
Содержание страницы
Что такое Pandas DataFrame?
Pandas — более новый пакет, надстройка над библиотекой NumPy, обеспечивающий эффективную реализацию класса DataFrame.
Объекты DataFrame — многомерные массивы с метками для строк и столбцов, а также зачастую с неоднородным типом данных и/или пропущенными данными.
Помимо удобного интерфейса для хранения маркированных данных, библиотека Pandas реализует множество операций для работы с данными хорошо знакомых пользователям фреймворков баз данных и электронных таблиц.
Импорт библиотек NumPy и Pandas
На самом примитивном уровне объекты библиотеки Pandas можно считать расширенной версией структурированных массивов библиотеки NumPy, в которых строки и столбцы идентифицируются метками, а не простыми числовыми индексами. Библиотека Pandas предоставляет множество полезных утилит, методов и функциональности в дополнение к базовым структурам данных, но все последующее изложение потребует понимания этих базовых структур. Позвольте познакомить вас с тремя фундаментальными структурами данных библиотеки Pandas: классами Series, DataFrame и Index.
Начнем наш сеанс программирования с обычных импортов библиотек NumPy и Pandas:
import numpy as np import pandas as pd
Объект Series библиотеки Pandas
Объект Series библиотеки Pandas — одномерный массив индексированных данных. Его можно создать из списка или массива следующим образом:
import numpy as np import pandas as pd data = pd.Series([0.25, 0.5, 0.75, 1.0]) print(data)
Результат:

Как мы видели из предыдущего результата, объект Series служит адаптером как для последовательности значений, так и последовательности индексов, к которым можно получить доступ посредством атрибутов values и index. Атрибут values представляет собой массив NumPy:
import numpy as np import pandas as pd data = pd.Series([0.25, 0.5, 0.75, 1.0]) print(data.values)
Результат:
[0.25 0.5 0.75 1. ]
Index — массивоподобный объект типа pd.Index:
import numpy as np import pandas as pd data = pd.Series([0.25, 0.5, 0.75, 1.0]) print(data.index)
Результат:
RangeIndex(start=0, stop=4, step=1)
Аналогично массивам библиотеки NumPy, к данным можно обращаться по соответствующему им индексу посредством нотации с использованием квадратных скобок языка Python:
import numpy as np
import pandas as pd
data = pd.Series([0.25, 0.5, 0.75, 1.0])
print('data[1]:')
print(data[1])
print('data[1:3]:')
print(data[1:3])
Результат:
data[1]: 0.5 data[1:3]: 1 0.50 2 0.75 dtype: float64
Однако объект Series библиотеки Pandas намного универсальнее и гибче, чем эмулируемый им одномерный массив библиотеки NumPy.
Объект Series как обобщенный массив NumPy
Может показаться, что объект Series и одномерный массив библиотеки NumPy взаимозаменяемы. Основное различие между ними — индекс. В то время как индекс массива NumPy, используемый для доступа к значениям, — целочисленный и описывается неявно, индекс объекта Series библиотеки Pandas описывается явно и связывается со значениями.
Явное описание индекса расширяет возможности объекта Series. Такой индекс не должен быть целым числом, а может состоять из значений любого нужного типа. Например, при желании мы можем использовать в качестве индекса строковые значения:
import numpy as np
import pandas as pd
data = pd.Series([0.25, 0.5, 0.75, 1.0],
index=['a', 'b', 'c', 'd'])
print(data)
Результат:
a 0.25 b 0.50 c 0.75 d 1.00 dtype: float64
При этом доступ к элементам работает обычным образом:
import numpy as np
import pandas as pd
data = pd.Series([0.25, 0.5, 0.75, 1.0],
index=['a', 'b', 'c', 'd'])
print(data['b'])
Результат:
0.5
Объект Series как специализированный словарь
Объект Series библиотеки Pandas можно рассматривать как специализированную разновидность словаря языка Python. Словарь — структура, задающая соответствие произвольных ключей набору произвольных значений, а объект Series — структура, задающая соответствие типизированных ключей набору типизированных значений.
Типизация важна: точно так же, как соответствующий типу специализированный код для массива библиотеки NumPy при выполнении определенных операций делает его эффективнее, чем стандартный список Python, информация о типе в объекте Series библиотеки Pandas делает его намного более эффективным для определенных операций, чем словари Python.
Можно сделать аналогию «объект Series — словарь» еще более наглядной, сконструировав объект Series непосредственно из словаря Python.
По умолчанию при этом будет создан объект Series с полученным из отсортированных ключей индексом. Следовательно, для него возможен обычный доступ к элементам, такой же, как для словаря. Объект Series поддерживает операции «срезы».
import numpy as np
import pandas as pd
# Словарь
population_dict = {'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
print('population:')
print(population)
# Доступ к элементам
print("population['California']:")
print(population['California'])
# Срез
print("population['California':'New York']:")
print(population['California':'New York'])
Результат:
population: California 38332521 Texas 26448193 New York 19651127 Florida 19552860 Illinois 12882135 dtype: int64 population['California']: 38332521 population['California':'New York']: California 38332521 Texas 26448193 New York 19651127 dtype: int64
Создание объектов Series
Мы уже изучили несколько способов создания объектов Series библиотеки Pandas с нуля.
Все они представляют собой различные варианты следующего синтаксиса Pandas Series (общий вид синтаксиса):
pd.Series(data, index=index)
где index — необязательный аргумент, а data может быть одной из множества сущностей.
Например, аргумент data может быть списком или массивом NumPy. В этом случае index по умолчанию будет целочисленной последовательностью:
import pandas as pd data = pd.Series([2, 4, 6]) print(data)
Результат:
0 2 1 4 2 6 dtype: int64
Аргумент data может быть скалярным значением, которое будет повторено нужное количество раз для заполнения заданного индекса:
import pandas as pd data = pd.Series(5, index=[100, 200, 300]) print(data)
Результат:
100 5 200 5 300 5 dtype: int64
Аргумент data может быть словарем, в котором index по умолчанию является отсортированными ключами этого словаря:
import pandas as pd
data = pd.Series({2:'a', 1:'b', 3:'c'})
print(data)
Результат:
2 a 1 b 3 c dtype: object
В каждом случае индекс можно указать вручную, если необходимо получить другой результат:
import pandas as pd
data = pd.Series({2:'a', 1:'b', 3:'c'}, index=[3, 2])
print(data)
Результат:
3 c 2 a dtype: object
Обратите внимание, что объект Series заполняется только заданными явным образом ключами.
