
Содержание страницы
В повседневной обработке данных для проектов машинного обучения и data science библиотека Python Pandas является одной из наиболее часто используемых.
shift() — функция Python Pandas
Предположим, вы столкнулись с ситуацией, когда вам нужно сместить все строки в DataFrame или использовать цену акций предыдущего дня в DataFrame. Может быть, мы хотим построить среднюю температуру за последние три дня в наборе данных.
Shift() будет идеальным способом для достижения всех этих целей.
Функция Pandas Shift(), сдвигает индекс на желаемое количество периодов. Эта функция принимает скалярный параметр, называемый периодом, который представляет количество сдвигов для желаемой оси. Эта функция полезна при работе с данными временных рядов. Мы можем использовать fill_value для заполнения за пределами граничных значений.
import pandas as pd
import numpy as np
df = pd.DataFrame({'DATE': [1, 2, 3, 4, 5],
'VOLUME': [100, 200, 300,400,500],
'PRICE': [214, 234, 253,272,291]})
print(df)
===РЕЗУЛЬТАТ===
DATE VOLUME PRICE
0 1 100 214
1 2 200 234
2 3 300 253
3 4 400 272
4 5 500 291
print(df.shift(1))
===РЕЗУЛЬТАТ===
DATE VOLUME PRICE
0 NaN NaN NaN
1 1.0 100.0 214.0
2 2.0 200.0 234.0
3 3.0 300.0 253.0
4 4.0 400.0 272.0
# with fill_Value = 0
print(df.shift(1,fill_value=0))
===РЕЗУЛЬТАТ===
DATE VOLUME PRICE
0 0 0 0
1 1 100 214
2 2 200 234
3 3 300 253
4 4 400 272

Теперь, если нам нужно получить цену акций предыдущего дня в виде нового столбца, мы можем использовать сдвиг с помощью функции shift():
df['PREV_DAY_PRICE'] = df['PRICE'].shift(1,fill_value=0) print(df) ===Результат=== DATE VOLUME PRICE PREV_DAY_PRICE 0 1 100 214 0 1 2 200 234 214 2 3 300 253 234 3 4 400 272 253 4 5 500 291 272
Мы можем легко рассчитать среднюю цену акций за последние три дня, как показано ниже, и создать новый столбец функций.
df['LAST_3_DAYS_AVE_PRICE'] = (df['PRICE'].shift(1,fill_value=0) +
df['PRICE'].shift(2,fill_value=0) +
df['PRICE'].shift(3,fill_value=0))/3
Теперь DataFrame станет таким:
DATE VOLUME PRICE LAST_3_DAYS_AVE_PRICE 0 1 100 214 0.000000 1 2 200 234 71.333333 2 3 300 253 149.333333 3 4 400 272 233.666667 4 5 500 291 253.000000
Мы также можем сдвигаться вперед, чтобы получить значение из следующего временного периода или следующего значения в ряду (не обязательно это должен быть период).
df['TOMORROW_PRICE'] = df['PRICE'].shift(-1,fill_value=0)
Теперь фрейм данных будет:
DATE VOLUME PRICE TOMORROW_PRICE 0 1 100 214 234 1 2 200 234 253 2 3 300 253 272 3 4 400 272 291 4 5 500 291 0
Более подробную информацию о параметрах и других настройках см. в документации Pandas.
value_counts() — функция Python Pandas
Функция Pandas value_counts() возвращает объект, содержащий количество уникальных значений. Полученный объект можно отсортировать в порядке убывания или в порядке возрастания, включить NA или исключить NA посредством управления параметрами. Эта функция может использоваться с индексами в DataFrames или Pandas Series.

a = pd.Index([3,3,4,2,1,3, 1, 2, 3, 4, np.nan,4,6,7]) print(a.value_counts()) ===РЕЗУЛЬТАТ=== 3.0 4 4.0 3 1.0 2 2.0 2 7.0 1 6.0 1 dtype: int64
Ниже приведен пример Series.
#In b = pd.Series(['ab','bc','cd',1,'cd','cd','bc','ab','bc',1,2,3,2,3,np.nan,1,np.nan]) b.value_counts() #Out bc 3 cd 3 1 3 3 2 ab 2 2 2 dtype: int64
Опция Bin может использоваться вместо подсчета уникальных значений значений, разделив индекс на указанное количество полуоткрытых Bins.
#In a = pd.Index([3,3,4,2,1,3, 1, 2, 3, 4, np.nan,4,6,7]) a.value_counts(bins=4) #Out (2.5, 4.0] 7 (0.993, 2.5] 4 (5.5, 7.0] 2 (4.0, 5.5] 0 dtype: int64
Более подробную информацию о параметрах и других настройках см. в документации Pandas.
mask() — функция Python Pandas
Метод mask() является применением условия if-then для каждого элемента Series или DataFrame. Если Condition равно True, тогда он использует значение из Other (значение по умолчанию — NaN), в противном случае будет сохранено исходное значение. Этот метод mask() очень похож на where().
