоре.
- Multiprocessing — это Модуль multiprocessing позволяет вам создавать процессы таким же образом, как при создании потоков при помощи модуля threading, но с помощью multiprocessing Вы сможете обойти GIL и использовать несколько процессоров на вашей вычислительной машине. Т.е. в рамках библиотеки multiprocessing Вы можете задействовать несколько процессоров для выполнения ваших операций.
- Aiohttp — это фреймворк для создания асинхронных HTTP Client и/или HTTP Server. Является HTTP-клиентом / сервером для asyncio. Пакет aiohttp также поддерживает Server WebSockets и Client WebSockets.
Python Libraries / Инструменты для Machine Learning
- TensorFlow — это это комплексная платформа для машинного обучения с открытым исходным кодом. Основной объект — это тензор, или многомерный массив чисел. TensorFlow используется для создания многослойных нейронных сетей.
- Keras — это библиотека, позволяющая на более высоком уровне работать с нейросетями, упрощает код, увеличивает быстродействие. Изначально была разработана в целях ускорения экспериментов. Keras может запускаться поверх TensoFlow, Theano или CNTK. Этот фреймворк применяется для перевода, распознавании изображений, речи и т.п.
- Theano — это библиотека Python, которая используется для разработки систем Machine Learning (ML) и Artificial Intelligence (AI) как сама по себе, так и в качестве вычислительного backend для более высокоуровневых библиотек (например для Keras, Lasagne или Blocks). Библиотека построена поверх NumPy. Theano позволяет достигать больших скоростей, которые конкурируют с кодом C, написанным вручную, для задач, связанных с большими объемами данных. Theano компилируется на архитектурах CPU и GPU.
- Scikit-Learn — это инструмент для обработки изображений и имитации искусственного интеллекта. Библиотека построена на SciPy (Scientific Python). Библиотека Scikit-Learn использует в своей реализации NumPy массивы. Она предоставляет широкий выбор алгоритмов обучения с учителем и без учителя. В этой библиотеке находится большое количество алгоритмов для задач, связанных с классификацией и машинным обучением в целом.
- PyTorch — это machine learning framework или библиотека для решения задач с помощью машинного обучения, используется для приложений по обработке естественного языка. PyTorch считается Pythonic, т.е. плавно интегрируется со стеком данных Python. С помощью PyTorch можно построить динамический вычислительный граф. PyTorch сейчас используется в таких компаниях как Twitter, Facebook, NVIDIA и др. PyTorch создана на базе Torch (MATLAB-подобная библиотека для языка программирования Lua). Вокруг фреймворка PyTorch выстроена экосистема из различных библиотек: Fast.ai (упрощающая процесс обучения моделей), Pyro (модуль для вероятностного программирования от Uber), Flair (для обработки естественного языка) и Catalyst (для обучения DL и RL моделей).
- LightGBM (Light Gradient Boosted Machine) — это быстрая, распределенная, высокопроизводительная библиотека для повышения градиента, основанная на алгоритмах обучения на основе дерева решений. Используется для решения задач ранжирования, классификации, популярен для задач структурированного прогнозного моделирования, регрессия табличных данных и др. Разработана Microsoft. Справочно: Повышение градиента — это мощный алгоритм машинного обучения.
- XGBoost — это оптимизированная распределенная библиотека повышения градиента (GBM, GBRT, GBDT) с открытым исходным кодом. Доступна для языков программирования C++, Java, Python, R, Julia, Perl и Scala. Работает на Linux, Windows и macOS. Код работает в распределенной среде (Hadoop, SGE, MPI) и может решать проблемы с миллиардами примеров. В последнее время он приобрел большую популярность и внимание как алгоритм выбора для команд-победителей соревнований по машинному обучению.
- VowpalWabbit — это библиотека машинного обучения для онлайн интерактивного обучения, разработанная в Yahoo. К разработке и развитию подключилась команда Microsoft Research. Используются методы: online, hashing, allreduce, reductions, learning2search, active and interactive learning.
- CatBoost — это высокопроизводительная библиотека с открытым исходным кодом для повышения градиента в деревьях решений. Библиотека разработана компанией Яндекс, использует одну из оригинальных схем градиентного бустинга (boosting — улучшение). Библиотека является преемником алгоритма MatrixNet, который широко используется в компании для ранжирования задач, прогнозирования и выработки рекомендаций.
- Hyperopt — это библиотека, в которой реализован алгоритм оптимизации Tree-Structured Parzen Estimators (TPE). Используется байесовская оптимизация для настройки параметров модели.
- fastText — это бесплатная, легковесная библиотека с открытым исходным кодом, которая позволяет пользователям изучать текстовые представления и классификаторы текста. Инструмент поддерживает несколько языков, включая английский, немецкий, испанский, французский, чешский и русский. Библиотека разработана в лаборатории Facebook AI Research (FAIR).
Python Web Frameworks — Веб-Разработка сайтов, микросервисов. Обзор фреймворков
- Django — это фреймворк для веб-приложений, работающий на Python, считается лучшим web-framework на языке Python. Фреймворки облегчают процесс разработки и позволяют разработчикам не изобретать колесо (в Django есть набор компонентов, которые можно использовать в своем проекте), поэтому создание сайта на Django можно сравнить с конструктором Lego. Django подходит для разработки высоконагруженных веб-приложений. Django следует философии «все включено», Вам только нужно найти нужный компонент для той или иной задачи.
- Flask — это легковесный и гибкий фреймворк, который используется для создания веб-приложений на языке Python. Flask реализуется с минимальными надстройками, позволяет выбирать модули под конкретные задачи и устанавливать их по мере необходимости. Вы вправе самостоятельно решить, как стоит реализовать те или иные вещи в вашем проекте. Flask стоит выбрать, если необходима тонкая настройка проекта. Flask из-за своей гибкости лучше подходит для создания REST API.
- Tornado — это веб-фреймворк Python и асинхронная библиотека для NetWorking (сетей). Используя неблокирующий сетевой ввод/вывод (I/O), Tornado может масштабироваться до десятков тысяч открытых соединений, что делает его идеальным для веб-сервисов реального времени (например для длинных опросов или long polling, WebSockets, т.е. которые требуют долгого соединения с каждым пользователем). Был создан для использования в проекте FriendFeed, который в 2009 году приобрела компания Facebook. После этого исходный код этой библиотеки разместили в открытом доступе. Есть интеграция с Amazon S3. Есть реализация сторонних схем аутентификации и авторизации (Google OpenID / OAuth, Facebook, Yahoo BBAuth, FriendFeed OpenID/OAuth, Twitter OAuth).
- Pyramid — это это самый молодой web-фреймворк Python с открытым исходным кодом для веб-проектов среди других популярных frameworks. Pyramid очень похожа на Flask (мало усилий для установки и запуска). Pyramid хорошо себя проявляет как в небольших, так и в больших проектах.
- Bottle — это быстрый, простой и легкий микро-фреймворк Python для небольших веб-приложений. Включает в себя диспетчеризацию запросов (маршрутизацию) с поддержкой параметров URL, шаблоны, имеет встроенный HTTP-сервер и адаптеры для сторонних WSGI/HTTP-серверов. Протокол WSGI — стандарт взаимодействия между Python-программой, выполняющейся на стороне сервера, и самим веб-сервером, например, Apache.
- CherryPy — это минималистичный объектно-ориентированный веб-фреймворк с открытым исходным кодом на языке Python. Является Pythonic. Спроектирован для быстрой разработки веб-приложений, используя ООП. CherryPy может быть настроек, как самостоятельный веб-сервер, или может работать под управлением другого серверного приложения, которое поддерживает протокол WSGI. CherryPy имеет собственный совместимый с HTTP веб-сервер WSGI.
Фреймворки для разработки мобильных приложений, GUI Development
- Kivy — это кросс-платформенный фреймворк Python с открытым исходным кодом для быстрой разработки межплатформенных В дополнение к стандартному вводу через клавиатуру и мышь он поддерживает мультитач. Kivy работает на Linux, Windows, OS X, Android, iOS и Raspberry Pi. Графика создается через OpenGL ES 2, что приводит к равномерному появлению в разных операционных системах.
- PyQt5 / PyQt4 / PyQt — это это библиотека Python для разработки приложений с графическим интерфейсом пользователя GUI (создано на основе набора кроссплатформенных библиотек C++). Является одной из самых мощных библиотек GUI (более 600 классов, более 6000 функций и методов). Библиотека доступна для Python 2.x и 3.x. PyQt работает на всех платформах, поддерживаемых Qt: Linux и другие UNIX-подобные ОС, Mac OS X и Windows. Существует 2 версии: PyQt5, поддерживающий Qt 5, и PyQt4, поддерживающий Qt 4.
- Tkinter — это бесплатная кросс-платформенная графическая библиотека Python, которая позволяет создавать программы с оконным интерфейсом (стандратный модуль Python для создания приложений с GUI интерфейсом). Tkinter является кроссплатформенной библиотекой и может быть использована в большинстве распространённых операционных систем (Windows, Linux, Mac OS X и др.). Функционирует на основе средств Tk (широко распространённая в мире GNU/Linux и других UNIX‐подобных систем, портирована также и на Microsoft Windows).
- WxPython — это это бесплатная кросс-платформенная библиотека Python для разработки приложений GUI (Windows, Mac OS X, Linux), поставляется вместе с Python и является альтернативой Tkinter. Библиотека написана на C++. Реализовано на основе wxWidgets — инструмент разработчика для написания настольных или мобильных приложений с графическим интерфейсом (GUI).
- PyGUI — это
- PySide — это
Фреймворки Python для разработки API
- Marchmallow — это библиотека, независимая от ORM/ODM/Framework для преобразования сложных типов данных, таких как объекты, в простые типы данных Python, а также обратная операция. Наиболее распространенное использование Marshmallow — десериализация объекта JSON в объект Python или сериализация объекта Python в объект JSON для использования в веб-API. Marshmallow делает это путем определения схемы, которую можно использовать для применения правил проверки десериализации данных или изменения способа сериализации данных.
- OpenAPI = спецификация. OpenAPI — это официальное название спецификации. Разработка спецификации поддерживается инициативой OpenAPI, в которой участвуют более 30 организаций из разных областей технического мира, включая Microsoft, Google, IBM и CapitalOne. Smartbear Software, которая является компанией, которая возглавляет разработку инструментов Swagger, также является участником инициативы OpenAPI, помогая вести эволюцию спецификации.