Объект DataFrame библиотеки Pandas
Следующая базовая структура библиотеки Pandas — объект DataFrame. Как и объект Series, объект DataFrame можно рассматривать или как обобщение массива NumPy, или как специализированную версию словаря Python. Изучим оба варианта.
DataFrame как обобщенный массив NumPy
Если объект Series — аналог одномерного массива с гибкими индексами, объект DataFrame — аналог двумерного массива с гибкими индексами строк и гибкими именами столбцов. Аналогично тому, что двумерный массив можно рассматривать как упорядоченную последовательность выровненных столбцов, объект DataFrame можно рассматривать как упорядоченную последовательность выровненных объектов Series. Под «выровненными» имеется в виду то, что они используют один и тот же индекс.
Чтобы продемонстрировать это, сначала создадим новый объект Series, содержащий площадь каждого из пяти упомянутых в предыдущем разделе штатов:
import pandas as pd
area_dict = {'California': 423967,
'Texas': 695662,
'New York': 141297,
'Florida': 170312,
'Illinois': 149995}
area = pd.Series(area_dict)
print(area)
Результат:
California 423967 Texas 695662 New York 141297 Florida 170312 Illinois 149995 dtype: int64
Воспользовавшись объектом population класса Series, сконструируем на основе словаря единый двумерный объект, содержащий всю эту информацию:
import pandas as pd
# Словарь площадь штатов
area_dict = {'California': 423967,
'Texas': 695662,
'New York': 141297,
'Florida': 170312,
'Illinois': 149995}
area = pd.Series(area_dict)
# Словарь население
population_dict = {'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
# Создаем DataFrame
states = pd.DataFrame({'population': population, 'area': area})
print(states)
Результат:
population area California 38332521 423967 Texas 26448193 695662 New York 19651127 141297 Florida 19552860 170312 Illinois 12882135 149995
Аналогично объекту Series у объекта DataFrame имеется атрибут index, обеспечивающий доступ к меткам индекса. Еще у объекта DataFrame есть атрибут columns, представляющий собой содержащий метки столбцов объект Index.
import pandas as pd
# Словарь площадь штатов
area_dict = {'California': 423967,
'Texas': 695662,
'New York': 141297,
'Florida': 170312,
'Illinois': 149995}
area = pd.Series(area_dict)
# Словарь население
population_dict = {'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
# Создаем DataFrame
states = pd.DataFrame({'population': population, 'area': area})
print('Индексы - states.index:')
print(states.index)
print('')
print('Колонки - states.columns:')
print(states.columns)
Результат:
Индексы - states.index: Index(['California', 'Texas', 'New York', 'Florida', 'Illinois'], dtype='object') Колонки - states.columns: Index(['population', 'area'], dtype='object')
Таким образом, объект DataFrame можно рассматривать как обобщение двумерного массива NumPy, где как у строк, так и у столбцов есть обобщенные индексы для доступа к данным.
Объект DataFrame как специализированный словарь
DataFrame можно рассматривать как специализированный словарь. Если словарь задает соответствие ключей значениям, то DataFrame задает соответствие имени столбца объекту Series с данными этого столбца. Например, запрос данных по атрибуту ‘area’ приведет к тому, что будет возвращен объект Series, содержащий площади штатов:
import pandas as pd
# Словарь площадь штатов
area_dict = {'California': 423967,
'Texas': 695662,
'New York': 141297,
'Florida': 170312,
'Illinois': 149995}
area = pd.Series(area_dict)
# Словарь население
population_dict = {'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
# Создаем DataFrame
states = pd.DataFrame({'population': population, 'area': area})
print(states['area'])
Результат:
California 423967 Texas 695662 New York 141297 Florida 170312 Illinois 149995 Name: area, dtype: int64
Создание объектов DataFrame
Существует множество способов создания объектов DataFrame библиотеки Pandas. Вот несколько примеров.
Из одного объекта Series
Объект DataFrame — набор объектов Series.
DataFrame, состоящий из одного столбца, можно создать на основе одного объекта Series:
import pandas as pd
# Словарь население
population_dict = {'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
df = pd.DataFrame(population, columns=['population'])
print(df)
Результат:
population California 38332521 Texas 26448193 New York 19651127 Florida 19552860 Illinois 12882135
Из списка словарей
Любой список словарей можно преобразовать в объект DataFrame. Мы воспользуемся простым списковым включением для создания данных:
import pandas as pd
data = [{'a': i, 'b': 2 * i}
for i in range(3)]
print('data:')
print(data)
print('')
df = pd.DataFrame(data)
print('df:')
print(df)
Результат:
data:
[{'a': 0, 'b': 0}, {'a': 1, 'b': 2}, {'a': 2, 'b': 4}]
df:
a b
0 0 0
1 1 2
2 2 4
Даже если некоторые ключи в словаре отсутствуют, библиотека Pandas просто заполнит их значениями NaN (то есть Not a number — «не является числом»):
import pandas as pd
df = pd.DataFrame([{'a': 1, 'b': 2}, {'b': 3, 'c': 4}])
print('df:')
print(df)
Результат:
df:
a b c
0 1.0 2 NaN
1 NaN 3 4.0
Из словаря объектов Series
Объект DataFrame также можно создать на основе словаря объектов Series (этот пример был приведен ранее):
import pandas as pd
# Словарь площадь штатов
area_dict = {'California': 423967,
'Texas': 695662,
'New York': 141297,
'Florida': 170312,
'Illinois': 149995}
area = pd.Series(area_dict)
# Словарь население
population_dict = {'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135}
population = pd.Series(population_dict)
# Создаем DataFrame
df = pd.DataFrame({'population': population,
'area': area})
print(df)
Результат:
population area California 38332521 423967 Texas 26448193 695662 New York 19651127 141297 Florida 19552860 170312 Illinois 12882135 149995
Из двумерного массива NumPy
Если у нас есть двумерный массив данных, мы можем создать объект DataFrame с любыми заданными именами столбцов и индексов. Для каждого из пропущенных значений будет использоваться целочисленный индекс:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(3, 2),
columns=['foo', 'bar'],
index=['a', 'b', 'c'])
print(df)
Результат:
foo bar a 0.290872 0.647270 b 0.690850 0.950563 c 0.468706 0.344193
Из структурированного массива NumPy
Объект DataFrame библиотеки Pandas ведет себя во многом аналогично структурированному массиву библиотеки NumPy и может быть создан непосредственно из него:
import numpy as np
import pandas as pd
A = np.zeros(3, dtype=[('A', 'i8'), ('B', 'f8')])
print('A:')
print(A)
print('')
df = pd.DataFrame(A)
print('df:')
print(df)
Результат:
A: [(0, 0.) (0, 0.) (0, 0.)] df: A B 0 0 0.0 1 0 0.0 2 0 0.0
Объект Index библиотеки Pandas
Как объект Series, так и объект DataFrame содержат явный индекс, обеспечивающий возможность ссылаться на данные и модифицировать их.
