
Содержание страницы
Keras Tutorial: Руководство для начинающих по глубокому обучению на Python 3
В этом пошаговом руководстве по Keras вы узнаете, как построить сверточную нейронную сеть на Python!
Фактически, мы будем обучать классификатор для рукописных цифр, который может похвастаться более чем 99% точностью в известном наборе данных MNIST.
Прежде чем мы начнем, мы должны отметить, что это руководство ориентировано на новичков, которые заинтересованы в прикладном глубокого изучения.
Наша цель — познакомить вас с одной из самых популярных и мощных библиотек для построения нейронных сетей на Python. Это означает, что мы разберем большую часть теории и математики, но мы также укажем вам на большие ресурсы для их изучения.
Вступительная часть по Keras Tutorial Python 3
Для начала изучения машинного обучения на Python с библиотекой Keras, желательно, чтобы Вы:
- Понимали основные концепции машинного обучения
- Имели навыки программирования на Python
Почему Keras?
Keras — рекомендуемая библиотека для глубокого изучения Python, особенно для начинающих. Его минималистичный, модульный подход позволяет с легкостью построить и запустить глубокие нейронные сети.
Типичные рабочие процессы Keras выглядят так:
- Определите ваши тренировочные данные: входной тензор и целевой тензор.
- Определите сеть слоев (или модель), которая отображает входные данные для наших целей.
- Настройте процесс обучения, выбрав функцию потерь, оптимизатор и некоторые показатели для мониторинга.
- Повторяйте данные тренировки, вызывая метод fit() вашей модели.
Что такое глубокое обучение?
Глубокое обучение относится к нейронным сетям с несколькими скрытыми слоями, которые могут изучать все более абстрактные представления входных данных. Это явное упрощение, но для нас это практическое определение для старта в этой дисциплине.
Например, глубокое обучение привело к значительным достижениям в области компьютерного зрения. Теперь мы можем классифицировать изображения, находить в них объекты и даже помечать их заголовками. Для этого глубокие нейронные сети со многими скрытыми слоями могут последовательно изучать более сложные функции из исходного входного изображения:
- Первые скрытые слои могут изучать только локальные контуры.
- Затем каждый последующий слой (или фильтр) изучает более сложные представления.
- Наконец, последний слой может классифицировать изображение как кошку или кенгуру.
Эти типы глубоких нейронных сетей называются сверточными нейронными сетями.
Что такое сверточные нейронные сети (Convolutional Neural Networks CNN)?
Короче говоря, сверточные нейронные сети (CNN) представляют собой многослойные нейронные сети (иногда до 17 или более слоев), которые предполагают, что входные данные являются изображениями.
Типичная архитектура CNN:
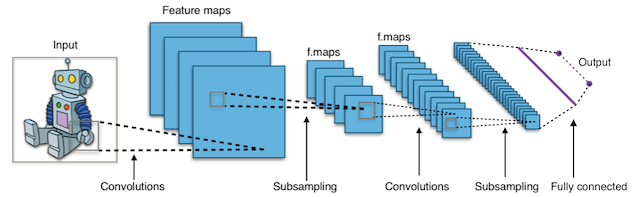
Удовлетворяя это требование, CNN могут резко сократить количество параметров, которые должны быть настроены. Следовательно, CNN могут эффективно справляться с высокой размерностью необработанных изображений.
Их основная механика выходит за рамки этого урока, но вы можете прочитать о них здесь.
Чем эта статья не является
Это не полный курс по глубокому обучению. Это руководство предназначено для того, чтобы перенести вас с нуля в вашу первую сверточную нейронную сеть с минимально возможной головной болью!
Если вы заинтересованы в овладении теорией глубокого обучения, мы рекомендуем этот замечательный курс из Стэнфорда:
О моделях Keras
В Keras доступно два основных типа моделей: последовательная модель и класс Model, используемый с функциональным API .
