
Содержание страницы
Что такое регулярное выражение? Для чего используется Regular Expressions в Python?
Регулярное выражение (Regular Expression, RegEx) — это мощный, гибкий и эффективный инструмент для сопоставления текста на основе заранее определенного шаблона. Т.е. регулярные выражения позволяют найти строки или наборы строк в тексте, используя специализированный синтаксис, с помощью которого описывается шаблон для поиска. Универсальные шаблоны регулярных выражений напоминают миниатюрный язык программирования, который предназначен для описания и разбора текста.
Почему регулярные выражения?
Давайте попробуем понять, почему нам следует использовать регулярные выражения для работы с текстом?
Вот несколько сценариев для работы с RegEx в Python:
- Data Mining: регулярное выражение — лучший инструмент для интеллектуального анализа данных. Он эффективно идентифицирует текст (строку, подстроку) в куче текста, проверяя его по заранее заданному шаблону. Некоторые распространенные сценарии — определение адреса электронной почты, URL-адреса или телефона из кучи текста.
- Data Validation (Проверка данных): регулярное выражение может идеально подойти для таких задач, как проверка данных. Он может включать в себя широкий спектр процессов проверки путем определения различных наборов шаблонов. Вот несколько примеров: проверка номеров телефонов, электронной почты и т.д.
Модуль Re (import re) — операции с регулярными выражениями
Python имеет встроенный пакет с именем re, который можно использовать для работы с регулярными выражениями.
Этот модуль предоставляет операции сопоставления регулярных выражений в Python, аналогичные тем, которые имеются в Perl. Основная функция модуля re — предложить поиск, в котором используются регулярное выражение и строка. Здесь он либо возвращает первое совпадение, либо ничего. Модуль re вызывает исключение re.error, если ошибка возникает при компиляции или использовании регулярного выражения.
Команда для импорта модуля re:
import re
Краткое описание синтаксиса RegEx на примере с Email
Для того, чтобы кратко познакомиться с Regular Expression, рассмотрим два примера и описание некоторых компонентов регулярного выражения.
Пример регулярного выражения для проверки email с пометкой каждого компонента:
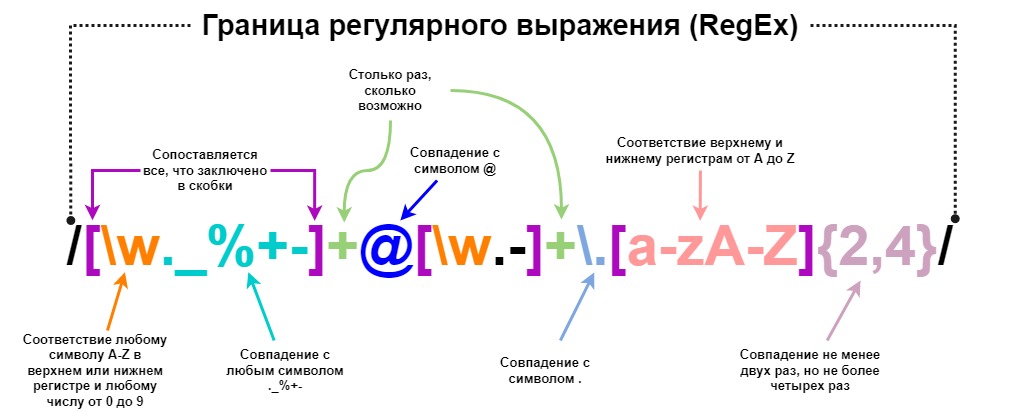
Еще один пример с почтой:

Описание некоторых общих компонентов регулярных выражений:
- Символ + в регулярном выражении означает «сопоставить предыдущий символ один или несколько раз». Например,
ab+cсоответствует «abc», «abbc», «abbbc», но не соответствует «ac» . Знак плюс, используемый в регулярном выражении, называется Клини плюс в честь математика Стивена Клини (1909–1994), который ввел эту концепцию. - Символ * в регулярном выражении означает «сопоставить предыдущий символ ноль или более раз». Например,
ab*cсоответствует «abc», «abbc», «abbbc» и «ac». Это называется звездой Клини. - Знак вопроса ? указывает на 0 или 1 вхождение предыдущего элемента. Например,
colou?rсоответствует как «color», так и «colour». - Точка соответствует любому одиночному символу (кроме символа новой строки). Например,
a.cсоответствует «abc», «adc», «aec» и т.д. Если мы хотим сопоставить несколько символов перед буквой «c», мы бы просто использовали звездочку*следующим образом:a.*cи это будет соответствовать «a bdefgh c». [a-z]: очень полезно, так как определяет диапазон возможных значений — относится ко всем строчным буквам алфавита от a до z. Мы можем сделать то же самое для букв верхнего регистра и всех положительных чисел, подобных этому[A-Z]&[0-9].^: Соответствует начальной позиции любой строки.[^b]atсоответствует всем строкам, за.atисключением «bat». Поэтому при использовании^в квадратных скобках следующая буква исключается.^[hc]atсоответствует «hat» и «cat», но только в начале строки.- \ Backspace экранирует точку, поэтому наше регулярное выражение не считает, что это часть наших квантификаторов, как определено выше. Нам нужно, чтобы точка была буквально частью нашего шаблона, поскольку она находится в нашем поисковом шаблоне.