Объект Index можно рассматривать или как неизменяемый массив (immutable array), или как упорядоченное множество (ordered set) (формально мультимножество, так как объекты Index могут содержать повторяющиеся значения). Из этих способов его представления следуют некоторые интересные возможности операций над объектами Index. В качестве простого примера создадим Index из списка целых чисел:
import pandas as pd ind = pd.Index([2, 3, 5, 7, 11]) print(ind)
Результат:
Int64Index([2, 3, 5, 7, 11], dtype='int64')
Объект Index как неизменяемый массив
Объект Index во многом ведет себя аналогично массиву. Например, для извлечения из него значений или срезов можно использовать стандартную нотацию индексации языка Python. У объектов Index есть много атрибутов.
Результат:
ind[1] 3 ind[::2] Int64Index([2, 5, 11], dtype='int64') ind.size, ind.shape, ind.ndim, ind.dtype 5 (5,) 1 int64
Одно из различий между объектами Index и массивами NumPy — неизменяемость индексов, то есть их нельзя модифицировать стандартными средствами:
import pandas as pd ind = pd.Index([2, 3, 5, 7, 11]) ind[1] = 0
Результат:
Traceback (most recent call last):
File "C:/Users/User/Desktop/test.py", line 4, in <module>
ind[1] = 0
File "C:\Users\User\AppData\Local\Programs\Python\Python37-32\lib\site-packages\pandas\core\indexes\base.py", line 3938, in __setitem__
raise TypeError("Index does not support mutable operations")
TypeError: Index does not support mutable operations
Неизменяемость делает безопаснее совместное использование индексов несколькими объектами DataFrame и массивами, исключая возможность побочных эффектов в виде случайной модификации индекса по неосторожности.
Выбор подмножеств данных в Pandas
Анатомия Python Pandas DataFrame — Column, Index, Data
Рассмотрим изображение контейнера данных DataFrame (библиотеки Pandas):

Три компонента DataFrame:
DataFrame состоит из трех различных компонентов: индекса , столбцов и данных. Данные также известны как значения.
Индекс — это последовательность значений в левой части DataFrame. Каждое отдельное значение индекса называется index label, Иногда индекс упоминается как заголовки строк. В приведенном выше примере метки строк не очень интересны и представляют собой целые числа, начиная с 0 до n-1, где n — количество строк в таблице.
Столбцы представляют собой последовательность значений в самой верхней части DataFrame.
Все остальное является данными или значениями. Иногда вы будете слышать, как датафреймы называют табличными данными. Это просто еще одно имя для данных прямоугольной таблицы со строками и столбцами.
Каждая строка имеет метку, каждая колонка имеет метку
Основной вывод из анатомии DataFrame заключается в том, что каждая строка имеет метку, каждый столбец имеет метку. Эти метки используются для ссылки на конкретные строки или столбцы в DataFrame.
Что такое выбор подмножества?
Прежде чем мы начнем делать выбор подмножества, было бы хорошо определить, что это такое. Выбор подмножества — это просто выбор определенных строк и столбцов данных из DataFrame (или Series). Это может означать выбор всех строк и некоторых столбцов, некоторых строк и всех столбцов или некоторых строк и столбцов.
Выбор при помощи []
Загружаем данные из CSV в Pandas DataFrame (Python 3)
В совокупности [], .loc и .iloc называются индексаторами. Это самые распространенные способы выбора данных.
Скачать файл для использования в примерах:
Код загрузки данных из csv в Pandas DataFrame:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';', index_col=0)
print(df)
Результат:
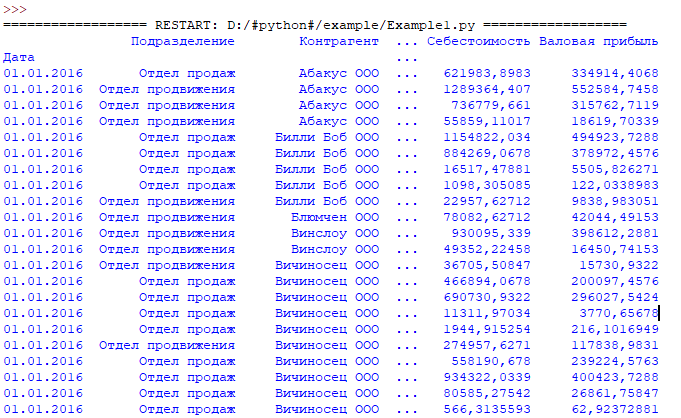
Вариант 2 загрузки данных из CSV (Index генерируется самостоятельно)
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df)
Результат:
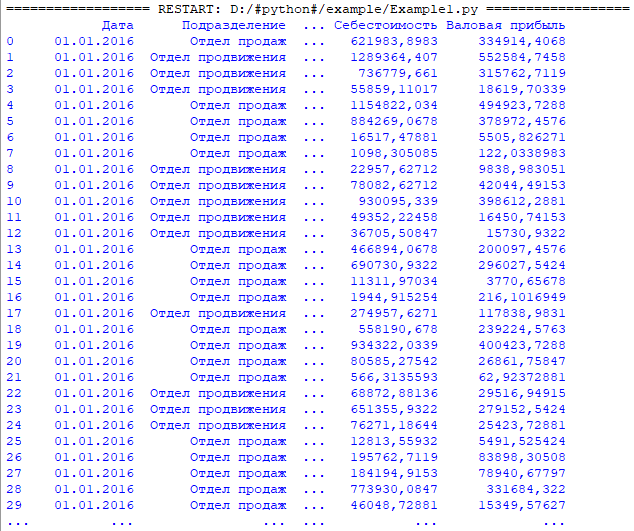
Извлечение отдельных компонентов DataFrame
Ранее мы упоминали три компоненты DataFrame. Индекс, столбцы и данные (значения). Мы можем извлечь каждый из этих компонентов в свои переменные. Давайте сделаем это, а затем осмотрим их:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
index = df.index
columns = df.columns
values = df.values
index_list = df.index.tolist()
columns_list = df.columns.tolist()
values_list = df.values.tolist()
print('+++++ БЕЗ TOLIST() +++++')
print(index)
print('==========================')
print(columns)
print('==========================')
print(values)
print('==========================')
print('+++++ С TOLIST() +++++')
print(index_list)
print('==========================')
print(columns_list)
print('==========================')
print(values_list)
Результат:

Типы данных компонентов
Давайте выведем тип каждого компонента, чтобы точно понять, что это за объект.