Эти модели имеют ряд общих методов и атрибутов:
model.layersэто плоский список слоев, составляющих модель.model.inputsсписок входных тензоров модели.model.outputsсписок выходных тензоров модели.model.summary()печатает краткое представление вашей модели.model.get_config()возвращает словарь, содержащий конфигурацию модели.model.get_weights()возвращает список всех весовых тензоров в модели в виде массивов Numpy.model.set_weights(weights)устанавливает значения весов модели из списка массивов Numpy. Массивы в списке должны иметь ту же форму, что и возвращаемыеget_weights().model.to_json()возвращает представление модели в виде строки JSON. Обратите внимание, что представление не включает веса, только архитектуру.model.to_yaml()возвращает представление модели в виде строки YAML. Обратите внимание, что представление не включает веса, только архитектуру.model.save_weights(filepath)сохраняет вес модели в виде файла HDF5.model.load_weights(filepath, by_name=False)загружает вес модели из файла HDF5 (созданногоsave_weights). По умолчанию ожидается, что архитектура не изменится.
Методы API последовательной модели (Sequential model API)
Компиляция — Compile
compile(
optimizer,
loss=None,
metrics=None,
loss_weights=None,
sample_weight_mode=None,
weighted_metrics=None,
target_tensors=None
)
Настраивает модель для обучения.
Аргументы:
- optimizer: строка (имя оптимизатора) или экземпляр оптимизатора.
- loss (потеря): строка (имя целевой функции) или целевая функция или
Lossэкземпляр. Смотрите потери. Если модель имеет несколько выходов, вы можете использовать разные потери на каждом выходе, передав словарь или список потерь. Значение потерь, которое будет минимизировано моделью, будет тогда суммой всех индивидуальных потерь. - metrics: список метрик, которые будут оцениваться моделью во время обучения и тестирования. Как правило, вы будете использовать
metrics=['accuracy']. Чтобы указать разные метрики для разных выходов модели с несколькими выходами, вы также можете передать словарь, напримерmetrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}. Вы также можете передать список (len = len (выводы)) списков метрик, таких какmetrics=[['accuracy'], ['accuracy', 'mse']]илиmetrics=['accuracy', ['accuracy', 'mse']]. - loss_weights: необязательный список или словарь, задающий скалярные коэффициенты (числа Python) для взвешивания вкладов потерь в различные выходные данные модели. Значение потерь, которое будет минимизировано моделью, будет затем взвешенной суммой всех индивидуальных потерь, взвешенных по
loss_weightsкоэффициентам. Если список, ожидается, что он будет иметь соотношение 1: 1 к выходам модели. Если это диктат, ожидается, что выходные имена (строки) будут сопоставлены скалярным коэффициентам. - sample_weight_mode: Если вам нужно сделать взвешивание выборки по временным шагам (2D веса), установите это значение
"temporal".Noneпо умолчанию используются веса выборки (1D). Если модель имеет несколько выходов, вы можете использовать разныеsample_weight_modeна каждом выходе, передав словарь или список режимов. - weighted_metrics: список метрик, которые будут оцениваться и взвешиваться по sample_weight или class_weight во время обучения и тестирования.
- target_tensors: по умолчанию Keras создаст заполнители для цели модели, которые будут снабжены целевыми данными во время обучения. Если вместо этого вы хотите использовать свои собственные целевые тензоры (в свою очередь, Keras не будет ожидать внешних данных Numpy для этих целей во время обучения), вы можете указать их с помощью
target_tensorsаргумента. Это может быть один тензор (для модели с одним выходом), список тензоров или точные сопоставления выходных имен с целевыми тензорами. - **kwargs: при использовании бэкэндов Theano / CNTK эти аргументы передаются в
K.function. При использовании бэкэнда TensorFlow эти аргументы передаются вtf.Session.run.
fit
Обучает модель для фиксированного числа эпох (итераций в наборе данных).
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose=1,
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
Аргументы:
- x: входные данные. Это может быть:
- Массив Numpy (или похожий на массив) или список массивов (в случае, если модель имеет несколько входов).
- Диктовое отображение (dict mapping) входных имен в соответствующий массив / тензоры, если модель имеет именованные входы.
- Генератор или
keras.utils.Sequenceвозвращение(inputs, targets)или(inputs, targets, sample weights). - None (default) — Нет (по умолчанию) при подаче из тензоров, встроенных в каркас (например, тензоры данных TensorFlow).