- Swagger = Инструменты для реализации спецификации. Swagger — это имя, связанное с некоторыми из самых известных и широко используемых инструментов для реализации спецификации OpenAPI. Набор инструментов Swagger включает в себя набор открытых, бесплатных и коммерческих инструментов, которые можно использовать на разных этапах жизненного цикла API. Инструменты Swagger — не единственные инструменты, доступные для реализации спецификации OpenAPI. Инструменты Swagger включают в себя:
- Редактор Swagger: Редактор Swagger позволяет редактировать спецификации OpenAPI в YAML внутри вашего браузера и просматривать документы в реальном времени.
- Swagger UI: Swagger UI — это набор ресурсов HTML, Javascript и CSS, которые динамически генерируют прекрасную документацию из OAS-совместимого API.
- Swagger Codegen: позволяет автоматически генерировать клиентские библиотеки API (SDK), заглушки серверов и документацию с учетом спецификации OpenAPI.
- Swagger Parser: автономная библиотека для анализа определений OpenAPI из Java
- Swagger Core: Java-библиотеки для создания, использования и работы с определениями OpenAPI
- Swagger Inspector (бесплатно): инструмент тестирования API, который позволяет проверять ваши API и генерировать определения OpenAPI из существующего API
- SwaggerHub (бесплатный и коммерческий): API-дизайн и документация, созданные для команд, работающих с OpenAPI.
- FastAPI — это это современная, быстрая (высокопроизводительная) веб-фреймворк для создания лаконичных и довольно быстрых HTTP API-серверов со встроенными валидацией, сериализацией и асинхронностью, работает с Python 3.6+. Работу с web в FastAPI выполняет Starlette, а валидацию — Pydantic. FastAPI интегрируется с OpenAPI-schema и автоматически генерирует документацию для API посредством Swagger и ReDoc.
Python Libraries for Game Development (Библиотеки Python для разработки игр)
- PyGame — это библиотека модулей/фреймворк Python для разработки 2D игр и мультимедиа-приложений. Pygame основывается на мультимедийной библиотеке SDL (Simple DirectMedia Layer — кроссплатформенная мультимедийная библиотека с открытым исходным кодом, которая реализует единый программный интерфейс для работы с графикой и анимацией, со звуком и музыкой, для работы с интерфейсами I/O — мышь, клавиатура, джойстик и т.д.). Pygame содержит функции и классы Python, которые позволяют вам использовать поддержку SDL.
- Pyglet — это кроссплатформенная библиотека окон и мультимедиа для Python, предназначенная для разработки игр и других мультимедийных приложений Windows, Mac OS X и Linux. Pyglet поддерживает работу с окнами, обработку событий пользовательского интерфейса, графику OpenGL, загрузку изображений и видео, а также воспроизведение звуков и музыки.
- PyOpenGL — это это большой пакет Python, который позволяет работать с функциями OpenGL, GLU, GLE и GLUT. PyOpenGL обеспечивает реализацию приложений с двухмерной и трехмерной графикой.
- Arcade — это простая в освоении библиотека Python для создания 2D видеоигр. Он идеально подходит для людей, которые учатся программировать, или для разработчиков, которые хотят написать двумерную игру, не изучая сложную структуру.
- Panda3D — это полностью бесплатный в использовании движок с открытым исходным кодом для создания 3D-игр, визуализаций, симуляций, экспериментов в реальном времени. Его богатый набор функций легко адаптируется к вашим рабочим процессам и потребностям разработки. Игровой движок включает в себя графику, звук, ввод/вывод, обнаружение и столкновение, а также другие функции, относящиеся к созданию 3D игр.
Python Libraries/Tools for Image Processing
Анализ изображений – это извлечение значимой информации из изображений. Что полезного можно получить из изображений?
- Медицина (выявление аномалий, диагностика заболеваний)
- Системы безопасности (обнаружение «подозрительных» предметов)
- Военная промышленность (системы слежения и целенаведения)
- Обнаружение и распознавание текста
Обзор инструментов:
- OpenCV (Open Source Computer Vision Library) — это библиотека алгоритмов компьютерного зрения с исходным кодом, для обработки изображений и видео, ориентирована на приложения реального времени. Реализована на C/C++, также разрабатывается для Python, Java, Ruby, Matlab, Lua и других языков. Библиотека opencv-python — неофициальный релиз пакетов OpenCV для Python.
- Mahotas — это библиотека компьютерного зрения и обработки изображений для Python, которая включает в себя множество алгоритмов, реализованных в C++ для повышения скорости при работе с большими массивами данных. Mahotas в настоящее время имеет более 100 функций для обработки изображений и компьютерного зрения и продолжает расти.
- SimpleITK (Insight Segmentation and Registration Toolkit, ITK) — это набор инструментов для анализа изображений с большим количеством компонентов, поддерживающих общие операции фильтрации, сегментации и регистрации изображений. Сам SimpleITK написан на C++, но доступен для большого количества языков программирования, включая Python.
- Pillow — это библиотека языка Python, предназначенная для работы с растровой графикой. Однако проект под названием Pillow, являющийся форком PIL, развивается и включает, в том числе, поддержку Python 3.x.
- SciKit-image — это библиотека Python, предназначенная для обработки изображений, включает в себя набор алгоритмов обработки изображений (сегментации, геометрических преобразований, управления цветовым пространством, анализа, фильтрации, морфологии, обнаружения признаков и многое другое). Библиотека доступна бесплатно и без ограничений.
Python Libraries For Text Analytics — библиотеки для анализа текста / NLP
Обработка написанных на естественном языке текстов (Natural Language Processing, NLP), с которой мы познакомились в предыдущей главе, и вычислительная лингвистика (Computational Linguistics, CL) — две сферы вычислительных методов изучения естественных языков.
NLP занимается разработкой методов решения связанных с языками практических задач, таких как извлечением информации, автоматическим распознаванием речи, машинным переводом, анализом тональности высказываний, формированием ответов на вопросы и автоматическим реферированием.
CL, с другой стороны, применяет вычислительные методы для постижения свойств естественных языков. Как мы понимаем язык? Как мы создаем языки? Как мы учим языки? Как различные языки связаны друг с другом?
- SpaCy — это open-source библиотека для NLP, написанная на Python и Cython. В отличие от NLTK, который широко используется для преподавания и исследований, spaCy фокусируется на предоставлении программного обеспечения для разработки. spaCy поставляется с предварительно обученными статистическими моделями и векторами слов, и в настоящее время поддерживает токенизацию для 50+ языков. В нем реализована современная скорость, сверточные модели нейронных сетей для тегирования, анализа и распознавания именованных объектов, а также простая интеграция с глубоким обучением. Это коммерческое программное обеспечение с открытым исходным кодом, выпущенное под лицензией MIT.
- NLTK (Natural Language Toolkit) — это библиотека для обработки естественного языка на Python, которая позволяет создавать программы для работы с данными на человеческом языке. NLTK доступен для Windows, Mac OS X и Linux. NLTK — это бесплатный проект с открытым исходным кодом, который поддерживает и развивает сообщество специалистов.
- Flair — это мощная библиотека NLP, которая позволяет применять современные модели обработки естественного языка (NLP) к тексту, такие как распознавание именованных объектов (NER), тегирование частей речи (PoS), устранение неоднозначности смысла и классификация.
- TextBlob — это библиотека Python (2 и 3) для обработки текстовых данных. Он предоставляет простой API для погружения в общие задачи обработки естественного языка (NLP), такие как определение части речи, извлечение имен существительных, анализ настроений, классификация, перевод и многое другое.
- Gensim — это библиотека для обработки естественного языка, с помощью которой осуществляют индексацию документов, моделирование тем, поиска сходства. Целевая область применения — это natural language processing (NLP) обработка естественного языка и information retrieval (IR) поиск информации.
- Наташа — это библиотека для извлечения структурированной информации из текстов на русском языке (например извлечения имён, адресов, дат, сумм денег и других сущностей). В библиотеке собраны грамматики и словари для парсера Yargy.
Инструментарий Python для автоматического тестирования
- Исследовательское тестирование (Exploratory Testing, ET). Объединяет тестовый дизайн и тестовое выполнение. Оно направлено на изучение приложения в условиях тестирования.
- Модульные тесты (Unit Test). Определяют поведение малых частей системы, например ветвей конкретных функций. Могут быть направлены на объект или метод, вытекающий из одного или нескольких дизайнерских решений. В контексте Agile автоматизированные модульные тесты направляют программирование на низшем уровне. Как правило, код модульных тестов составляет менее двенадцати строк. Некоторые специалисты предпочитают термин «микротест».
- Операционное тестирование (Operational Acceptance Testing, OAT). Используется для проведения OPS-подготовки (предвыпуска) продукта, услуги или системы как части контроля качества. OAT — стандартный тип нефункционального тестирования программного обеспечения, по большей части поддерживающий софт и проекты ПО.
- Приемочное тестирование (Acceptance Test). Тесты, определяющие бизнес-ценность и объемы каждой истории (функции). Могут определять как функциональные, так и нефункциональные требования, например, рабочие показатели или надежность. Хотя используются для разработки на основе примеров, представляют собой тесты высшего уровня, в отличие от модульных, используемых для создания кода в разработке на основе тестов. Это широкий термин, он может включать в себя бизнес-ориентированные и технологические тесты.
- Регрессионное тестирование (Regression Test). Определяет, что поведение системы в условиях тестирования не меняется. Регрессионные тесты часто пишутся как модульные, чтобы поддерживать программирование, или как приемочные, чтобы определять желаемое поведение системы. Как только проверка завершена, она становится частью набора регрессионных тестов, предотвращающих незапланированные изменения. Регрессионные тесты должны быть автоматизированы для обеспечения непрерывной обратной связи.
- Автотест (автоматизированный тест) – это скрипт, который имитирует взаимодействие бизнес-пользователя с приложением. Целью автотестов является локализация ошибок в работе системы/ПО. Конечная цель автоматического тестирования — создание набора автотестов, которые будут поочередно запускаться после нажатия на кнопку «Старт». Также должны быть предусмотрены одиночные автотесты для проверки отдельной функциональности. Каждый тестовый скрипт контролирует правильность работы определенной функциональности приложения (его части) и фиксирует ошибки, если что-то пошло не так.