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
index = df.index
columns = df.columns
values = df.values
index_list = df.index.tolist()
columns_list = df.columns.tolist()
values_list = df.values.tolist()
print('+++++ БЕЗ TOLIST() +++++')
print(type(index))
print('==========================')
print(type(columns))
print('==========================')
print(type(values))
print('==========================')
print('+++++ С TOLIST() +++++')
print(type(index_list))
print('==========================')
print(type(columns_list))
print('==========================')
print(type(values_list))
Результат:
+++++ БЕЗ TOLIST() +++++ <class 'pandas.core.indexes.range.RangeIndex'> ========================== <class 'pandas.core.indexes.base.Index'> ========================== <class 'numpy.ndarray'> ========================== +++++ С TOLIST() +++++ <class 'list'> ========================== <class 'list'> ========================== <class 'list'>
Понимание этих типов
Интересно, что и индекс, и столбцы имеют одинаковый тип. Они оба Index-объект Pandas. Этот объект сам по себе довольно мощный, но сейчас вы можете думать о нем как о последовательности меток для строк или столбцов.
Значения (ячейки таблицы) — это numpy.ndarray, который обозначает n-мерный массив и является основным контейнером данных в библиотеке NumPy.
Pandas построен непосредственно поверх NumPy, и именно этот массив отвечает за большую часть рабочей нагрузки.
Выбор одного столбца как серии
Чтобы выбрать один столбец данных, просто поместите имя столбца в скобках. Давайте выберем столбец Подразделение:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df['Подразделение'])
Результат:
0 Отдел продаж
1 Отдел продвижения
2 Отдел продвижения
3 Отдел продвижения
...
2662 Отдел продаж
2663 Отдел продаж
2664 Отдел продаж
2665 Отдел продвижения
2666 Отдел продвижения
2667 Отдел продвижения
2668 Отдел продвижения
Name: Подразделение, Length: 2669, dtype: object
Анатомия Series, возвращаемой при выборе 1 столбца
Выбор одного столбца данных возвращает другой контейнер данных Pandas Series.
Series — это одномерная последовательность помеченных данных. Существует два основных компонента Серии: указатель и данные (или значения . В серии нет колонок.
Визуальное отображение Series — это просто текст, в отличие от красиво оформленной таблицы для DataFrames.
Вы также заметите две дополнительные части данных в нижней части Series.
Name из Series становится старое имя колонки. Вы также увидите тип данных или dtype серии. Вы можете игнорировать оба этих элемента на данный момент. А также количество элементов Length.
Выбор нескольких столбцов с помощью оператора индексации
Можно выбрать несколько столбцов только с помощью оператора индексации, передав ему список имен столбцов. Давайте выберем ‘Подразделение’, ‘Менеджер’, ‘Номенклатура’, ‘Продажи’
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df[['Подразделение','Менеджер','Номенклатура','Продажи']])
Результат:
Подразделение Менеджер Номенклатура Продажи 0 Отдел продаж Петров Лыжи 956898,3051 1 Отдел продвижения Сидоров Велосипеды 1841949,153 2 Отдел продвижения Сидоров Доски 1052542,373 3 Отдел продвижения Сидоров Палатки 74478,81356 4 Отдел продаж Илинская Велосипеды 1649745,763 5 Отдел продаж Илинская Доски 1263241,525 ... ... ... ... ... 2661 Отдел продаж Петров Прочее 423,7288136 2662 Отдел продаж Илинская Лыжи -15254,23729 2663 Отдел продаж Петров Лыжи 8176271,186 2664 Отдел продаж Петров Прочее 171186,4407 2665 Отдел продвижения Охлобыстин Прочее 16949,15254 2666 Отдел продвижения Розницов Лыжи 15254,23729 2667 Отдел продвижения Розницов Одежда 1444915,254 2668 Отдел продвижения Розницов Прочее 3389,830508 [2669 rows x 4 columns]
Выбор нескольких столбцов возвращает DataFrame
Выбор нескольких столбцов возвращает DataFrame. На самом деле вы можете выбрать один столбец как DataFrame со списком из одного элемента:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df[['Подразделение']])
Результат:
Подразделение 0 Отдел продаж 1 Отдел продвижения 2 Отдел продвижения ... ... 2666 Отдел продвижения 2667 Отдел продвижения 2668 Отдел продвижения [2669 rows x 1 columns]
Хотя это напоминает Series, технически это DataFrame, другой объект.
Порядок столбцов не имеет значения
При выборе нескольких столбцов вы можете выбрать их в любом порядке по вашему выбору. Это не должен быть тот же самый порядок как оригинальный DataFrame.
Например, давайте выберем Номенклатура, Подразделение:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df[['Номенклатура','Подразделение']])
Результат:
Номенклатура Подразделение 0 Лыжи Отдел продаж 1 Велосипеды Отдел продвижения 2 Доски Отдел продвижения 3 Палатки Отдел продвижения 4 Велосипеды Отдел продаж ... ... ... 2666 Лыжи Отдел продвижения 2667 Одежда Отдел продвижения 2668 Прочее Отдел продвижения [2669 rows x 2 columns]
Исключения, при выполнении скрипта
Есть несколько общих исключений, которые возникают при выполнении выборок только с помощью оператора индексации.
- Если вы ошиблись словом, вы получите KeyError
- Если вы забыли использовать список, содержащий несколько столбцов, вы также получите KeyError
print(df['ПодразделениЯ'])
Результат:
KeyError: 'ПодразделениЯ'
print(df['Номенклатура','Подразделение'])
Результат:
KeyError: ('Номенклатура', 'Подразделение')
В первом случае должно стоять print(df['Подразделение']). А во-втором случае: print(df[['Номенклатура','Подразделение']]).