- y: целевые данные. Как и входные данные
x, это могут быть либо массив (ы) Numpy, тензор (ы), встроенные в платформу, список массивов Numpy (если модель имеет несколько выходных данных), либо None (по умолчанию), если они поступают из тензоров, встроенных в платформу (например, TensorFlow) тензоры данных). Если выходным слоям в модели присвоены имена, вы также можете передать словарь, отображающий выходные имена в массивы Numpy. Ifxявляется генератором илиkeras.utils.Sequenceэкземпляром,yуказывать не следует (поскольку цели будут получены изx). - batch_size: целое число или
None. Количество образцов на обновление градиента. Еслиbatch_sizeне указан, по умолчанию будет 32. Не указывайте,batch_sizeесли ваши данные представлены в виде символических тензоров, генераторов илиSequenceэкземпляров (так как они генерируют пакеты). - epochs: целочисленные. Количество эпох для обучения модели. Эпоха — это итерация по всему
xиyпредоставленным данным. Обратите внимание, что в сочетании сinitial_epoch,epochsследует понимать как «конечную эпоху». Модель не обучается для ряда итераций, заданныхepochs, а просто до тех пор, пока неepochsбудет достигнута эпоха индекса . - verbose: Integer. 0, 1 или 2. Режим многословия. 0 = тихий, 1 = индикатор выполнения, 2 = одна строка за эпоху.
- callbacks: список
keras.callbacks.Callbackэкземпляров. Список обратных вызовов, применяемых во время обучения и проверки (если). Смотрите обратные вызовы. - validation_split: с плавающей точкой от 0 до 1. Доля данных обучения, которые будут использоваться в качестве данных проверки. Модель выделит эту часть обучающих данных, не будет обучаться им и будет оценивать потери и любые метрики модели на этих данных в конце каждой эпохи. Данные проверки выбираются из последних выборок
xиyпредоставленных данных перед перетасовкой. Этот аргумент не поддерживается, когда онxявляется генератором илиSequenceэкземпляром. - validation_data:
данные для оценки потерь и любые метрики модели в конце каждой эпохи. Модель не будет обучаться на этих данных.
validation_dataперекроетvalidation_split.validation_dataможет быть: — кортеж(x_val, y_val)массивов или тензоров(x_val, y_val, val_sample_weights)Numpy — кортеж массивов Numpy — набор данных или итератор набора данныхДля первых двух случаев,
batch_sizeдолжны быть предоставлены. Для последнего случая,validation_stepsдолжны быть предоставлены. -
shuffle: Boolean (следует ли перемешивать данные тренировки перед каждой эпохой) или str (для «партии»). «пакетная» — это специальная опция для работы с ограничениями данных HDF5; он тасуется кусками размером с партию. Не имеет эффекта, когда
steps_per_epochнетNone. -
class_weight: необязательный словарь, отображающий индексы класса (целые числа) на значение веса (с плавающей запятой), используемое для взвешивания функции потерь (только во время обучения). Это может быть полезно для того, чтобы сказать модели «уделять больше внимания» выборкам из недопредставленного класса.
- sample_weight: необязательный массив весов Numpy для обучающих выборок, используемый для взвешивания функции потерь (только во время обучения). Вы можете либо передать плоский (1D) массив Numpy такой же длины, что и входные выборки (отображение весов и выборок 1: 1), либо в случае временных данных вы можете передать двумерный массив с формой
(samples, sequence_length), чтобы применить разный вес для каждого временного шага каждого образца. В этом случае вы должны обязательно указатьsample_weight_mode="temporal"вcompile(). Этот аргумент не поддерживается, когдаxгенератор илиSequenceэкземпляр вместо этого предоставляют sample_weights в качестве третьего элементаx. - initial_epoch: целое число. Эпоха, с которой начинается тренировка (полезно для возобновления предыдущего тренировочного заезда).