Библиотеки Python для тестирования:
- Splinter — это инструмент с открытым исходным кодом для тестирования веб-приложений с использованием Python. Позволяет автоматизировать действия браузера, такие как посещение URL-адресов и взаимодействие с их элементами. Например, 1) Посетите веб-сайт Google, 2) Введите текст поиска, 3) Нажмите кнопку поиска, 4) Узнайте, находится ли сайт вашей компании в результатах поисковой выдачи. И т.д.
- Robot (Robot Framework) — это универсальная среда автоматизации с открытым исходным кодом. Он может быть использован для автоматизации тестирования и автоматизации процессов (RPA). Robot Framework активно поддерживается, и многие ведущие компании используют его при разработке программного обеспечения. Robot Framework имеет простой синтаксис, использующий удобочитаемые ключевые слова. Его возможности могут быть расширены библиотеками, реализованными на Python или Java.
- Behave — это behavior-driven (BDD) фреймворк для тестирования, который использует тесты, написанные в стиле естественного языка, подкрепленные кодом Python. Выдаёт красивые, аккуратные и понятные отчеты. Лучше всего подходит для тестирования «черного ящика». Лучше не использовать для модульного тестирования или низкоуровневого интеграционного тестирования.
- PyUnit (или unittest) — это framework для тестирования, входящий в стандартную библиотеку языка Python. Представляет собой версию JUnit на языке Python. Позволяет просто создавать программы модульного тестирования с помощью Python.
- PyTest — это фреймворк для тестирования, который позволяет легко писать небольшие тесты, а также масштабируется для поддержки сложного функционального тестирования приложений и библиотек. Это один из лучших инструментов, которые вы можете использовать для повышения производительности тестирования. Может запускать тесты параллельно. Может выполнить определенный тест или подмножество тестов.
Обзор других библиотек Python (работа со временем, оперативной системой, числами и т.д.)
- math — это модуль Python, который обеспечивает доступ к математическим функциям для работы с числами (набор функций для выполнения математических, тригонометрических и логарифмических операций и другие).
- time — это модуль Python, который предоставляет различные функции для работы со временем (смещение DST часового пояса, форматирование времени, делать задержки по таймеру и др.). Большинство функций, определенных в этом модуле, вызывают библиотечные функции платформы С с тем же именем.
- datetime — это модуль, который предоставляет классы для работы с датой и временем (формирование даты, вычисление разницы между двумя моментами времени, получение информации о временной зоне, получение текущего времени, получение даты из datetime, получение времени из datetime и др.).
- calendar — это модуль Python, который позволяет выводить календари (в виде простого текста или в HTML формате), а также предоставляет дополнительные полезные функции, связанные с календарем.
- os — это модуль, который предоставляет функции для работы с операционной системой. Модель содержит функции для работы с файлами, директориями, с переменными окружения, производить работу с путями, получать информацию об операционной системе и др.
- sys — это модуль, который предоставляет доступ к некоторым переменным и функциям для получения информации о взаимодействии интерпретатора Python с операционной системой. Модуль sys очень часто используют вместе с os модулем. С помощью sys можно получить такую информацию, как запущенная версия Питона, путь к интерпретатору Python, каталог установки Python, кодировка файловой системы, параметры командной строки и др.
- random — это модуль, который реализует генераторы псевдослучайных чисел для различных распределений (равномерного, нормального/гауссовского, логнормального, отрицательного экспоненциального, гамма- и бета-распределений).
- re — это модуль предоставляет операции сопоставления регулярных выражений (поиск с помощью «регулярных выражений» или с помощью текстовых «паттернов»/»patterns»). Другими словами это парсинг текста или поиск последовательностей символов, согласно заданным правилам, которые описываются в виде шаблонов.
- python-docx — это библиотека Python для создания и обновления/изменения файлов Microsoft Word (.docx).
- python-play — это модуль python, позволяющий воспроизводить аудиофайл в формате mp3.
- PyPDF2 — это библиотека PDF на чистом python, способная разбивать, объединять, обрезать и преобразовывать страницы файлов PDF. Он также может добавлять пользовательские данные, параметры просмотра и пароли к файлам PDF. Он может извлекать текст и метаданные из PDF-файлов, а также объединять файлы целиком.
Лучшие IDE (интегрированные среды разработки) и редакторы кода для Python
- IDLE (Integrated Development and Learning Environment) — это интегрированная среда разработки и обучения на языке Python, созданная с помощью библиотеки Tkinter. Это оболочка Python, окно для ввода команд на языке Python. В Windows это поставляется с интерпретатором Python, т.е. устанавливается вместе с Python.
- Jupyter Notebook — это веб-приложение с открытым исходным кодом, которое позволяет создавать и обмениваться документами, которые содержат живой код и результат его выполнения, уравнения, визуализации и текст с пояснениями по вычислениям. Часто используется для: очистки и преобразования данных, числового моделирования, статистического моделирования, визуализации данных, машинного обучения и др.
- Anaconda — дистрибутив языков программирования Python и R, включающий набор популярных свободных библиотек, объединённых проблематиками науки о данных и машинного обучения. Основная цель — поставка единым согласованным комплектом наиболее востребованных соответствующим кругом пользователей тематических модулей (таких как NumPy, SciPy, Astropy и других) с разрешением возникающих зависимостей и конфликтов, которые неизбежны при одиночной установке. По состоянию на 2019 год содержит более 1,5 тыс. модулей.
- PyCharm — это кросс-платформенная среда (Windows, MacOS, Linux) разработки для разных языков программирования (в частности для Python). PyCharm Community Edition (бесплатная версия) находится под лицензией Apache License, а PyCharm Professional Edition(платная версия) является проприетарным ПО. PyCharm предоставляет умную проверку кода, быстрое выявление ошибок и оперативное исправление, вкупе с автоматическим рефакторингом кода, и богатыми возможностями в навигации.
- Spyder — свободная и кроссплатформенная интерактивная IDE для научных расчетов на языке Python. Используется инженерами и аналитиками данных. Spyder является частью модуля spyderlib для Python, основанного на PyQt4, pyflakes, rope и Sphinx, предоставляющего мощные виджеты на PyQt4, такие как редактор кода, консоль Python (встраиваемая в приложения), графический редактор переменных (в том числе списков, словарей и массивов).
- Visual Studio Code — редактор кода, разработанный Microsoft для Windows, Linux и macOS. Позиционируется как «лёгкий» редактор кода для кроссплатформенной разработки веб- и облачных приложений. Включает в себя отладчик, инструменты для работы с Git, подсветку синтаксиса, IntelliSense (технология автодополнения Microsoft) и средства для рефакторинга. Имеет широкие возможности для кастомизации: пользовательские темы, сочетания клавиш, файлы конфигурации, имеет множество полезных плагинов. Распространяется бесплатно, разрабатывается как программное обеспечение с открытым исходным кодом, но готовые сборки распространяются под проприетарной лицензией.
- Thonny — интегрированная среда разработки для Python, специально разработанная для начинающих Pythonista. Поддерживает различные способы пошагового выполнения кода, пошаговое вычисление выражений, детальную визуализацию стека вызовов и режим объяснения концепций ссылок и кучи.
- Sublime Text — легковесный текстовый редактор для программистов. Поддерживает плагины на языке программирования Python. Разработчик позволяет бесплатно и без ограничений ознакомиться с продуктом, однако программа уведомляет о необходимости приобретения лицензии.
- Atom (с плагином atom-python-run) — бесплатный текстовый редактор с открытым исходным кодом для Linux, macOS, Windows с поддержкой плагинов, написанных на Node.js, и встраиваемых под управлением Git. Большинство плагинов имеют статус свободного программного обеспечения, разрабатываются и поддерживаются сообществом. Есть плагин для Python atom-python-run.
Синхронизация. Координация распределенных приложений
- ZooKeeper (Apache ZooKeeper) — это высокопроизводительный сервис координации для распределенных приложений; Служба, предназначенная для хранения конфигурационной информации, имён, выполнения распределённой синхронизации процессов. Фактически выполняет важнейшие задачи многих распределённых приложений. Является важной составляющей Hadoop-инфраструктуры, но может использоваться отдельно. Поддерживается Apache Foundation, написана на Java. Для получения информации каждый клиентский компьютер связывается с одним из серверов. ZooKeeper следит за синхронизацией всего кластера. Внедрение ZooKeeper делает ставку на высокую производительность, доступность и строго упорядоченный доступ. Аспекты производительности ZooKeeper позволяют использовать его в больших распределенных системах.
Реляционные базы данных (СУБД)
- MySQL — это
- PostgreSQL — это
NoSQL СУБД и Time-Series DataBase
- Redis (Remote Dictionary Server) — это база данных in-memory (хранимая в оперативной памяти) с исходным кодом (лицензиия BSD), которая хранится на диске. База данных организована по модели «ключ-значение», также можно использовать другие типы значений: строки, списки, наборы, отсортированные наборы, хэши, потоки, HyperLogLogs, растровые изображения. Redis обеспечивает время отклика на уровне долей миллисекунды и позволяет приложениям, работающим в режиме реального времени, выполнять миллионы запросов в секунду. Такие приложения востребованы в сфере игр, рекламных технологий, финансовых сервисов, здравоохранения и IoT.
- MongoDB — это кросс-платформенная, документоориентированная NoSQL система управления базами данных с открытым исходным кодом, не требующая описания схемы таблиц (schemaless). Написана на C++. Хранит данные в JSON-подобных документах, в основе БД лежит концепция коллекций и документов. Обеспечивает высокую производительность и лугкую масштабируемость. Документ — JSON-объект имеющий произвольное число полей. Коллекция (таблица)- однотипные документы хранятся в отдельной коллекции.База данных — набор коллекций. Используется в веб-разработке.
- CouchDB (Сluster Of Unreliable Commodity Hardware) — это документо-ориентированная NoSQL СУБД с открытым исходным кодом, написанная на языке Erlang, которая не требует описания схемы данных. CouchDB предоставляет REST интерфейс для работы с базой: Если мы хотим получить информацию — отправляем GET запрос, Если надо создать документ — POST, Необходимо что-то изменить — PUT, COPY для копирования, DELETE для удаления. Используется в веб-разработке.