Выборка данных из Pandas DataFrame с помощью .loc
В .loc индексатор выбирает данные по-другому, чем просто оператор индексации. Он может выбирать подмножества строк и/или столбцов. Самое главное, он выбирает данные только по метке (label) строк и столбцов.
Выберем одну строку как Series с .loc
.loc — Индексатор возвращает одну строку в серии, когда указали одну метку строки (один индекс).
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[0])
Результат:
Дата 01.01.2016 Подразделение Отдел продаж Контрагент Абакус ООО Менеджер Петров Номенклатура Лыжи Продажи 956898,3051 Себестоимость 621983,8983 Валовая прибыль 334914,4068 Name: 0, dtype: object
Теперь у нас есть Series, где старые имена столбцов теперь являются индексными метками.
Выбираем несколько строк из DataFrame с помощью .loc
Чтобы выбрать несколько строк, поместите все метки строк, которые вы хотите выбрать, в список и передайте их .loc. Давайте выберем 3 и 20.
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[[3,20]])
Результат:
Дата Подразделение ... Себестоимость Валовая прибыль 3 01.01.2016 Отдел продвижения ... 55859,11017 18619,70339 20 01.01.2016 Отдел продаж ... 80585,27542 26861,75847 [2 rows x 8 columns]
Обозначение среза для выборки диапазона строк с .loc
Можно «нарезать» строки DataFrame с .locпомощью нотации среза. Для обозначения среза используется двоеточие для разделения значений начала, остановки и шага . Например, мы можем выбрать все строки из с 134 по 139:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[134:139])
Результат:
Дата Подразделение ... Себестоимость Валовая прибыль 134 01.01.2016 Отдел продвижения ... 560,5932203 62,28813559 135 01.01.2016 Отдел продаж ... 625773,3051 268188,5593 136 01.01.2016 Отдел продвижения ... 508671,6102 218002,1186 137 01.01.2016 Отдел продвижения ... 1034427,966 443326,2712 138 01.01.2016 Отдел продвижения ... 55792,37288 18597,45763 139 01.01.2016 Отдел продвижения ... 8477,542373 941,9491525 [6 rows x 8 columns]
.loc включает в себя последнее значение из обозначения среза
Обратите внимание, что строка с пометкой 139 в примере без шага была выведена. В других контейнерах данных, таких как списки Python, последнее значение исключается.
Вывод среза с использованием .loc и шага из DataFrame
Выведем тот же самый результат, только будем выводить каждый второй элемент из среза:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[134:139:2])
Результат:
Дата Подразделение ... Себестоимость Валовая прибыль 134 01.01.2016 Отдел продвижения ... 560,5932203 62,28813559 136 01.01.2016 Отдел продвижения ... 508671,6102 218002,1186 138 01.01.2016 Отдел продвижения ... 55792,37288 18597,45763 [3 rows x 8 columns]
Выбор до указанной позиции .loc
Пример скрипта Python 3 для вывода 139 первых строк из Pandas DataFrame:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[:139])
Результат:
Дата Подразделение ... Себестоимость Валовая прибыль 0 01.01.2016 Отдел продаж ... 621983,8983 334914,4068 1 01.01.2016 Отдел продвижения ... 1289364,407 552584,7458 2 01.01.2016 Отдел продвижения ... 736779,661 315762,7119 3 01.01.2016 Отдел продвижения ... 55859,11017 18619,70339 .. ... ... ... ... ... 136 01.01.2016 Отдел продвижения ... 508671,6102 218002,1186 137 01.01.2016 Отдел продвижения ... 1034427,966 443326,2712 138 01.01.2016 Отдел продвижения ... 55792,37288 18597,45763 139 01.01.2016 Отдел продвижения ... 8477,542373 941,9491525 [140 rows x 8 columns]
Тот же самый пример, но выведем с шагом 25:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[:139:25])
Результат выполнения выборки данных из Pandas DataFrame:
Дата Подразделение ... Себестоимость Валовая прибыль 0 01.01.2016 Отдел продаж ... 621983,8983 334914,4068 25 01.01.2016 Отдел продаж ... 12813,55932 5491,525424 50 01.01.2016 Отдел продаж ... 42978,81356 14326,27119 75 01.01.2016 Отдел продвижения ... 6246,610169 694,0677966 100 01.01.2016 Отдел продвижения ... 89694,91525 38440,67797 125 01.01.2016 Отдел продвижения ... 879864,4068 377084,7458 [6 rows x 8 columns]
Выбор с указанной позиции до конца DataFrame через .loc
Полный код вывода данных из Pandas DataFrame:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[2660:])
Результат запроса к DataFrame:
Дата Подразделение ... Себестоимость Валовая прибыль 2660 01.12.2017 Отдел продаж ... 762,7118644 84,74576271 2661 01.12.2017 Отдел продаж ... 381,3559322 42,37288136 2662 01.12.2017 Отдел продаж ... -9915,254237 -5338,983051 2663 01.12.2017 Отдел продаж ... 5314576,271 2861694,915 2664 01.12.2017 Отдел продаж ... 154067,7966 17118,64407 2665 01.12.2017 Отдел продвижения ... 15254,23729 1694,915254 2666 01.12.2017 Отдел продвижения ... 9915,254237 5338,983051 2667 01.12.2017 Отдел продвижения ... 1083686,441 361228,8136 2668 01.12.2017 Отдел продвижения ... 3050,847458 338,9830508 [9 rows x 8 columns]
Тот же пример, но с шагом 3 (вывод каждого третьего элемента из Pandas DataFrame с использованием .iloc[]):
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[2660::3])
Результат:
Дата Подразделение ... Себестоимость Валовая прибыль 2660 01.12.2017 Отдел продаж ... 762,7118644 84,74576271 2663 01.12.2017 Отдел продаж ... 5314576,271 2861694,915 2666 01.12.2017 Отдел продвижения ... 9915,254237 5338,983051 [3 rows x 8 columns]
Выбор строк и столбцов одновременно с .loc
В отличие от просто оператора индексирования, можно выбирать строки и столбцы одновременно с .loc. Вы делаете это, разделяя выбранные строки и столбцы запятой. Это будет выглядеть примерно так:
df.loc [row_selection, column_selection]
Пример запроса на Python 3:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[[150,163],['Подразделение','Менеджер','Продажи']])
Результат:
Подразделение Менеджер Продажи 150 Отдел продаж Петров 1067796,61 163 Отдел продвижения Сидоров 13665,25424
Используйте любую комбинацию выбора для строки или столбца с .loc
Выбор строки или столбца может быть совершен любым из следующих способов:
- Один ярлык
- Список ярлыков
- slice с метками
Мы можем использовать любой из этих трех вариантов для выбора строки или столбца с помощью .loc. Давайте посмотрим несколько примеров.