- steps_per_epoch: целое число или
None. Общее количество шагов (партий образцов) до объявления одной эпохи законченной и начала следующей эпохи. При обучении с использованием входных тензоров, таких как тензоры данных TensorFlow, значение по умолчаниюNoneравно числу выборок в вашем наборе данных, деленному на размер пакета, или 1, если это невозможно определить. - validation_steps: только релевантно, если
steps_per_epochуказано. Общее количество шагов (партий образцов) для проверки перед остановкой. - validation_steps: релевантно, только если
validation_dataпредоставлено и является генератором. Общее количество шагов (партий образцов), которые нужно нарисовать перед остановкой при выполнении проверки в конце каждой эпохи. - validation_freq: уместно, только если предоставлены данные проверки. Целое число или список / кортеж / набор. Если целое число, указывает, сколько тренировочных эпох должно быть выполнено до того, как будет выполнен новый прогон проверки, например,
validation_freq=2выполняет проверку каждые 2 эпохи. Если в списке, кортеже или наборе указываются эпохи, в которых нужно выполнять проверку, например,validation_freq=[1, 2, 10]выполняет проверку в конце 1-й, 2-й и 10-й эпох. - max_queue_size: целое число. Используется только для генератора или
keras.utils.Sequenceвхода. Максимальный размер очереди генератора. Если не указано, поmax_queue_sizeумолчанию будет 10. - workers: целое число. Используется только для генератора или
keras.utils.Sequenceвхода. Максимальное количество процессов, которые могут ускоряться при использовании потоков на основе процессов. Если не указан, поworkersумолчанию будет 1. Если 0, будет запускать генератор в основном потоке. - use_multiprocessing: Boolean. Используется только для генератора или
keras.utils.Sequenceвхода. ЕслиTrue, используйте процессные потоки. Если не указано, поuse_multiprocessingумолчаниюFalse. Обратите внимание, что, поскольку эта реализация опирается на многопроцессорность, вы не должны передавать невыгружаемые аргументы генератору, так как они не могут быть легко переданы дочерним процессам. - **kwargs: используется для обратной совместимости.
Краткий обзор учебника/статьи по Keras
Вот перечень шагов для создания вашей первой сверточной нейройнной сети (CNN) с использованием Keras:
- Настройте свою среду.
- Установите Керас / Keras.
- Импорт библиотек и модулей.
- Загрузить данные изображения из MNIST.
- Предварительная обработка входных данных для Keras.
- Метки препроцесс-класса для Keras.
- Определите архитектуру модели.
- Скомпилируйте модель.
- Подгонка модели по тренировочным данным.
- Оценить модель по данным испытаний.
Шаг 1: Настройте свою рабочую среду
убедитесь, что на вашем компьютере установлено следующее:
- Python 2.7+ (Python 3 тоже хорошо, но Python 2.7 все еще более популярен для науки о данных в целом)
- SciPy с NumPy
- Matplotlib (необязательно, рекомендуется для исследовательского анализа)
- Theano * ( Инструкция по установке )
Theano — это библиотека Python, которая позволяет нам так эффективно оценивать математические операции, включая многомерные массивы. В основном он используется при создании проектов глубокого обучения. Он работает намного быстрее на графическом процессоре (GPU), чем на CPU. Theano достигает высоких скоростей, что создает жесткую конкуренцию реализациям на языке C для задач, связанных с большими объемами данных.
Theano знает, как брать структуры и преобразовывать их в очень эффективный код, который использует numpy и некоторые нативные библиотеки. Он в основном предназначен для обработки типов вычислений, требуемых для алгоритмов больших нейронных сетей, используемых в Deep Learning. Именно поэтому, это очень популярная библиотека в области глубокого обучения.
Рекомендуется установить Python, NumPy, SciPy и matplotlib через дистрибутив Anaconda. Он поставляется со всеми этими пакетами.
Conda Cheatsheet: command line package and environment manager.pdf
Краткий обзор как настроить Анаконду здесь:
Инструкция по Anaconda & Conda. Как управлять и настроить среду для Python?
* Примечание: TensorFlow также поддерживается (как альтернатива Theano), но мы придерживаемся Theano для простоты. Основное отличие состоит в том, что вам необходимо изменить данные немного по-другому, прежде чем передавать их в свою сеть.
Еще раз пробежимся по устанавливаемым библиотекам:
SciPy (произносится как сай пай) — это пакет прикладных математических процедур, основанный на расширении Numpy Python. С SciPy интерактивный сеанс Python превращается в такую же полноценную среду обработки данных и прототипирования сложных систем, как MATLAB, IDL, Octave, R-Lab и SciLab.
Matplotlib — библиотека на языке программирования Python для визуализации данных.
Theano — библиотека, которая используется для разработки систем машинного обучения как сама по себе, так и в качестве вычислительного бекэнда для более высокоуровневых библиотек, например, Lasagne, Keras или Blocks.
NumPy — это библиотека языка Python, добавляющая поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых (и очень быстрых) математических функций для операций с этими массивами.