- Cassandra — это распределенная гибридная NoSQL система управления БД, которая используется для создания высокомасштабируемых и надежных хранилищ огромных массивов данных, которые представлены в виде хэша. Cassandra разработана Facebook на языке Java, а затем СУБД передали для дальнейшего развития фонду Apache Software Foundation. Cassandra сочетает в себе модель хранения данных на базе семейства столбцов (ColumnFamily) с концепцией key-value (ключ-значение). Есть возможность организации хранения хэшей с несколькими уровнями вложенности. Относится к категории отказоустойчивых СУБД: помещённые в базу данные автоматически реплицируются на несколько узлов распредёленной сети или даже равномерно распределяются в нескольких дата-центрах, при сбое узла его функции на лету подхватываются другими узлами, добавление новых узлов в кластер и обновление версии Cassandra производится на лету, без дополнительного ручного вмешательства и переконфигурации других узлов.
- Neo4j — является ведущей в мире графовой системой управления базами данных с открытым исходным кодом, разработана на Java. Данные хранит в собственном формате, специализированно приспособленном для представления графовой информации. Программист работает с гибкой сетевой структурой узлов и отношений, а не со статическими таблицами.
- Clickhouse — это колоночная аналитическая система управления базами данных с открытым исходным кодом, разрабатывается компанией Yandex (Яндекс). Позволяет выполнять аналитические запросы в режиме реального времени на структурированных больших данных. ClickHouse использует собственный диалект SQL близкий к стандартному, но содержащий различные расширения: массивы и вложенные структуры данных, функции высшего порядка, вероятностные структуры, функции для работы с URI, возможность для работы с внешними key-value хранилищами («словарями»), специализированные агрегатные функции, функциональности для семплирования, приблизительных вычислений, возможность создания хранимых представлений с агрегацией, наполнения таблицы из потока сообщений Apache Kafka и т.д.
- VictoriaMetrics — это масштабируемая база данных временных рядов с открытым исходным кодом, которую можно использовать в качестве долгосрочного удаленного хранилища для Prometheus. Prometheus — это бесплатное программное приложение с открытым исходным кодом, используемое для мониторинга событий и оповещения. Он записывает метрики в реальном времени в базу данных временных рядов, построенную с использованием HTTP pull model, с гибкими запросами и оповещениями в реальном времени.
- InfluxDB — это база данных временных рядов с открытым исходным кодом, которая предназначена для обработки высокой нагрузки записей и запросов. Является частью стека TICK (Telegraf, InfluxDB, Chronograf, Kapacitor). Используется для IoT мониторинга и аналитики, мониторинга инфраструктуры и приложений.
WebSite Search Engine — механизм поиска для веб-сайта (поисковый движок)
- Elasticsearch — это масштабируемый поисковый движок корпоративного уровня с открытым исходным кодом, основанный на библиотеке Lucene (NoSQL с JSON REST API). Данные хранятся в формате JSON, система работает на платформе Java. Официальные клиенты доступны на Java, .NET (C#), PHP, Python, Apache Groovy, Ruby и многих других языках. Система обеспечивает полнотекстовый поиск и анализ данных.
- Sphinx — это высокоскоростная система для полнотекстового поиска, которую разработал Адрей Аксенов на языке C++. Система работает в Linux (RedHat, Ubuntu и т.д.), Windows, MacOS, Solaris, FreeBSD. Официальные реализации Sphinx API доступны для PHP, Java, Perl, Ruby и Python. Поисковый сервер Sphinx имеет двойную лицензию, поэтому он может быть лицензирован для коммерческой деятельности, а также свободно доступен для загрузки на официальном сайте (если он будет использоваться в соответствии с условиями GPL v.2).
- Solr — это платформа для полнотекстового поиска с открытым исходным кодом, написанная на Java и основана на проекте Apache Lucene. Её основные функции включают в себя полнотекстовый поиск, подсветка результатов, фасетный поиск, индексация в реальном времени, динамическую кластеризацию, интеграцию с базами данных, функции NoSQL, а также обработку документов Word, PDF и др. В основе Solr для реализации поиска и индексации лежит Lucene. Solr имеет HTTP/XML и JSON API, поэтому эту платформу можно использовать из всех популярных языков программирования.
- Xapian — это библиотека для полнотекстового поиска с открытым исходным кодом. Используется во многих ОС: Linux, MacOS, FreeBSD, NetBSD, OpenBSD, Solaris, IRIX, Windows. Может использоваться совместно с Perl, Python, PHP, Java, Tcl, C#, Ruby, Lua, Erlang, Node.js.
Workflow Management системы и Брокеры сообщений
- Apache Airflow — это open-source набор библиотек, платформа для планирования, создания и мониторинга рабочих процессов. Airflow является незаменимым инструментом для современного дата инженера как планировщик ETL/ELT-процессов, предназначен для запуска цепочек задач (data pipelines). Для создания рабочих процессов используется язык Python. Основные компоненты рабочего процесса Airflow: Направленные ациклические графы (DAG), Планировщик (Scheduler), Операторы (Operators), Задачи (Tasks).
- Kafka — это брокер сообщений, проект с открытым исходным кодом, используется для создания конвейеров данных в реальном времени и потоковых приложений. Масштабируется по горизонтали, используется паттерн Producer-Consumer, отказоустойчив. Разработана компанией LinkedIn на JVM стеке (Scala). Приложения (генераторы) посылают сообщения (записи) на узел Kafka (брокер), и указанные сообщения обрабатываются другими приложениями, так называемыми потребителями. Указанные сообщения сохраняются в теме, a потребители подписываются на тему для получения новых сообщений.
- Luigi — это пакет Python (поддерживаются версии 2.7, 3.6, 3.7 и выше), который помогает вам создавать сложные конвейеры пакетных заданий. С помощью Luigi производится управление рабочими процессами, управление зависимостями между задачами, имеется центральный планировщик задач с веб-интерфейсом, статусом выполнения задач и трекингом ошибок, CLI (есть возможность работы через командную строку), failover recovery. Разработан был инженерами из Spotify.
- Celery — это простая, гибкая и надежная распределенная система для обработки в асинхронном режиме огромного количества сообщений. Инструмент, который позволяет обрабатывать очередь задач, причем с акцентом на обработку в реальном времени, а также с поддержкой планирования задач. С помощью Celery можно запускать отложенный или выделенный код в отдельном процессе или даже на отдельном компьютере или сервере. Также Celery можно использовать для отправки электронных писем.
- RabbitMQ — это менеджер сообщений (message broker) на основе стандарта AMQP (тиражируемое связующее программное обеспечение, ориентированное на обработку сообщений). Создан на основе системы Open Telecom Platform, написан на языке Erlang, в качестве движка базы данных для хранения сообщений использует Mnesia. Состоит из сервера, библиотек поддержки протоколов HTTP, XMPP и STOMP[en], клиентских библиотек AMQP для Java и .NET Framework и различных плагинов. Если кратко, то это платформа, которая управляет очередью сообщений и к которой могут подключатся различные приложения и передавать/получать сообщения (т.е. предназначен для передачи данных между несколькими сервисами).
- ActiveMQ -это популярный многопротокольный сервер обмена сообщениями на основе Java с открытым исходным кодом. Он поддерживает стандартные отраслевые протоколы. Доступно подключение из C, C ++, Python, .Net и других языков программирования. Работает на основе протокола AMQP. Обмен сообщениями между веб-приложениями осуществляется с помощью STOMP через веб-сокеты. Также для работы с устройствами IoT используется MQTT. Обеспечивает «Enterprise Features», такие как кластеризация, хранение сообщений, с возможностью использовать различные базы данных, кэширование и ведение журналов. Написан на Java с полноценным клиентом Java Message Service (JMS).
- Kombu — это библиотека для работы с сообщениями на языке Python. Цель Kombu — максимально упростить обмен сообщениями в Python, предоставив высокоуровневый интерфейс для протокола AMQP, а также предоставить проверенные и проверенные решения для распространенных проблем обмена сообщениями. AMQP — это расширенный протокол очереди сообщений, открытый стандартный протокол для ориентации сообщений, организации очередей, маршрутизации, надежности и безопасности.
Система контроля версий
- Git — это бесплатная распределенная система контроля версий (управления версиями) с открытым исходным кодом, предназначенная для быстрой и эффективной работы с небольшими и очень крупными проектами. Хранилище истории разработки проектов, которое содержит в себе все версии его файлов (как текущие, так и старые неактуальные). Контроль версий означает что вы храните все версии редактируемых документов и можете вернуться к любой сохраненной версии в любой момент времени.
- Git-Flow — это набор расширений git предоставляющий высокоуровневые операции над репозиторием для поддержки модели ветвления Vincent Driessen.
Git Frameworks. Автоматизация CI/CD
- GitHub — это веб-платформа (облачный сервис по бизнес-модели SaaS), которая предлагает облачный хостинг Git (для контроля версий и совместной работы для разработчиков программного обеспечения). Microsoft, крупнейший участник GitHub, инициировала приобретение GitHub за 7,5 млрд долларов в июне 2018 года. GitHub был запущен в 2008 году и был основан на Git (системе управления открытым исходным кодом, созданная Линусом Торвальдсом для ускорения сборки программного обеспечения). GitHub это «социальная сеть для разработчиков». Участникам, кроме непосредственного хранения кода, своих проектов, можно общаться, комментировать изменения друг друга, отслеживать новости знакомых. У программистов есть возможность объединять репозитории и выводить вклад участника в виде дерева.
- BitBucket — это веб-сервис для хостинга GIT репозитория для контроля версий и совместной разработки проектов, основанный на системе контроля версий Mercurial и Git. Принадлежит Atlassian. Bitbucket предлагает как коммерческие планы, так и бесплатные аккаунты. Bitbucket интегрируется с другими программами Atlassian, такими как Jira, HipChat, Confluence и Bamboo. По назначению и основным предлагаемым функциям аналогичен GitHub. Основные преимущества GitHub лежат в области социализации программирования (social coding), Bitbucket больше ориентирован на небольшие закрытые команды разработчиков. Слоган сервиса — Bitbucket is the Git solution for professional teams («Bitbucket — это Git-решение для профессиональных команд»).
- GitLab — это веб-приложение на основе базы данных, так что его установка немного сложней, чем у некоторых других серверов git. GitLab помогает разработчикам вести непрерывный процесс развертывания для тестирования, создания и деплоя кода, следить за ходом тестов, повышать контроль над качеством, фокусирования на построении продукта вместо настройки инструментов. GitLab — веб-инструмент жизненного цикла DevOps с открытым исходным кодом, представляющий систему управления репозиториями кода для Git с собственной вики, системой отслеживания ошибок, CI/CD пайплайном и другими функциями. Код изначально был написан на Ruby, а некоторые его части были позже переписаны на Go.