Пример 1 «Выборка данных из Pandas DataFrame»:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[150:163:3,['Подразделение','Менеджер','Продажи']])
Результат:
Подразделение Менеджер Продажи 150 Отдел продаж Петров 1067796,61 153 Отдел продвижения Добряков 82944,91525 156 Отдел продвижения Добряков 85023,30508 159 Отдел продаж Петров 499385,5932 162 Отдел продвижения Сидоров 130805,0847
Выбор строк и столбцов через переменные
Гораздо проще назначить список строк и столбцов переменным перед использованием в .loc. Это полезно, если вы выбираете много строк или столбцов:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
rows = [59, 134, 1045]
columns = ['Контрагент', 'Номенклатура', 'Продажи']
print(df.loc[rows, columns])
Результат:
Контрагент Номенклатура Продажи 59 ИП Лусон Велосипеды 1139110,169 134 Союз АО Прочее 622,8813559 1045 Эсвольтр ООО Прочее 2915,254237
Пример параметризации с slice:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
iStart = 59
iEnd = 134
iStep = 7
columns = ['Контрагент', 'Номенклатура', 'Продажи']
print(df.loc[iStart:iEnd:iStep, columns])
Результат:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
iStart = 59
iEnd = 134
iStep = 7
columns = ['Контрагент', 'Номенклатура', 'Продажи']
print(df.loc[iStart:iEnd:iStep, columns])
Выборка данных из Pandas DataFrame с помощью индексатора .iloc[]
.iloc индексатор очень похож на .loc, но использует только целое число позиций, по которым необходимо сделать выборку.
Выбор одной строки при помощи .iloc
Передав одно целое число в .iloc, он выберет одну строку в качестве ряда:
Код запроса:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.iloc[5])
Результат:
Дата 01.01.2016 Подразделение Отдел продаж Контрагент Билли Боб ООО Менеджер Илинская Номенклатура Доски Продажи 1263241,525 Себестоимость 884269,0678 Валовая прибыль 378972,4576 Name: 5, dtype: object
Выбор нескольких строк с .iloc
Используйте список целых чисел, чтобы выбрать несколько строк:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.iloc[[5,45,876]])
Результат:
Дата Подразделение ... Себестоимость Валовая прибыль 5 01.01.2016 Отдел продаж ... 884269,0678 378972,4576 45 01.01.2016 Отдел продаж ... 162972,4576 69845,33898 876 01.08.2016 Отдел продвижения ... 444322,0339 190423,7288 [3 rows x 8 columns]
Выборка диапазона строк через указание среза в .iloc
В случае с .iloc нотация слайса работает так же, как и список, и исключает последний элемент.
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.iloc[5:9])
Результат:
Дата Подразделение ... Себестоимость Валовая прибыль 5 01.01.2016 Отдел продаж ... 884269,0678 378972,4576 6 01.01.2016 Отдел продаж ... 16517,47881 5505,826271 7 01.01.2016 Отдел продаж ... 1098,305085 122,0338983 8 01.01.2016 Отдел продвижения ... 22957,62712 9838,983051 [4 rows x 8 columns]
Выбор строк и столбцов одновременно в .iloc
Рассмотрим несколько примеров, чтобы понять, чем отличается .iloc от .loc.
Выберем две строки и два столбца:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.iloc[[2,3], [0,3]])
Результат:
Дата Менеджер 2 01.01.2016 Сидоров 3 01.01.2016 Сидоров
Осуществим выборку строк и столбцов с помощью среза:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.iloc[2:9, 0:3])
Результат:
Дата Подразделение Контрагент 2 01.01.2016 Отдел продвижения Абакус ООО 3 01.01.2016 Отдел продвижения Абакус ООО 4 01.01.2016 Отдел продаж Билли Боб ООО 5 01.01.2016 Отдел продаж Билли Боб ООО 6 01.01.2016 Отдел продаж Билли Боб ООО 7 01.01.2016 Отдел продаж Билли Боб ООО 8 01.01.2016 Отдел продвижения Билли Боб ООО
Выберем 1 значение из столбца и указанной колонки:
import pandas as pd
import numpy as np
df = pd.read_csv('D:\#python#\example\SampleData_Pandas.csv', sep=';')
print(df.loc[3, 4])
Результат:
Палатки
Резюме по .loc и .iloc
Доступ к строкам и колонкам по индексу возможен несколькими способами:
- .loc — используется для доступа по строковой метке — т.е. фактически по значению индекса и по названию столбца
- .iloc — используется для доступа по числовому значению (начиная от 0) — т.е. по номеру строки и номеру столбца



Как выбрать строки из Pandas DataFrame по условию
Собираем тестовый набор данных для иллюстрации работы выборки по условию
| Color | Shape | Price |
| Green | Rectangle | 10 |
| Green | Rectangle | 15 |
| Green | Square | 5 |
| Blue | Rectangle | 5 |
| Blue | Square | 10 |
| Red | Square | 15 |
| Red | Square | 15 |
| Red | Rectangle | 5 |
Пишем скрипт:
import pandas as pd
Boxes = {'Color': ['Green','Green','Green','Blue','Blue','Red','Red','Red'],
'Shape': ['Rectangle','Rectangle','Square','Rectangle','Square','Square','Square','Rectangle'],
'Price': [10,15,5,5,10,15,15,5]
}
df = pd.DataFrame(Boxes, columns= ['Color','Shape','Price'])
print (df)
Результат выполнения:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15 2 Green Square 5 3 Blue Rectangle 5 4 Blue Square 10 5 Red Square 15 6 Red Square 15 7 Red Rectangle 5
Синтаксис выборки строк из Pandas DataFrame по условию
Вы можете использовать следующую логику для выбора строк в Pandas DataFrame по условию:
df.loc[df.column name condition]
Например, если вы хотите получить строки с зеленым цветом , вам нужно применить:
df.loc[df.Color == 'Green']
Где:
- Color — это название столбца
- Green — это условие (значение колонки)
А вот полный код Python для нашего примера:
import pandas as pd
Boxes = {'Color': ['Green','Green','Green','Blue','Blue','Red','Red','Red'],
'Shape': ['Rectangle','Rectangle','Square','Rectangle','Square','Square','Square','Rectangle'],
'Price': [10,15,5,5,10,15,15,5]
}
df = pd.DataFrame(Boxes, columns= ['Color','Shape','Price'])