Работа с модулем Re. Import re
RegEx в Python
Регулярные выражения — это, по сути, крошечный узкоспециализированный язык программирования, встроенный в Python и доступный через модуль re.
Используя этот небольшой язык, вы указываете правила для набора возможных строк, которые вы хотите сопоставить:
- этот набор может содержать английские предложения,
- или адреса электронной почты,
- или команды TeX,
- и т.д.
Затем вам необходимо задать такие вопросы, как «Соответствует ли эта строка шаблону?» или «Есть ли где-нибудь в этой строке совпадение с шаблоном?».
Модель RE также можно использовать для изменения строки или разделения ее на части различными способами.
Шаблоны регулярных выражений компилируются в серию байт-кодов, которые затем выполняются механизмом сопоставления, написанным на C определенным образом для создания байт-кода, который работает быстрее.
Язык регулярных выражений относительно мал и ограничен, поэтому не все возможные задачи обработки строк можно выполнить с помощью регулярных выражений. Есть также задачи, которые можно решить с помощью регулярных выражений, но выражения получаются очень сложными. В этих случаях вам может быть лучше написать код Python для обработки; в то время как код Python будет медленнее, чем сложное регулярное выражение, он также, вероятно, будет более понятным.
Вводный пример RegEx на Python
Когда вы импортировали re модуль, вы можете начать использовать регулярные выражения:
Пример — Проверим строку, что она начинается с ‘The’ и заканчивается ‘Spain’:
import re
#Check if the string starts with "The" and ends with "Spain":
txt = "The rain in Spain"
x = re.search("^The.*Spain$", txt)
if x:
print("YES! We have a match!")
else:
print("No match")
Результат:
YES! We have a match!
Функции RegEx
Регулярные выражения компилируются в объекты шаблонов, которые имеют методы для различных операций, таких как поиск совпадений с шаблоном или выполнение подстановки строк.
Модуль re предоставляет набор функций/методов, которые позволяют нам искать строку по совпадению:
- findall() — Возвращает список, содержащий все совпадения
- search() — Возвращает объект Match, если где-либо в строке есть совпадение
- split() — Возвращает список, в котором строка была разделена при каждом совпадении
- sub() — Заменяет одно или несколько совпадений строкой
- subn() — Делает то же самое, что и sub(), но возвращает новую строку и количество замен
- match() — Ищет совпадение с начала строки
- finditer() — Ищет все совпадения с
pattern, возвращает итератор - compile() — Компилирует regular expression, на выходе получаем объект, к которому затем можно применять все перечисленные функции
- fullmatch() — Проверяет, что вся строка соответствует описанному регулярному выражению
- flags (флаги) — Указываются в функциях, влияют на поведение регулярного выражения
Metacharacters (Метасимволы)
Метасимволы — это символы со специальным значением:
| Meta Character | Описание |
| […] | Набор символов |
| [^…] | Отрицательный класс символов. Соответствует любому символу, не заключенному в квадратные скобки |
| \ | Сообщает о специальной последовательности (также может использоваться для экранирования специальных символов) |
| . | Любой символ (кроме символа новой строки) |
| ^ | Начинается с |
| $ | Заканчивается на |
| * | Ноль или более случаев |
| + | Одно или несколько случаев |
| ? | Ноль или одно вхождение |
| {} | Ровно указанное количество вхождений |
| {n,m} | Соответствует не менее «n», но не более «m» повторений предыдущего символа. |
| | | Чередование. Соответствует символам до или после символа | |
| () | Захват и группировка |
| (xyz) | Группа символов. Соответствует символам xyz именно в этом порядке. |
Special Sequences RegEx (Специальные последовательности)
Специальная последовательность — это когда за символом \ следует один из символов в списке ниже, которая имеет особое значение:
| Character | Описание |
| \A | Возвращает совпадение, если указанные символы находятся в начале строки |
| \b | Возвращает совпадение, в котором указанные символы находятся в начале или в конце слова |
| \B | Возвращает совпадение, в котором указанные символы присутствуют, но НЕ в начале (или в конце) слова |
| \d | Возвращает совпадение, в котором строка содержит цифры (числа от 0 до 9) |
| \D | Возвращает совпадение, в котором строка НЕ содержит цифр |
| \s | Возвращает совпадение, в котором строка содержит символ пробела |
| \S | Возвращает совпадение, в котором строка НЕ содержит пробела |
| \w | Возвращает совпадение, в котором строка содержит любые символы слова (символы от a до Z, цифры от 0 до 9 и символ подчеркивания _ ) |
| \W | Возвращает совпадение, в котором строка НЕ содержит символов слова |
| \Z | Возвращает совпадение, если указанные символы находятся в конце строки |
Sets (Наборы)
Set (Набор) — это набор символов внутри пары квадратных скобок [] со специальным значением:
| Set | Описание |
| [arn] | Возвращает совпадение, в котором присутствует один из указанных символов (a, r или n) |
| [a-n] | Возвращает совпадение для любого символа нижнего регистра в алфавитном порядке от a до n |
| [^arn] | Возвращает совпадение для любого символа, ЗА ИСКЛЮЧЕНИЕМ a, r и n |
| [0123] | Возвращает совпадение, в котором присутствует любая из указанных цифр (0, 1, 2 или 3) |
| [0-9] | Возвращает совпадение для любой цифры от 0 до 9 |
| [0-5][0-9] | Возвращает совпадение для любых двузначных чисел от 00 до 59 |
| [a-zA-Z] | Возвращает соответствие для любого символа в алфавитном порядке от a до z, в нижнем регистре ИЛИ в верхнем регистре |
| [+] | В наборах + * . | () $ {} знак не имеет особого значения, поэтому [+] означает: вернуть совпадение для любого символа + в строке |
Символ \ — бэкслеш в Python RegEx
Регулярные выражения используют символ обратной косой черты (‘\’) для обозначения специальных форм или для разрешения использования специальных символов без обращения к их особому значению. Это противоречит тому, что Python использует тот же символ для той же цели в строковых литералах.
Допустим, вы хотите написать RE, который соответствует строке \section, которая может быть найдена в файле. Чтобы понять, что писать в программном коде, начните с нужной строки для сопоставления. Затем вы должны экранировать обратную косую черту и другие метасимволы, предваряя их обратной косой чертой, в результате чего получится строка \\section.
Результирующая строка, которую необходимо передать, re.compile() должна быть \\section. Однако, чтобы выразить это как строковый литерал Python, обе обратные косые черты должны быть снова экранированы.
| Символы | Этап |
|---|---|
\section |
Текстовая строка для сопоставления |
\\section |
Экранированная обратная косая черта для re.compile() |
"\\\\section" |
Экранированные символы обратной косой черты для строкового литерала |
Решение состоит в том, чтобы использовать для регулярных выражений нотацию необработанных строк Python. Обратная косая черта не обрабатывается каким-либо особым образом в строковом литерале с префиксом ‘r’:
r"\\section"
Регулярные выражения часто записываются в коде Python с использованием этой записи необработанных строк:
| Regular String | Raw string |
|---|---|
"ab*" |
r"ab*" |
"\\\\section" |
r"\\section" |
"\\w+\\s+\\1" |
r"\w+\s+\1" |
Проверка и тестирование регулярных выражений
- https://regex101.com/ — интерактивная консоль регулярных выражений, которая позволяет отлаживать выражения в режиме реального времени. Это означает, что вы можете создавать свои выражения и одновременно видеть, как они влияют на набор данных в реальном времени на одном экране. Инструмент был создан Фирасом Дибом при участии многих других разработчиков. Это крупнейший сервис тестирования регулярных выражений в мире.