- Jenkins — это система с открытым исходным кодом на Java, предназначенная для обеспечения процесса непрерывной интеграции программного обеспечения. Отсоединилась в 2008 году от проекта Hudson, принадлежащего компании Oracle, основным его автором был Косукэ Кавагути. Распространяется под лицензией MIT.
Создание образов, сборка и доставка контейнеров
- Docker — это программное обеспечение для автоматизации развертывания, быстрой разработки и тестирования приложений. Docker упаковывает ПО в стандартизованные блоки, которые называются контейнерами. Каждый контейнер включает все необходимое для работы приложения: библиотеки, системные инструменты, код и среду исполнения. Благодаря Docker можно быстро развертывать и масштабировать приложения в любой среде и сохранять уверенность в том, что код будет работать. Docker – это операционная система для контейнеров. Подобно тому как виртуальная машина создает виртуальное представление аппаратного обеспечения сервера (то есть устраняет необходимость непосредственно управлять таковым), контейнеры создают виртуальное представление серверной операционной системы. После установки на каждый сервер Docker предоставляет доступ к простым командам, необходимым для сборки, запуска или остановки контейнеров. Позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, который может быть перенесён на любую Linux-систему с поддержкой cgroups в ядре, а также предоставляет среду по управлению контейнерами.
- OpenShift — это открытая и расширяемая платформа приложений-контейнеров, которая позволяет использовать Docker и Kubernetes на предприятии. Разработано компанией RedHat. OpenShift включает в себя Kubernetes для оркестрации контейнеров и управления ими.
- Kubernetes (также известный как k8s или «kube») — это платформа оркестрации контейнеров с открытым исходным кодом, которая автоматизирует многие ручные процессы, связанные с развертыванием, управлением и масштабированием контейнерных приложений. Kubernetes является идеальной платформой для размещения облачных приложений, требующих быстрого масштабирования, таких как потоковая передача данных в реальном времени через Apache Kafka.
SQL Based Engines
- Apache Hive — это система управления базами данных на основе платформы Hadoop. Позволяет выполнять запросы, агрегировать и анализировать данные, хранящиеся в Hadoop. Apache Hive был создан корпорацией Facebook и передан под открытой лицензией в собственность фонду Apache Software Foundation. На сегодняшний день эта система используется компанией Netflix и доступна в Amazon Web Services через Amazon Elastic MapReduce. Hive определяет простой SQL-подобный язык запросов, называемый HiveQL (Hive Query Language), что позволяет пользователям, знакомым с SQL легко работать с запросами к данным.
- Apache Impala — это аналитическая база данных с открытым исходным кодом для Apache Hadoop. Impala обеспечивает быстрые интерактивные SQL-запросы непосредственно на ваших данных Apache Hadoop, хранящихся в HDFS, HBase или Amazon Simple Storage Service (S3). Apache Impala — это механизм SQL-запросов с открытым исходным кодом для массивно-параллельной обработки (MPP) данных, хранящихся в компьютерном кластере под управлением Apache Hadoop.
- Apache Spark – это Big Data фреймворк с открытым исходным кодом для реализации распределённой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop. В отличие от классического обработчика из ядра Hadoop, реализующего двухуровневую концепцию MapReduce с хранением промежуточных данных на накопителях, Spark работает в парадигме in-memory computing — обрабатывает данные в оперативной памяти, благодаря чему позволяет получать значительный выигрыш в скорости работы для некоторых классов задач, в частности, возможность многократного доступа к загруженным в память пользовательским данным делает библиотеку привлекательной для алгоритмов машинного обучения. Проект предоставляет программные интерфейсы для языков Java, Scala, Python, R. Изначально написан на Scala, впоследствии добавлена существенная часть кода на Java для предоставления возможности написания программ непосредственно на Java. Состоит из ядра и нескольких расширений, таких как Spark SQL (позволяет выполнять SQL-запросы над данными), Spark Streaming (надстройка для обработки потоковых данных), Spark MLlib (набор библиотек машинного обучения), GraphX (предназначено для распределённой обработки графов).
- Presto — это высокопроизводительный механизм распределенных SQL-запросов для Big Data (больших данных). Архитектура Presto позволяет пользователям отправлять запросы в различные источники данных, такие как Hadoop, AWS S3, Alluxio, MySQL, Cassandra, Kafka и MongoDB. Можно даже запросить данные из нескольких источников данных в рамках одного запроса. Presto — это программное обеспечение с открытым исходным кодом для сообщества, выпущенное по лицензии Apache.
Качество кода
- PIP8 — это
- code review — это
- code refactoring — это
JavaScript Инструменты
- Socket.IO — это JavaScript библиотека, которая обеспечивает двустороннюю и основанную на событиях связь между браузером и сервером в режиме реального времени. Состоит из двух частей: клиентской, которая запускается в браузере и серверной для node.js. Socket.IO главным образом использует протокол WebSocket, но если нужно, использует другие методы, например Adobe Flash сокеты, JSONP запросы или AJAX запросы. Может быть установлена через npm (node package manager).
- NodeJS — это среда выполнения кода на JavaScript, созданная на основе движка Chrome V8 JavaScript, который позволяет транслировать вызовы на языке JavaScript в машинный код. NodeJS превращает JavaScript из узкоспециализированного языка в язык общего назначения. Node.js добавляет возможность JavaScript взаимодействовать с устройствами ввода-вывода через свой API (написанный на C++), подключать другие внешние библиотеки, написанные на разных языках, обеспечивая вызовы к ним из JavaScript-кода. Node.js применяется преимущественно на сервере, выполняя роль веб-сервера, но есть возможность разрабатывать на Node.js и десктопные оконные приложения (при помощи NW.js, AppJS или Electron для Linux, Windows и macOS) и даже программировать микроконтроллеры (например, tessel, low.js и espruino). В основе Node.js лежит событийно-ориентированное и асинхронное (или реактивное) программирование с неблокирующим вводом/выводом.
- Express.js (или просто Express) — это быстрый, гибкий, минималистичный веб-фреймворк для приложений Node.js, реализованный как свободное и открытое программное обеспечение под лицензией MIT. Он спроектирован для создания веб-приложений и API. Де-факто является стандартным каркасом для Node.js. Express может являться backend’ом для программного стека MEAN, вместе с базой данных MongoDB и каркасом Vue.js, React или AngularJS для frontend’а.
- WebSocket — это протокол связи поверх TCP-соединения, предназначенный для обмена сообщениями между браузером и веб-сервером в режиме реального времени. Веб-сокеты (Web Sockets) — это передовая технология, которая позволяет создавать интерактивное соединение между клиентом (браузером) и сервером для обмена сообщениями в режиме реального времени. Веб-сокеты, в отличие от HTTP, позволяют работать с двунаправленным потоком данных. WebSocket — это своего рода канал связи, открытый в двух направлениях.
- Vue.js — open source JavaScript веб-фреймворк с открытым исходным кодом для создания пользовательских интерфейсов. Легко интегрируется в проекты с использованием других JavaScript-библиотек. Может функционировать как веб-фреймворк для разработки одностраничных приложений в реактивном стиле. С его помощью можно создавать динамические сайты и сложные одностраничные веб-приложения. Ядро фреймворка ориентировано на решение задач уровня представления, благодаря чему фреймворк несложно интегрировать в проекты совместно с дополнительными библиотеками и различными инструментами. В отличие от React.js, jQuery, AngularJS и других фреймворков, Vue.js достаточно прост для изучения. Но, как и с другими JS-фреймворками, потребуются знания основ CSS, HTML и JavaScript, поэтому советуем сначала изучить их.
- Vuex — это шаблон/паттерн управления состоянием + библиотека для приложений Vue.js. Vuex можно рассматривать как единый источник данных для всего приложения. Vuex — это библиотека управления состоянием, специально предназначенная для создания сложных крупномасштабных приложений Vue.js. Она использует глобальное централизованное хранилище для всех компонентов в приложении, используя преимущества собственной системы реактивности для мгновенных обновлений. Хранилище Vuex спроектировано таким образом, что невозможно изменить его состояние из какого-либо компонента. Это гарантирует, что состояние может быть изменено только предсказуемым образом. Таким образом, хранилище становится единственным источником истины: каждый элемент данных хранится только один раз и доступен только для чтения, чтобы предотвратить разрушение компонентами приложения состояния, к которому обращаются другие компоненты. Хранилище Vuex — реактивное.
- Vue-router — является официальным маршрутизатор для Vue.js. Он тесно интегрируется с ядром Vue.js, что позволяет без проблем создавать одностраничные приложения с Vue.js.
- React — это декларативная, эффективная и гибкая библиотека JavaScript с открытым исходным кодом для разработки пользовательских интерфейсов. React может использоваться для разработки одностраничных и мобильных приложений. Его цель — предоставить высокую скорость, простоту и масштабируемость. В качестве библиотеки для разработки пользовательских интерфейсов React часто используется с другими библиотеками, такими как MobX, Redux и GraphQL.
- Angular — это JavaScript-фреймворк с открытым исходным кодом, написанный на языке TypeScript и который разрабатывается командой из компании Google, а также сообществом разработчиков из различных компаний. Цель фреймворка — расширение браузерных приложений на основе MVC-шаблона, а также упрощение тестирования и разработки.
Траблшутинг
- Wireshark — программа-анализатор сетевых протоколов (трафика для компьютерных сетей). Имеет графический пользовательский интерфейс. Он позволяет вам видеть то, что происходит в вашей сети, на микроскопическом уровне и является стандартом де-факто (и часто де-юре) для многих коммерческих и некоммерческих предприятий, государственных учреждений и образовательных учреждений. Развитие Wireshark процветает благодаря добровольному вкладу сетевых экспертов по всему миру и является продолжением проекта, начатого Джеральдом Комбсом в 1998 году. Работает на Windows, Linux, macOS, Solaris, FreeBSD, NetBSD и многих других платформах. Имеется выгрузка данных (экспорт данных) в XML, PostScript, CSV или простой текст (txt).
- Strace — утилита для Linux, которая позволяет отследить выполнение системных вызовов (system call) и сигналов к ядру системы. Она используется для мониторинга и вмешательства во взаимодействие между процессами и ядром Linux, которое включает системные вызовы, доставку сигналов и изменения состояния процессов. Операция strace стала возможной благодаря функции ядра, известной как ptrace. Присутствует во многих дистрибутивах Linux по умолчанию. strace может использоваться для отправки багрепортов разработчикам.