print (df.loc[df.Color == 'Green'])
Результат:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15 2 Green Square 5
Выберем строки, где цена равна или больше 10
Чтобы получить все строки, где цена равна или больше 10, Вам нужно применить следующее условие:
df.loc[df.Price >= 10]
Полный код Python:
import pandas as pd
Boxes = {'Color': ['Green','Green','Green','Blue','Blue','Red','Red','Red'],
'Shape': ['Rectangle','Rectangle','Square','Rectangle','Square','Square','Square','Rectangle'],
'Price': [10,15,5,5,10,15,15,5]
}
df = pd.DataFrame(Boxes, columns= ['Color','Shape','Price'])
print (df.loc[df.Price >= 10])
Результат:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15 4 Blue Square 10 5 Red Square 15 6 Red Square 15
Выберем строки, в которых цвет зеленый, а форма — прямоугольник
Теперь цель состоит в том, чтобы выбрать строки на основе двух условий:
- Color зеленый; а также
- Shape = прямоугольник
Мы будем использовать символ & для применения нескольких условий. В нашем примере код будет выглядеть так:
df.loc[(df.Color == 'Green') & (df.Shape == 'Rectangle')]
Полный код примера Python для выборки Pandas DataFrame:
import pandas as pd
Boxes = {'Color': ['Green','Green','Green','Blue','Blue','Red','Red','Red'],
'Shape': ['Rectangle','Rectangle','Square','Rectangle','Square','Square','Square','Rectangle'],
'Price': [10,15,5,5,10,15,15,5]
}
df = pd.DataFrame(Boxes, columns= ['Color','Shape','Price'])
print (df.loc[(df.Color == 'Green') & (df.Shape == 'Rectangle')])
Результат:
Color Shape Price 0 Green Rectangle 10 1 Green Rectangle 15
Выберем строки, где цвет зеленый ИЛИ форма прямоугольная
Для достижения этой цели будем использовать символ | следующим образом:
df.loc[(df.Color == 'Green') | (df.Shape == 'Rectangle')]
Полный код Python 3:
import pandas as pd
Boxes = {'Color': ['Green','Green','Green','Blue','Blue','Red','Red','Red'],
'Shape': ['Rectangle','Rectangle','Square','Rectangle','Square','Square','Square','Rectangle'],
'Price': [10,15,5,5,10,15,15,5]
}
df = pd.DataFrame(Boxes, columns= ['Color','Shape','Price'])
print (df.loc[(df.Color == 'Green') | (df.Shape == 'Rectangle')])
Результат:
Color Shape Price
0 Green Rectangle 10
1 Green Rectangle 15
2 Green Square 5
3 Blue Rectangle 5
7 Red Rectangle 5
Выберем строки, где цена не равна 15
Мы будем использовать комбинацию символов !=, чтобы выбрать строки, цена которых не равна 15:
df.loc[df.Price != 15]
Полный код Pandas DF на питоне:
import pandas as pd
Boxes = {'Color': ['Green','Green','Green','Blue','Blue','Red','Red','Red'],
'Shape': ['Rectangle','Rectangle','Square','Rectangle','Square','Square','Square','Rectangle'],
'Price': [10,15,5,5,10,15,15,5]
}
df = pd.DataFrame(Boxes, columns= ['Color','Shape','Price'])
print (df.loc[df.Price != 15])
Результат работы скрипта Python:
Color Shape Price 0 Green Rectangle 10 2 Green Square 5 3 Blue Rectangle 5 4 Blue Square 10 7 Red Rectangle 5
Data Wrangling with Pandas
Обработка данных с помощью Pandas (Data Wrangling)
Обработка данных является одной из важнейших задач в data science и анализе данных, которая включает такие операции, как:
- Dealing with missing values (Работа с пропущенными значениями) — количественная оценка пропущенных значений для каждого столбца, заполнение и удаление пропущенных значений.
- Reshaping data (Изменение формы данных) — единая кодировка данных, сводные таблицы, объединения, группировка и агрегирование.
- Data Sorting (Сортировка данных): упорядочивание значений в порядке возрастания или убывания.
- Data Filtration (Фильтрация данных): создание подмножества данных согласно тем или иным условиям.
- Data deduplication (Дедупликация данных) — это технология поиска и устранения дубликатов в хранилищах данных. Применяется для снижения накладные расходов на хранение информации.
- Data Reduction (Понижение размерности/Сокращение данных): Уменьшение объема данных, сокращение количества используемых признаков и разнообразия их значений. Применяется в случае, когда данные избыточны. Избыточность возникает тогда, когда задачу анализа можно решить с тем же уровнем эффективности и точности, но используя меньшую размерность данных. Это позволяет сократить время и вычислительные затраты на решение задачи, сделать данные и результаты их анализа более интерпретируемыми и понятными для пользователя.
- Data Access (Доступ к данным): для чтения или записи файлов данных.
- Data Handling/Data Processing (Обработка данных) или Data Transformation (преобразование данных): выполнение агрегации, статистических и подобных операций над конкретными значениями.
- Другое: Создание описательных столбцов, поэлементные условные операции.
Concatenation DataFrame
todo
Joining DataFrame
todo
Merging DataFrame
todo
Pivot & Melt (Unpivot) DataFrame
todo
GroupBy Операции
todo
Применение Lambda функции в DataFrame
todo
10 трюков Python Pandas, которые сделают вашу работу более эффективной
Pandas — это широко используемый пакет Python для структурированных данных.
read_csv
Все знают эту команду. Но данные, которые вы пытаетесь прочитать, велики, попробуйте добавить этот аргумент: nrows = 5, чтобы загружать только часть данных. Тогда вы можете избежать ошибки, выбрав неправильный разделитель (он не всегда может быть разделен запятой).
(Или вы можете использовать команду ‘head’ в linux, чтобы проверить первые 5 строк (скажем) в любом текстовом файле: head -n 5 data.txt)
Затем вы можете извлечь список столбцов, используя df.columns.tolist()для извлечения всех столбцов, а затем добавить аргумент usecols = [‘c1’, ‘c2’,…], чтобы загрузить нужные вам столбцы.