Проверим правильно ли мы все установили
Переходим в Jupyter Notebook в среде, которая имеет установленные библиотеки/пакеты. Запускаем следующие команды:
1. Для проверки среды:
import sys print(sys.version) print(sys.base_prefix)
Результата:
3.7.5 (default, Oct 31 2019, 15:18:51) [MSC v.1916 64 bit (AMD64)] C:\Users\User\.conda\envs\MyNewEnvironmentName
2. Для проверки библиотек:
import numpy as np
import theano as th
import keras as kr
import matplotlib as mpl
print('numpy:' + np.__version__)
print('theano:' + th.__version__)
print('keras:' + kr.__version__)
print('matplotlib:' + mpl.__version__)
Результат:
numpy:1.17.4 theano:1.0.4 keras:2.2.4 matplotlib:3.1.1
Как это выглядит в Jupyter Notebook:
Шаг 2. Импортируем библиотеки и модули для нашего проекта
Удаляем предыдущие проверочные шаги из Notebook.
Теперь начнем с импорта numpy и установки начального числа для генератора псевдослучайных чисел на компьютере. Это позволяет нам воспроизводить результаты из нашего скрипта:
import numpy as np np.random.seed(123) # for reproducibility
Далее мы импортируем тип модели Sequential из Keras. Это просто линейный набор слоев нейронной сети, и он идеально подходит для того типа CNN с прямой связью, который мы строим в этом руководстве.
from keras.models import Sequential
Далее, давайте импортируем «основные» слои из Keras. Это слои, которые используются практически в любой нейронной сети:
from keras.layers import Dense, Dropout, Activation, Flatten
Затем мы импортируем слои CNN из Keras. Это сверточные слои, которые помогут нам эффективно тренироваться на данных изображения:
from keras.layers import Convolution2D, MaxPooling2D
Наконец, мы импортируем некоторые утилиты. Это поможет нам преобразовать наши данные позже:
from keras.utils import np_utils
Теперь у нас есть все необходимое для построения архитектуры нейронной сети.
Полный текст скрипта после шага 2:
import numpy as np np.random.seed(123) # for reproducibility from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Convolution2D, MaxPooling2D from keras.utils import np_utils
Шаг 3. Загружаем изображения из MNIST
MNIST — отличный набор данных для начала глубокого обучения и компьютерного зрения. Это достаточно сложная задача, чтобы гарантировать нейронные сети, но она управляема на одном компьютере.
Библиотека Keras удобно уже включает это. Мы можем загрузить это так:
from keras.datasets import mnist # Load pre-shuffled MNIST data into train and test sets (X_train, y_train), (X_test, y_test) = mnist.load_data()
Мы можем посмотреть на форму набора данных:
print(X_train.shape)
Результат:
(60000, 28, 28)
Отлично, получается, что в нашем обучающем наборе 60 000 сэмплов, и размер каждого изображения составляет 28 х 28 пикселей. Мы можем подтвердить это, построив первый пример в matplotlib:
from matplotlib import pyplot as plt plt.imshow(X_train[0])
Вывод изображения:
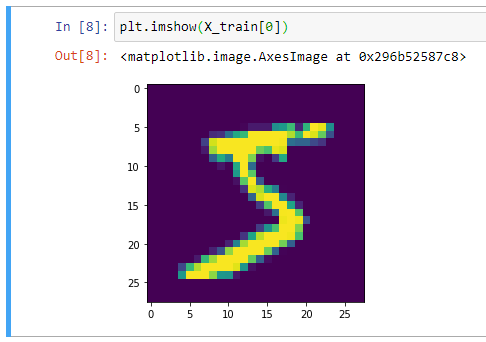
В целом, при работе с компьютерным зрением полезно визуально отобразить данные, прежде чем выполнять какую-либо работу алгоритма. Это быстрая проверка работоспособности, которая может предотвратить легко предотвратимые ошибки (например, неверную интерпретацию измерений данных).
Полный скрипт после шага 3
import numpy as np np.random.seed(123) # for reproducibility from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Convolution2D, MaxPooling2D from keras.utils import np_utils from keras.datasets import mnist from matplotlib import pyplot as plt # Загрузка предварительно перемешанных данных MNIST в наборы trains и tests (X_train, y_train), (X_test, y_test) = mnist.load_data() # Форма набора данных print(X_train.shape) # Вывод изображения plt.imshow(X_train[0])
Шаг 4: Предварительная обработка входных данных для Keras
При использовании бэкэнда Theano вы должны явно объявить размер для глубины входного изображения. Например, полноцветное изображение со всеми 3 каналами RGB будет иметь глубину 3.
Наши изображения MNIST имеют глубину только 1, но мы должны явно объявить это.