- Procmon (Process Monitor) — это инструмент отслеживания для Windows. В режиме реального времени отображает активность файловой системы, реестра, а также процессов и потоков, включая расширенную и безвредную фильтрацию, всеобъемлющие свойства событий, такие как ID сессий и имена пользователей, достоверную информацию о процессах, полноценный стек потока со встроенной поддержкой всех операций, одновременный запись информации в файл и многие другие возможности. Эти уникальные возможности делают Process Monitor ключевым инструментом для устранения неполадок и избавления от вредоносных программ.
- gdb — это переносимый отладчик проекта GNU, который умеет производить отладку многих языков программирования, включая Си, C++, Free Pascal, FreeBASIC, Ada, Фортран, Python3, Swift, NASM и Rust. GDB можно подключить к VSCode и другим редакторам кода (Включая Vim, NeoVim, Emacs, Atom и др.). GDB может работать на большинстве популярных вариантов UNIX и Microsoft Windows, а также на Mac OS X.
- Syslog (system log — системный журнал) — это стандарт отправки и регистрации сообщений о происходящих в системе событиях (то есть создания событийных журналов), использующийся в компьютерных сетях, работающих по протоколу IP. Термином «syslog» называют как ныне стандартизированный сетевой протокол syslog, так и программное обеспечение (приложение, библиотеку), которое занимается отправкой и получением системных сообщений.
- Windows Event Log (Средство просмотра событий Windows) — отображает журнал приложений и системных сообщений, включая ошибки, информационные сообщения и предупреждения. Это полезный инструмент для устранения различных проблем Windows. Можно выгрузить журнал в текстовый файл.
BI — Business intelligence. Системы бизнес-аналитики
Ниже будут описаны 3 bi системы, по квадранту гартнера их можно упорядочить как:
- Power BI
- Tableau
- Qlik Sense
Из всех трех я бы однозначно отдал первенство Power BI, т.к. будем откровенны — ни одна компания в мире не обладает потенциалом, который есть у Microsoft для работы с данными компаний. По сути, Power BI родился из Excel, сервисов хранилищ данных Microsoft. Инструментарий очень богат, плюс есть огромное множество интеграций с другим софтом (Python, R и др.).
Tableau на втором месте по большей части из-за очень крутой визуализации.
Ну а Qlik Sense занимает третье место (по инерции), т.к. когда то был лидером квадранта и многие компании до сих пор используют это ПО. У меня есть опыт работы с Qlik Sense и хочу сказать, что мне сложно его отнести к лидерам BI инструментов, т.к. QlikTech развивает свою экосистему обработки данных в ущерб функционалу BI. Что несомненно сказалось на позициях Qlik Sense на рынке. Плюс QlikTech свернул свой бесплатный софт Qlik Sense Desktop, что несомненно негативно отразилось на настроениях специалистов.
- Power BI — это это платформа бизнес-аналитики (Business Intelligence), которая предоставляет инструменты для агрегирования, анализа, визуализации данных. Как правило все инструменты максимально адаптированы для нетехнических пользователей для построения аналитических панелей. В случае больших объемов данных или сложной логики приложений требуется более углубленный технический бэкграунд для создания приложений. С помощью Power BI Вы можете построить дашборд с нужными KPI по компании. Power BI состоит из настольного приложения Windows, которое называется Power BI Desktop (в нем Вы создаете само приложение), онлайн-служба SaaS под названием Power BI Service (туда публикуется приложение из Power BI Desktop), а также мобильное приложение Power BI, которое доступно для платформ iOS, Android и Windows.
- Tableau – BI-система интерактивной аналитики, которая позволяет в кратчайшие сроки проводить глубокий и разносторонний анализ больших массивов информации и не требующая обучения бизнес-пользователей и дорогостоящего внедрения. Tableau Online — это онлайн-сервис (функционал Tableau Desktop, но удаленно, в облаке), Tableau Prep — подготовка данных к работе в Tableau, Tableau Server — ПО для установки BI на серверах компании. Также имеется мобильное приложение.
- Qlik Sense — это платформа для анализа данных / система бизнес-аналитики (Business Intelligence), которая позволяет создавать аналитические приложения (агрегирование данных, визуализация). В отличии от Power BI, можно купить свой Enterprice сервер и поставить на сервер компании. У Power BI тоже такое есть, но вроде как за очень большие деньги (честно сказать деталей не знаю). По сравнению с Power BI больше подходит для технических пользователей. Загрузку данных нужно кодить, есть визуальные инструменты, но они более скудные по функционалу и возможностям. Хотя есть платные расширения VizLib, которые разрабатывает тот же QlikTech, но это уже за дополнительные деньги. Сервер внутри компании облегчает доступ к данным, т.к. не нужно весь массив данных компании выводить в онлайн (создавать онлайн хранилище, закачивать данные в облако и т.д.). Также Qlik Sense имеет очень мощный API, с полным доступом ко всем функциям платформы Qlik Sense. Но стоит заметить, что подобный функционал не нужен в 85% случаев. Возможно только если компания захочет сделать свой «космолет», который будет стоить очень больших денег на этапе эксплуатации.
Другие системы визуализации данных, которые можно использовать в своих проектах
- Prometheus — это
- Kibana — это
- Grafana — это
- Graphite — это
Принципы разработки программного обеспечения
- SOA (Service Oriented Architecture) — это модульный подход к разработке программного обеспечения, основанный на использовании распределённых, слабо связанных заменяемых компонентов, оснащённых стандартизированными интерфейсами для взаимодействия по стандартизированным протоколам. интеграции информационной инфраструктуры компании за счет построения архитектуры, позволяющей интегрировать с максимальной гибкостью разнородные приложения.
В основе SOA лежат принципы многократного использования функциональных элементов ИТ, ликвидации дублирования функциональности в ПО, унификации типовых операционных процессов, обеспечения перевода операционной модели компании на централизованные процессы и функциональную организацию на основе промышленной платформы интеграции.
С помощью SOA реализуются три аспекта ИТ-сервисов:
- Сервисы бизнес-функций,
- Сервисы инфраструктуры,
- Сервисы жизненного цикла.
- Архитектура SPA (Single-Page Application или одностраничные приложения) — тип веб-приложений, состоящие из одной страницы, на которых динамически обновляется контент, в зависимости от действий пользователей. При таком подходе разработки экономится время на повторную загрузку одних и тех же элементов (библиотек JS, стилей CSS, структуры сайта, меню и т.д.). По большей части этот подход реализуется за счет инструментов JavaScript (React.js, Angular.js, Vue.js и др.).
- Архитектура MPA (Multi-Page Application или многостраничные приложения) — в многостраничных приложениях каждая страница отправляет запрос на сервер и полностью обновляет все данные. Даже если эти данные небольшие. Таким образом тратятся ресурсы как сервера, так и браузера клиента на перерисовку одних и тех же элементов. Соответственно это сказывается на работоспособности сайта. Поэтому многие разработчики, для того чтобы повысить скорость и уменьшить нагрузку, используют комбинированный подход: сайт состоит из разных страниц (главная, корзина, категории товаров, информация и т.п.), но на каждой странице есть динамическая составляющая работы, например, на странице категории товаров при работе с фильтрами товары подгружаются/обновляются/фильтруются с помощью JavaScript (без перезагрузки всей страницы).
- Паттерн (Design Pattern — Шаблон проектирования) — многократно используемые архитектурные конструкции для решения известных и распространенных проблем проектирования программного обеспечения.
MVC, MVP и MVVM — три популярных шаблона проектирования в разработке программного обеспечения. - MVC — Model-View-Controller в веб-приложении: 1) Пользователь вводит URL-адрес, 2) Контроллер (Controller) получает этот запрос, 3) Контроллер использует Модель (Model) для получения всех необходимых данных, организует их, и пересылает их 4) Представлению (View), которое затем использует эти данные, чтобы отрисовать готовую страницу для пользователя в браузере. Т.е. Модель — это механизм общения с базой данных. Контролер — это функционал, который управляет последовательностью действий, принимает данные и передает их. View — отвечает за фронтэнд (frontend), то что видит пользователь.
- Паттерн MVP (Model-View-Presenter) — шаблон проектирования, производный от MVC, который используется в основном для построения пользовательского интерфейса. Состоит из 1) Модели (данные для отображения), 2) Вида/View (отображает данные из модели, обращается к Presenter), и 3) Представитель/Presenter (реализует взаимодействие между Моделью и Видом и содержит в себе всю бизнес-логику). По сути Presenter — это контроллер MVC, за исключением того, что он вообще не привязан к View, а просто взаимодействует с интерфейсом. Это решает проблемы тестируемости, а также проблемы модульности / гибкости, которые у нас были с MVC. Presenter сидят на одном уровне с View, слушая события как из View, так и из Model, и связывает действия между ними.
- Паттерн MVVM (Model-View-View Model) — модель, представление и третий компонент – дополнительная модель под названием ViewModel. MVVM позволяет нам создавать специфичные для View подмножества модели, которые могут содержать информацию о состоянии и логике, избегая необходимости представлять всю модель для представления. Шаблон MVVM поддерживает двустороннюю привязку данных между View и View-Model. Это позволяет автоматически распространять изменения внутри состояния View-Model на View.
И MVP, и MVVM являются производными от MVC. Основное различие между MVC и его производными заключается в зависимости каждого слоя от других уровней, а также от того, насколько тесно они связаны друг с другом.
MVP и MVVM лучше по сравнению с MVC, разбивают ваше приложение на модульные, специализированные компоненты, но они также увеличивают сложность вашего приложения. Для очень простого приложения с одним или двумя экранами MVC может работать очень хорошо. MVVM с привязкой данных привлекателен, поскольку он следует более реактивной модели программирования и требует меньше кода.
- ESB (Enterprise Service Bus «сервисная шина предприятия») — это концепция, элемент архитектуры IT-ландшафта, используемый для решения задачи интеграции разрозненных информационных систем в единый программный комплекс с централизованным управлением передачей информации и применением сервис-ориентированного подхода. Архитектура ESB строится на 3 компонентах: набор коннекторов, очередь сообщений, платформа. Архитектура ESB заключается во взаимодействии всех приложений через единую точку. При замене одного приложения, подключенного к шине, нет необходимости перенастраивать остальные.