Кроме того, если вы знаете типы данных нескольких определенных столбцов, вы можете добавить аргумент dtype = {‘c1’: str, ‘c2’: int,…}, чтобы он загружался быстрее.
Еще одно преимущество этого аргумента в том, что если у вас есть столбец, который содержит как строки, так и числа, рекомендуется объявить его тип строковым, чтобы не возникало ошибок при попытке объединить таблицы, используя этот столбец в качестве ключа.
select_dtypes
Если предварительная обработка данных должна выполняться в Python, эта команда сэкономит вам время. После чтения в таблице типами данных по-умолчанию для каждого столбца могут быть bool, int64, float64, object, category, timedelta64 или datetime64. Вы можете сначала проверить распределение по
df.dtypes.value_counts()
чтобы узнать все возможные типы данных вашего DataFrame
df.select_dtypes(include=['float64', 'int64'])
выбрать sub-dataframe только с числовыми характеристиками.
copy()
Это важная команда, если вы еще не слышали о ней. Если вы выполните следующие команды:
import pandas as pd
df1 = pd.DataFrame({ 'a':[0,0,0], 'b': [1,1,1]})
df2 = df1
df2['a'] = df2['a'] + 1
df1.head()
Вы обнаружите, что df1 изменен. Это потому, что df2 = df1 не делает копию df1 и присваивает ее df2, но устанавливает указатель, указывающий на df1. Таким образом, любые изменения в df2 приведут к изменениям в df1. Чтобы это исправить, вы можете сделать либо
df2 = df1.copy()
или же
from copy import deepcopy
df2 = deepcopy(df1)
map()
Это классная команда для простого преобразования данных. Сначала вы определяете словарь, в котором «ключами» являются старые значения, а «значениями» являются новые значения.
level_map = {1: 'high', 2: 'medium', 3: 'low'}
df['c_level'] = df['c'].map(level_map)
Некоторые примеры:
True, False до 1, 0 (для моделирования); определение уровней; определяемые пользователем лексические кодировки.
apply or not apply?
Если мы хотим создать новый столбец с несколькими другими столбцами в качестве входных данных, функция apply иногда будет весьма полезна.
def rule(x, y):
if x == 'high' and y > 10:
return 1
else:
return 0
df = pd.DataFrame({ 'c1':[ 'high' ,'high', 'low', 'low'], 'c2': [0, 23, 17, 4]})
df['new'] = df.apply(lambda x: rule(x['c1'], x['c2']), axis = 1)
df.head()
В приведенных выше кодах мы определяем функцию с двумя входными переменными и используем функцию apply, чтобы применить ее к столбцам ‘c1’ и ‘c2’.
Но проблема «apply» в том , что иногда он слишком медленный . Скажем, если вы хотите вычислить максимум из двух столбцов «c1» и «c2», конечно, вы можете сделать
df['maximum'] = df.apply(lambda x: max(x['c1'], x['c2']), axis = 1)
но вы найдете это намного медленнее, чем эта команда:
df['maximum'] = df[['c1','c2']].max(axis =1)
Вывод: не используйте apply, если вы можете выполнить ту же работу с другими встроенными функциями (они часто быстрее). Например, если вы хотите округлить колонку «с» целыми числами, делать
round(df[‘c’], 0)
или
df[‘c’].round(0)
Вместо использования функции применяются:
df.apply(lambda x: round(x['c'], 0), axis = 1)
value counts
Это команда для проверки распределения значений. Например, если вы хотите проверить возможные значения и частоту для каждого отдельного значения в столбце «c», вы можете сделать
df['c'].value_counts()
Есть несколько полезных трюков / аргументов:
- normalize = True: если вы хотите проверить частоту вместо количества.
- dropna = False: если вы также хотите включить пропущенные значения в статистику.
df['c'].value_counts().reset_index().: если вы хотите преобразовать таблицу статистики в кадр данных pandas и манипулировать еюdf['c'].value_counts().sort_index(): показать статистику, отсортированную по разным значениям, в столбце «c» вместо счетчиков.
number of missing values — количество пустых значений
При построении моделей может потребоваться исключить строку со слишком большим количеством пропущенных значений / строки со всеми пропущенными значениями. Вы можете использовать .isnull() и .sum() для подсчета количества пропущенных значений в указанных столбцах.
import pandas as pd
import numpy as np
df = pd.DataFrame({ 'id': [1,2,3], 'c1':[0,0,np.nan], 'c2': [np.nan,1,1]})
df = df[['id', 'c1', 'c2']]
df['num_nulls'] = df[['c1', 'c2']].isnull().sum(axis=1)
df.head()
выбрать строки с конкретными идентификаторами (select rows with specific IDs)
В SQL мы можем сделать это, используя SELECT * FROM … WHERE ID in (‘A001’, ‘C022’, …), чтобы получить записи с конкретными идентификаторами. Если вы хотите сделать то же самое с Pandas, вы можете сделать
df_filter = df['ID'].isin(['A001','C022',...])
df[df_filter]
Процентильные группы (Percentile groups)
У вас есть числовой столбец, и вы хотите классифицировать значения в этом столбце по группам, скажем, верхние 5% в группе 1, 5–20% в группе 2, 20–50% в группе 3, нижние 50% в группе 4 Конечно, вы можете сделать это с помощью pandas.cut, но я бы хотел предоставить здесь другую опцию:
import numpy as np
cut_points = [np.percentile(df['c'], i) for i in [50, 80, 95]]
df['group'] = 1
for i in range(3):
df['group'] = df['group'] + (df['c'] < cut_points[i])
# or <= cut_points[i]
который быстро запускается (не применяется функция apply).
to_csv
Опять же, это команда, которую все будут использовать. Я хотел бы указать на две уловки здесь. Первый
print(df[:5].to_csv())
Вы можете использовать эту команду, чтобы распечатать первые пять строк того, что будет записано в файл точно.
Еще один трюк — это смешанные целые числа и пропущенные значения. Если столбец содержит как пропущенные значения, так и целые числа, тип данных по-прежнему будет плавающим, а не целым. Когда вы экспортируете таблицу, вы можете добавить float_format=‘%.0f’, чтобы округлить все числа с плавающей точкой до целых чисел. Используйте этот трюк, если вам нужны только целочисленные выходные данные для всех столбцов — вы избавитесь от всех назойливых ‘.0’s.