Другими словами, мы хотим преобразовать наш набор данных из формы (n, ширина, высота) в (n, глубина, ширина, высота).
Вот как мы можем сделать это легко:
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28) X_test = X_test.reshape(X_test.shape[0], 1, 28, 28)
Чтобы подтвердить, мы можем снова напечатать размеры X_train:
print(X_train.shape)
Результат:
(60000, 1, 28, 28)
Последний шаг предварительной обработки для входных данных — преобразовать наш тип данных в float32 и нормализовать наши значения данных в диапазоне [0, 1].
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Теперь наши входные данные готовы к обучению модели.
Полный текст скрипта после 4 шага
import numpy as np
np.random.seed(123) # для воспроизводимости
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
from keras.datasets import mnist
from matplotlib import pyplot as plt
# Загрузка предварительно перемешанных данных MNIST в наборы trains и tests
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Форма набора данных
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Вывод изображения
plt.imshow(X_train[0])
# Преобразование набора данных из формы (n, ширина, высота) в (n, глубина, ширина, высота)
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28)
# Вывод размеров X_train
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Преобразование типа данных в float32
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# Нормализация значений данных в диапазоне [0, 1]
X_train /= 255
X_test /= 255
Шаг 5. Предварительная обработка меток классов для Keras
Далее, давайте посмотрим на форму наших данных меток классов:
print(y_train.shape)
Результат:
(60000,)
Хм … это может быть проблематично. У нас должно быть 10 разных классов, по одному на каждую цифру, но, похоже, у нас есть только одномерный массив. Давайте посмотрим на ярлыки для первых 10 учебных образцов:
print(y_train[:10])
Результат:
[5 0 4 1 9 2 1 3 1 4]
И есть проблема. Данные y_train и y_test не разделены на 10 различных меток классов, а представлены в виде одного массива со значениями классов.
Мы можем это легко исправить:
# Convert 1-dimensional class arrays to 10-dimensional class matrices Y_train = np_utils.to_categorical(y_train, 10) Y_test = np_utils.to_categorical(y_test, 10)
Метод np_utils.to_categorical — Преобразует вектор класса (целые числа) в двоичную матрицу классов.
Теперь мы можем взглянуть еще раз:
print(Y_train.shape)
Результат:
(60000, 10)
Полный текст скрипта после 5 шага
import numpy as np
np.random.seed(123) # для воспроизводимости
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
from keras.datasets import mnist
from matplotlib import pyplot as plt
# Загрузка предварительно перемешанных данных MNIST в наборы trains и tests
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Форма набора данных
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Вывод изображения
plt.imshow(X_train[0])
# Преобразование набора данных из формы (n, ширина, высота) в (n, глубина, ширина, высота)
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28)
# Вывод размеров X_train
print("=== Результат X_train.shape ===")
print(X_train.shape)
# Преобразование типа данных в float32
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# Нормализация значений данных в диапазоне [0, 1]
X_train /= 255
X_test /= 255
# Просмотр формы меток классов наших данных
print("=== Результат y_train.shape ===")
print(y_train.shape)
print("=== Результат y_train[:10] ===")
print(y_train[:10])
# Преобразование одномерных массивов классов в 10-мерные матрицы классов
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
# Вывод после преобразования
print("=== Результат Y_train.shape после np_utils.to_categorical ===")
print(Y_train.shape)
Результат:
=== Результат X_train.shape === (60000, 28, 28) === Результат X_train.shape === (60000, 1, 28, 28) === Результат y_train.shape === (60000,) === Результат y_train[:10] === [5 0 4 1 9 2 1 3 1 4] === Результат Y_train.shape после np_utils.to_categorical === (60000, 10)
Шаг 6: Зададим архитектуру модели нейронной сети
Теперь мы готовы определить архитектуру нашей модели. В реальной научно-исследовательской работе исследователи потратят значительное количество времени на изучение архитектуру моделей.
Чтобы продолжать этот урок, мы не будем обсуждать здесь теорию или математику.
Когда вы только начинаете, вы можете просто воспроизвести проверенную архитектуру из академических работ или использовать существующие примеры. Вот список примеров реализации в Keras.
Начнем с объявления последовательного формата модели:
model = Sequential()
Далее мы объявляем входной слой:
model.add(Conv2D(32,(3, 3), activation = 'relu', input_shape=(1,28,28), data_format='channels_first'))
Входной параметр shape должен иметь форму 1 образца. В этом случае это то же самое (1, 28, 28), которое соответствует (глубина, ширина, высота) каждого изображения цифры.