- SOLID — принцип, за которым скрывается рекомендация следовать 5 базовым принципам ООП:
- Single Responsibility Principle (принцип единственности ответственности) — один класс отвечает за один функционал.
- Open/Closed Principle (принцип открытости/закрытости) — программные сущности должны быть открыты к расширению, но закрыты к изменению.
- Liskov Substitution Principle (принцип подстановки Барбары Лисков) — сущность, которая использует объект, реализующий определенный интерфейс, должна иметь возможность использовать другой объект с тем же интерфейсом, даже не зная об этом. Подклассы не могут замещать поведения базовых классов. Подтипы должны дополнять базовые типы.
- Interface Segregation Principle (принцип разделения интерфейса) — клиенты не должны зависеть от методов, которые они не используют. Слишком «толстые» интерфейсы необходимо дробить на более мелкие и специфические, чтобы клиенты маленьких интерфейсов знали только о методах, которые необходимы им в работе.
- Dependency Inversion Principle (принцип инверсии зависимостей) — Модули верхнего уровня не зависят от модулей нижнего уровня. И те, и другие должны зависеть от абстракций. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
- KISS («Keep It Simple, Stupid» или «Keep It Short and Simple«) — это принцип проектирования и программирования, согласно которому основной целью (ценностью) при разработке системы является её простота. Большинство систем работают лучше всего, если они остаются простыми, а не усложняются. Основная суть принципа: 1) нужно реализовывать только тот функционал, который необходим пользователю и описан в ТЗ, не нужно закладывать в проект избыточные функции «про запас». 2) не нужно делать реализацию сложной универсальной бизнес-логики под все варианты поведения системы (это невозможно и с коммерческой точки зрения не принесет выгоды). 3) не стоит подключать огромную библиотеку ради пары функций.
- DRY (Don’t Repeat Yourself) — не повторяйся. Принцип DRY известен также как DIE (Duplication Is Evil) — дублирование это зло. Принцип состоит в том, что нужно избегать использования одного и того же кода. Дубли кода лучше заменять на универсальные свойства и/или функции.
- YAGNI (You Aren’t Gonna Need It) — «Вам это не понадобится» — это принцип проектирования программ/систем, согласно которому в качестве главной цели (ценности) является отказ от избыточной функциональности, которая не заявлена заказчиком. Исходя из экономики проекта можно сделать вывод, что любые реализованные «фичи» были оплачены либо Заказчиком, либо Исполнителем. В одном случае это завышенный бюджет проекта, в другом случае это уменьшенная прибыль. Любые дополнительные фичи в дальнейшем усложняют эксплуатацию систем/программ/проектов, увеличивают количество ошибок и снижают понимание клиентом продукта. Есть такая поговорка «лучший код — это ненаписанный код». Помните, что ни одно гибкое решение никогда не будет достаточно гибким. При изменении входных параметров в системе что-то может «сломаться», испортится бизнес-логика и т.д.
- GRASP (General Responsibility Assignment Software Patterns) — это шаблоны, используемые в объектно-ориентированном проектировании для решения общих задач по назначению ответственностей классам и объектам. GRASP состоит из 5 основных и 4 дополнительных шаблонов.
- SoC (Separation of Concerns) — это принцип в области разработки программного обеспечения, суть которого заключается в следующем: не пишите свою программу как один сплошной блок, вместо этого разбивайте код на куски, которые представляют собой крошечные фрагменты системы, каждый из которых способен выполнить простую отдельную работу. Разделение ответственностей — это процесс разделения компьютерной программы на функциональные блоки, которые не будут перекрывать функции друг друга.
- 4C’s (Clean Code > Clever Code) — дословно означает «Чистый код -> Умный код». Отладка в два раза сложнее написания первоначального кода.
- SLAP (Single Level Of Abstraction) — это Принцип Единого Уровня Абстракции: Идея заключается в том, что в рамках определенного метода/функции мы должны стремиться сохранить весь код на одном уровне абстракции, чтобы легче было его читать. Весь смысл заключается в том, чтобы при чтении кода нам приходилось держать в голове меньше контекста о коде и мы могли просто прочитать код и быстро понять, что происходит. Раскладывайте длинные методы/функции на более короткие методы/функции, каждый из которых несет решает одну задачу и имеет четкое название, прочитав которое станет понятно, что функция делает.
Протоколы передачи финансовых данных
- FIX (Financial Information eXchange) — открытый стандарт передачи информации в электронном виде, который передает финансовую информации и автоматизации коммуникаций на фондовом рынке. Протокол не справлялся с возросшим объёмом финансовой информации, генерируемой на фондовом рынке. При передачи больших объёмов данных с помощью FIX возникали значительные задержки в их обработке, что приносило трейдерам убытки и лишало их возможности разработки действующих торговых стратегий. Поэтому в 2004 году было решено разработать новый протокол (FAST), целью которого было добиться возможности передачи больших объёмов данных, избегая появления задержек в получении информации.
- FAST (FIX Adapted for STreaming) — бинарный вариант протокола FIX, который был адаптирован для поточной передачи данных по сети. FAST позволяет в более компактном виде передавать большие объёмы информации о рыночных сделках, применяется в высокоскоростных торговых системах, требующих низких задержек передачи. Трейдеры могут получать по FAST таблицы финансовых инструментов (цены, объёмы торгов и т.п.), котировки, все сделки, индексы, а также информацию обо всех активных обезличенных заявках. Используется на многих мировых биржах, в том числе и на Московской бирже и Санкт-Петербургской бирже.
Архитектурные подходы к проектированию модели данных
- Kimball — это
- Inmon — это
- Data Vault — это
- Data Lake — это
ETL, ELT, Data Pipeline — термины по обработке данных
Что такое Data Pipeline или Конвейер данных?
Data Pipeline (Конвейер данных) — это программное обеспечение, которое исключает множество ручных шагов из процесса и обеспечивает плавный, автоматизированный поток данных от одной станции к другой. Data Pipeline начинается с определения того, какие данные, откуда и как собирать. Он автоматизирует процессы, связанные с извлечением, преобразованием, объединением, проверкой и загрузкой данных для дальнейшего анализа и визуализации. Конвейер данных обеспечивает сквозную передачу данных, устраняя ошибки, узкие места или задержки. Data Pipeline может обрабатывать несколько потоков данных одновременно. Короче говоря, это абсолютная необходимость для современного data-driven предприятия.
Конвейер данных рассматривает все данные как потоковые данные и обеспечивает гибкие схемы. Независимо от того, поступают ли они из статических источников (например, базы данных с плоскими файлами) или из источников в реальном времени (например, онлайн розничные транзакции), конвейер данных делит каждый поток данных на более мелкие порции, которые он обрабатывает параллельно, предоставляя дополнительную вычислительную мощность.
Конвейер данных не требует, чтобы конечным пунктом назначения было хранилище данных. Он может направлять данные в другое приложение, такое как инструмент визуализации или Salesforce. Думайте о Data Pipeline как об окончательной сборочной линии.
Чем конвейер данных отличается от ETL?
ETL расшифровывается как Extract, Transform и Load. Системы ETL извлекают данные из одной системы, преобразуют их и загружают в базу данных или хранилище данных. Устаревшие конвейеры ETL обычно работают в пакетном режиме, что означает, что данные перемещаются единым большим блоком в определенное время в целевое хранилище данных. Как правило, это происходит по заданному расписанию или через регулярные запланированные интервалы. Например, вы можете настроить запуск пакетов в 00:30 каждый день, когда нагрузка на системы учета (ERP, MES и т.д.) низкая.
«Конвейер данных» является более широким термином, который охватывает ETL как подмножество. Конвейер данных относится к системе для перемещения данных из одной системы в другую. Данные могут преобразовываться или не преобразовываться, и они могут обрабатываться в режиме реального времени (в потоковом режиме) вместо пакетного типа обработки. Кроме того, данные могут не загружаться в базу данных или хранилище данных. Конвейер данных может использоваться для разных целей: таких как корзина AWS (контейнеры для объектов) или озеро данных, или может запускать триггер в другой системе, например, для запуска определенного бизнес-процесса.
ETL и ELT
7 отличий ETL от ELT:
- ETL — это извлечение, преобразование и загрузка данных, а ELT — извлечение, загрузка и преобразование данных.
- В ETL данные перемещаются из источника данных в промежуточное хранилище (Data Staging) и затем в хранилище данных.
- ELT использует хранилище данных для базовых преобразований. Data Staging не требуется.
- ETL обеспечивает конфиденциальность данных (data privacy), производится очистка данных и их преобразования.
- ETL может выполнять сложные преобразования данных и может быть более рентабельным, чем ELT.
- ETL применяется для работы с хранилищами данных
- ELT применяется, когда необходимо создавать озера данных.
Извлечение (Extract): это выгрузка исходных данных из исходной базы данных или источника данных (API, Excel, txt, csv и т.д.). При использовании ETL данные попадают во временную промежуточную область. В ELT данные сразу попадают в систему хранения озера данных.
Преобразование (Transform): это процесс изменения структуры информации, поэтому оно интегрируется с целевой системой данных и остальными данными в этой системе.
Загрузка (Load): относится к процессу внесения информации в систему хранения данных.
Что такое ETL?
ETL (или Извлечение, Преобразование, Загрузка) — это сбор и обработка данных из различных источников в одно хранилище данных, где они могут быть проанализированы. Ваша компания имеет доступ ко многим источникам данных, но чаще всего эти данные представляются менее полезным для вас способом. Результаты этого анализа могут быть использованы для информирования ваших бизнес-стратегий и решений.
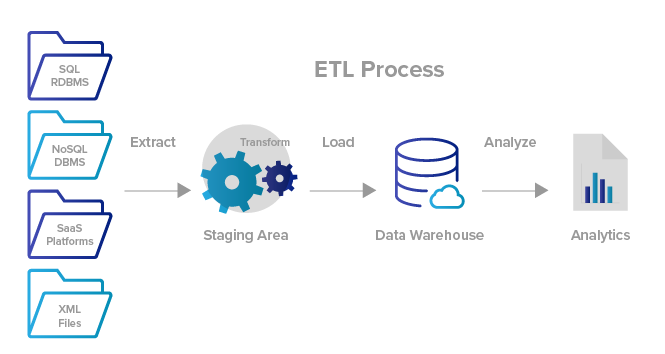
Что такое ELT?
ELT позволяет загрузить все данные немедленно, а пользователи могут позже определить, какие данные преобразовать и анализировать.