- http://www.pyregex.com/ — онлайн-тестер регулярных выражений для проверки правильности регулярных выражений в подмножестве регулярных выражений языка Python.
- https://pythex.org/ — Pythex is a real-time regular expression editor for Python, a quick way to test your regular expressions.
Функция findall()
Определение функции
Функция findall() возвращает список, содержащий все совпадения.
Модуль findall() используется для поиска «всех» вхождений, соответствующих заданному шаблону. Напротив, модуль search() вернет только первое вхождение, соответствующее указанному шаблону. findall() перебирает все строки файла и возвращает все непересекающиеся совпадения шаблона за один шаг.
Синтаксис
re.findall(pattern, string, flags=0)
Пример использования
Функция search()
Определение функции
Функция search() будет искать шаблон регулярного выражения и возвращать первое вхождение. В отличие от Python match(), он проверяет все строки входной строки. Функция Python search() возвращает объект соответствия, когда шаблон найден, и «ноль», если шаблон не найден.
Синтаксис
re.search(pattern, string, flags=0)
Пример использования
туду
Функция split()
Определение функции
Функция split() работает аналогично методу split в строках, но в функции re.split можно использовать регулярные выражения, а значит, разделять строку на части по более сложным условиям.
Синтаксис
re.split(pattern, string, maxsplit=0, flags=0)
Пример использования
туду
Функция sub()
Определение функции
Функция re.sub работает аналогично методу replace в строках. Но в функции re.sub можно использовать регулярные выражения, а значит, делать замены по более сложным условиям.
Синтаксис
re.sub(pattern, repl, string, count=0, flags=0)
Пример использования
туду
Функция subn()
Определение функции
Функция subn() аналогична sub(), но возвращает новую строку и количество произведенных замен.
Синтаксис
re.subn(pattern, repl, string, count=0, flags=0)
Пример использования
туду
Функция match()
Определение функции
Функция re.match() re в Python будет искать шаблон регулярного выражения только в начале строки. Функция match() возвращает объект соответствия, если часть начала строки подпадает под шаблон, иначе функция вернет None.
Синтаксис
re.match(pattern, string, flags=0)
Пример использования
туду
Функция fullmatch()
Определение функции
Функция re.fullmatch() вернет объект сопоставления, если вся исходная строка соответствует шаблону Regular Expression.
Синтаксис
re.fullmatch(pattern, string, flags=0)
Пример использования
туду
Функция compile()
Определение функции
В Python есть возможность заранее скомпилировать регулярное выражение, а затем использовать его. Это особенно полезно в тех случаях, когда регулярное выражение много используется в скрипте.
Использование компилированного выражения может ускорить обработку, и, как правило, такой вариант удобней использовать, так как в программе разделяется создание регулярного выражения и его использование. Кроме того, при использовании функции re.compile создается объект RegexObject, у которого есть несколько дополнительных возможностей, которых нет в объекте MatchObject.
Синтаксис
re.compile(pattern, flags=0)
Пример использования
туду
Функция finditer()
Определение функции
Метод finditer() используется для поиска всех непересекающихся совпадений в шаблоне и возвращает итератор с объектами Match (finditer возвращает итератор даже в том случае, когда совпадение не найдено). Функция finditer отлично подходит для обработки тех команд, вывод которых отображается столбцами.
Синтаксис
re.finditer(pattern, string, flags=0)
Пример использования
туду
Match Object
Определение
Match Object — это объект, содержащий информацию о поиске и результате.
Объект Match имеет свойства и методы, используемые для получения информации о поиске и результате:
.span()возвращает кортеж, содержащий начальную и конечную позиции совпадения..stringвозвращает строку, переданную в функцию,.group()возвращает часть строки, в которой произошло совпадение
Flags (флаги)
Определение Flags
туду
Примеры решения задач с помощью модуля Re
туду
Подборка видео по теме «Regular Expressions в Python»
Не бойтесь регулярных выражений. Regex за 20 минут!
Python для Начинающих — Регулярные Выражения
Часть 1
Часть 2
Python с нуля. Регулярные выражения
Часть 1
Часть 2