Но что представляют собой первые 3 параметра? Они соответствуют количеству используемых фильтров свертки, количеству строк в каждом ядре свертки и количеству столбцов в каждом ядре свертки соответственно.
* Примечание. Размер шага по умолчанию равен (1,1), и его можно настроить с помощью параметра «subsample».
Мы можем подтвердить это, напечатав форму текущей модели:
print(model.output_shape)
Результат:
(None, 32, 26, 26)
Затем мы можем просто добавить больше слоев в нашу модель, как будто мы строим legos:
model.add(Conv2D(32, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25))
Опять же, мы не будем слишком углубляться в теорию, но важно выделить слой Dropout, который мы только что добавили. Это метод регуляризации нашей модели с целью предотвращения переоснащения. Вы можете прочитать больше об этом здесь .
MaxPooling2D — это способ уменьшить количество параметров в нашей модели, переместив фильтр пула 2×2 по предыдущему слою и взяв максимум 4 значения в фильтре 2×2.
Пока что для параметров модели мы добавили два слоя свертки. Чтобы завершить архитектуру нашей модели, давайте добавим полностью связанный слой, а затем выходной слой:
model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax'))
Для плотных слоев первым параметром является выходной размер слоя. Keras автоматически обрабатывает связи между слоями.
Обратите внимание, что конечный слой имеет выходной размер 10, соответствующий 10 классам цифр.
Также обратите внимание, что веса из слоев Convolution должны быть сплющены (сделаны одномерными) перед передачей их в полностью связанный плотный слой.
Вот как выглядит вся архитектура модели:
model = Sequential() model.add(Conv2D(32,(3, 3), activation = 'relu', input_shape=(1,28,28), data_format='channels_first')) model.add(Conv2D(32, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax'))
Теперь все, что нам нужно сделать, это определить функцию потерь и оптимизатор, и тогда мы будем готовы обучить ее.
Шаг 7. Скомпилируем модель
Сложная часть уже закончилась.
Теперь нам просто нужно скомпилировать модель, и мы будем готовы обучать ее. Когда мы компилируем модель, мы объявляем функцию потерь и оптимизатор (SGD, Adam и т.д.).
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Keras имеет множество функций потери и встроенных оптимизаторов на выбор.
Шаг 8. Обучим модель на тестовых данных (тренировочных данных)
Чтобы соответствовать модели, все, что нам нужно сделать, это объявить размер партии и количество эпох для обучения, а затем передать наши данные обучения.
model.fit(X_train, Y_train,
batch_size=32, epochs=10, verbose=1)
Результат:
Epoch 1/10 60000/60000 [==============================] - 38100s 635ms/step - loss: 0.2253 - acc: 0.9337 Epoch 2/10 60000/60000 [==============================] - 728s 12ms/step - loss: 0.1195 - acc: 0.9650 Epoch 3/10 60000/60000 [==============================] - 964s 16ms/step - loss: 0.0927 - acc: 0.9724 Epoch 4/10 60000/60000 [==============================] - 1169s 19ms/step - loss: 0.0778 - acc: 0.9768 Epoch 5/10 60000/60000 [==============================] - 1223s 20ms/step - loss: 0.0709 - acc: 0.9794 Epoch 6/10 60000/60000 [==============================] - 730s 12ms/step - loss: 0.0640 - acc: 0.9809 Epoch 7/10 60000/60000 [==============================] - 749s 12ms/step - loss: 0.0578 - acc: 0.9828 Epoch 8/10 60000/60000 [==============================] - 730s 12ms/step - loss: 0.0554 - acc: 0.9825 Epoch 9/10 60000/60000 [==============================] - 728s 12ms/step - loss: 0.0528 - acc: 0.9848 Epoch 10/10 60000/60000 [==============================] - 719s 12ms/step - loss: 0.0495 - acc: 0.9852
Вы также можете использовать различные обратные вызовы для установки правил ранней остановки, сохранения весов моделей по ходу дела или регистрации истории каждой эпохи обучения.
Шаг 9: Оценка работы модели на тестовых данных
Наконец, мы можем оценить нашу модель по тестовым данным:
score = model.evaluate(X_test, Y_test, verbose=0) score
Результат:
[2.3163251502990723, 0.0986]