Для начала рассмотрим термин «Озера данных» — это особые виды хранилищ данных, которые, в отличие от хранилищ данных OLAP, принимают любые виды структурированных или неструктурированных данных. Озера данных не требуют от вас преобразования данных перед их загрузкой. Вы можете немедленно загрузить любую необработанную информацию в озеро данных, независимо от ее формата или отсутствия формата. Преобразование данных все еще необходимо, прежде чем анализировать данные с помощью платформы бизнес-аналитики. Однако очистка, обогащение и преобразование данных происходят после загрузки данных в озеро данных.
ELT — это относительно новая технология, которая стала возможной благодаря современным облачным серверным технологиям. ELT в сочетании с озером данных позволяет вам сразу же получать доступ к постоянно расширяющемуся пулу необработанных данных по мере их доступности. Основное преимущество ELT перед ETL связано с гибкостью и простотой хранения новых неструктурированных данных. С ELT вы можете сохранить любой тип информации — даже если у вас нет времени или возможности сначала преобразовать и структурировать ее — обеспечивая немедленный доступ ко всей вашей информации, когда вы этого хотите. Кроме того, вам не нужно разрабатывать сложные процессы ETL до поступления данных, что экономит время разработчиков и аналитиков BI при работе с новой информацией.
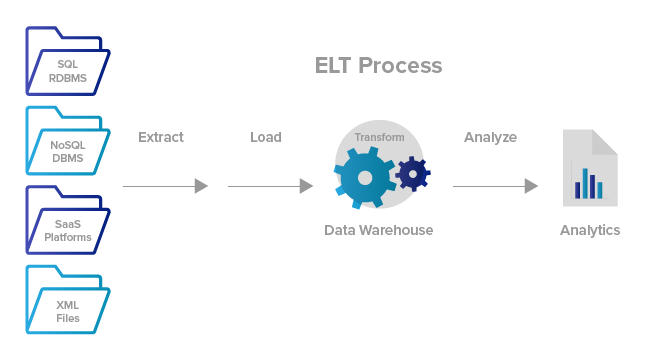
Управление данными
- Управление данными — общее управление доступностью, удобством использования, целостностью и безопасностью корпоративных данных. Это процесс создания согласованных и связанных слоев данных. Управление данными обеспечивает демократизацию данных, предоставляя целостное представление о постоянно расширяющейся вселенной данных для всех клиентов данных.
- Демократия данных — помогает всем, кому необходим доступ к аналитике данных в вашей компании, сократить крутые кривые обучения, задать правильные вопросы о данных и принять участие в процессе уточнения ответов.
Виды трансформации данных
- Дедупликация (нормализация) / Deduplication (normalizing): идентифицирует и удаляет дублирующую информацию.
- Перестройка ключей / Key restructuring: создание ключевых соединений одних таблиц с другими.
- Очистка / Cleansing: включает удаление старых, неполных и дублированных данных, чтобы максимизировать точность данных — путем анализа данных для удаления синтаксических ошибок, опечаток и фрагментов записей.
- Пересмотр формата / Format revision: преобразует форматы в разных наборах данных — таких как дата / время, мужчина / женщина и единицы измерения — в один согласованный формат.
- Деривация / Derivation: создает правила преобразования, которые применяются к данным. Например, может быть, вам нужно вычесть определенные затраты или налоговые обязательства из показателей доходов бизнеса, прежде чем анализировать их.
- Агрегирование / Aggregation: собирает и ищет данные, чтобы их можно было представить в виде сводного отчета.
- Интеграция / Integration: согласовывает различные имена / значения, которые применяются к одним и тем же элементам данных в хранилище данных, так что каждый элемент имеет стандартное имя и определение.
- Фильтрация / Filtering: выбирает определенные столбцы, строки и поля в наборе данных.
- Разделение / Splitting: разбивает один столбец на несколько столбцов.
- Присоединение / Joining: связывает данные из более чем одного источника, например, добавляет информацию о расходах на более чем одну платформу SaaS.
- Суммирование / Summarization: создает различные бизнес-показатели путем вычисления итоговых значений. Например, вы можете сложить все продажи, сделанные конкретным продавцом, чтобы создать метрики общих продаж за определенные периоды.
- Валидация / Validation: устанавливает автоматические правила, которым необходимо следовать при различных обстоятельствах. Например, если первые пять полей в строке имеют значение ПУСТО (NULL), вы можете пометить строку для исследования или запретить ее обработку с остальной информацией.
Системы мониторинга баз данных, IT-инфраструктуры
- Sentry — это
- ELK + elastalert — это
- Prometheus — это
- newrelic — это
- Kibana — это
- Grafana — это
- Zabbix — свободно распространяемая система универсального мониторинга любой IT инфраструктуры (сервисов компьютерной сети, серверов и сетевого оборудования), облачных ресурсов, сервисов и приложений, написанная Алексеем Владышевым. Для хранения данных используется MySQL, PostgreSQL, SQLite или Oracle Database, веб-интерфейс написан на PHP.
Системы/Приложения/Сервисы для проектирования пользовательских интерфейсов
- Balsamiq — это
- Axure — это
- Pencil — это
- Visio — это
- app.diagrams.net — это
Системы управления конфигурацией
- Ansible — это
Терминология для разработчика (независимо от языка программирования)
- DevOps. Термин, объединяющий разработку и эксплуатацию. Объединяет методы и шаблоны, способствующие налаживанию сотрудничества между специалистами команды разработчиков, направляет процесс разработки высококачественного программного обеспечения. Эти методы и шаблоны помогают командам писать пригодные для тестирования и поддержания кодов пакетные продукты, развертки и сохранять развертку кода.
- Выпуск продукта (Product Release). Выпуск продукта ПО может состоять из нового продукта или функций уже существующего. В контексте Agile функция может складываться из одной и более пользовательских историй.
- Продукт с минимальным функционалом (MVP) — продукт, который имеет достаточно ключевых функций, позволяющих делать развертку на небольшие группы потенциальных клиентов. Эти люди формируют часть цикла обратной связи build-measure-learn, или проверенного обучения, направляя дальнейшую разработку и принятие решений. Продукт с минимальным функционалом также используется для представления последних внесенных изменений, которые могут повысить его привлекательность для клиентов.
- Разработка на основе наборов (Set-based Development). В процессе разработки на основе наборов несколько специалистов или команд, независимо друг от друга, предлагают варианты решения проблемы. Заинтересованные стороны, представители бизнеса или другие участники процесса оценивают результаты и выбирают наиболее подходящий.
- Разработка на основе приемочного тестирования (Acceptance-Test-Driven Development, ATDD). Командам, занимающимся разработкой на основе приемочного тестирования, выполнимые тесты помогают определять примеры, полученные во время обсуждений работы с заказчиком. Каждый пример уточняется и представляется в выполнимом формате. Программисты при разработке функций используют тесты как руководство. Когда код написан, Тестирование может проводиться как автоматизированное регрессионное, документирующее поведение функций.
- Разработка через тестирование (Test-Driven Development, TDD). При разработке через тестирование программист, прежде чем написать минимальное количество кода, который позволит провести успешную проверку, создает и автоматизирует маленькие модульные тесты, которые изначально выдают ошибки. Код проходит рефакторинг для того, чтобы соответствовать стандартам. Производственный код написан так, чтобы пропускать по одному тесту за один раз. TDD также называют дизайном на основе тестов, поскольку этот процесс больше относится к методу написания кода, чем к тестированию, и помогает создать надежный, простой в обслуживании код.
- Разработка через поведение (Behavior-Driven Development, BDD). Примеры желаемого поведения, полученные от представителей заказчика, переводятся в выполнимые тесты в формате given_when_then. Программисты автоматизируют тесты, а затем пишут код для прохождения каждого из них. Разработка через поведение может быть использована на модульном уровне для дизайна на основе проверок и бизнес-ориентированных тестов, охватывающих множество компонентов и уровней приложения.
- Технический долг (Technical Debt). Когда команда разработчиков идет по пути наименьшего сопротивления и жертвует качеством ради того, чтобы бизнес мог воспользоваться ситуацией, они образуют долг в плохо спроектированном софте, не защищенном регрессионным тестированием или провисающем по другим качественным характеристикам. Если команда не находит времени, чтобы «выплатить» долг с помощью рефакторинга или добавления автоматизированных регрессионных тестов, разрабатывать новые функции становится сложнее, и «общий» долг замедляет работу команды.
- Унаследованная система (Legacy System). Система, не поддерживаемая автоматизированными регрессионными тестами. Внесение изменений в унаследованный код или его рефакторинг может представлять риски, поскольку не существует тестов, способных уловить незапланированные изменения в поведении системы.
- Legacy Code — это ценный код, доставшийся в наследство от предыдущих разработчиков, который Вы боитесь изменить, потому что не знаете, как внести изменения и при этом не нарушить существующее поведение системы или программы. Legacy code — тяжелая наследственность, устаревший код, который более не поддерживается и не обновляется, но используется.
- IaaS, PaaS и SaaS — это основные модели предоставления облачных услуг.
- Инфраструктура как сервис (Infrastructure as a Service, IaaS). Модель обслуживания, следуя которой организация использует облачные сервисы для поддержки эксплуатации, включая хранение данных, оборудование, серверы и сетевые компоненты. Сервисы принадлежат провайдеру, который отвечает за их размещение, работу и поддержку. Как правило, клиент платит по факту использования. В IaaS клиент получает только инфраструктуру. Пример: «виртуальный дата-центр» от Selectel или CloudLITE.
- Платформа как услуга (Platform-as-a-Service, Paas). Разновидность ПО как услуги. Модель предоставления услуг, позволяющая заказчику арендовать виртуальные серверы и сопутствующие услуги для работы существующих приложений или разработки новых. В PaaS — инфраструктуру и подготовленное для разработки приложений ПО. Пример: Облачная среда разработки Codenvy, Microsoft Azure или AWS.
- ПО как сервис (Software-as-a-Service, SaaS). В этой модели обслуживания подрядчик или провайдер самостоятельно размещает приложения. Вместо того, чтобы установить ПО на собственное оборудование (случай «ПО как продукт»), клиенты получают доступ к нему на серверах провайдера по сети, используя, как правило, подключение к интернету. В SaaS — готовое работающее в облаке приложение. Пример: amoCRM, Bitrix24, МойСклад, МангоТелеком и др.