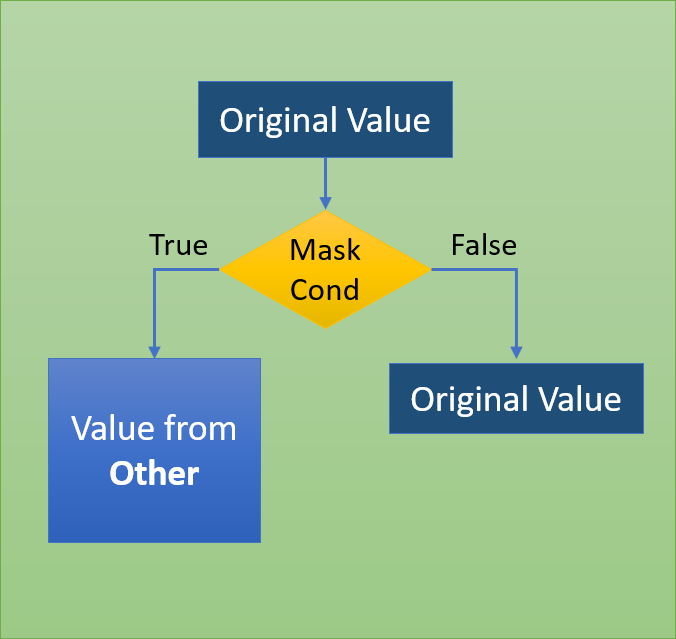
Ниже приведен DataFrame, в котором мы хотим изменить знак всех элементов, которые делятся на два без остатка.
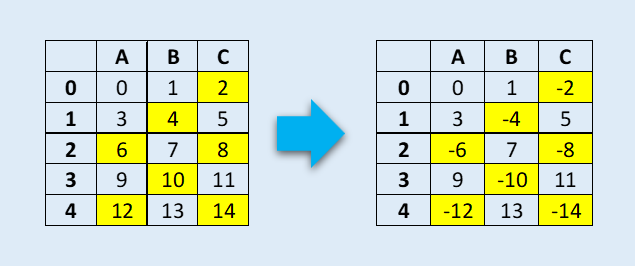
Этого легко можно достигнуть с помощью функции mask():
df = pd.DataFrame(np.arange(15).reshape(-1, 3), columns=['A', 'B','C'])
print(df)
#Out
A B C
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11
4 12 13 14
#mask operation to check if element is divided by 2 without any remainder. If match change the sign of the element as original
df.mask(df % 2 == 0,-df)
#Out
A B C
0 0 1 -2
1 3 -4 5
2 -6 7 -8
3 9 -10 11
4 -12 13 -14
Более подробную информацию о параметрах и других настройках см. в документации Pandas mask.
nlargest() — функция Python Pandas
Во многих случаях мы сталкиваемся с ситуациями, когда нам нужно найти 3 верхних (top) или 5 нижних (bottom) значений для Series или DataFrame (например, трех лучших учеников с самыми высокими показателями с их совокупным баллом или трех худших кандидатов с общим количеством голосов, полученных на выборах).
Функции Python Pandas nlargest() и nsmallest() — лучший способ для такой обработки данных.
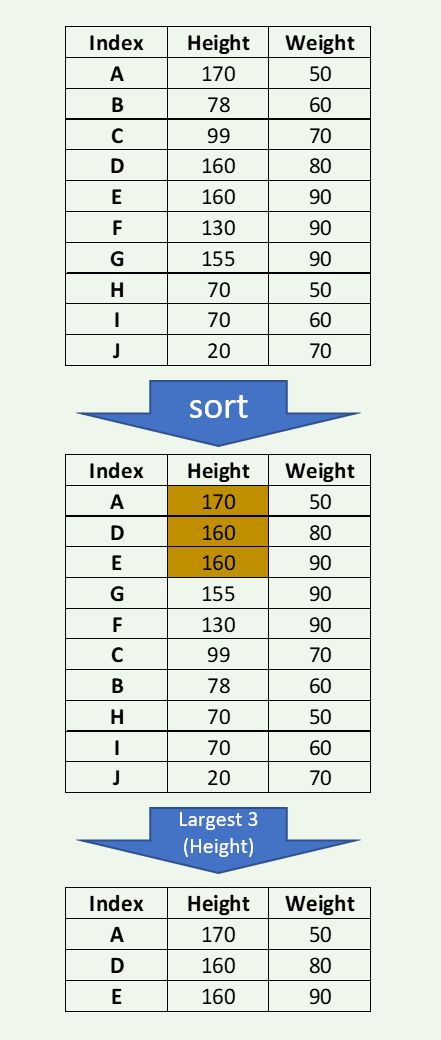
В приведенном ниже примере показаны три самых больших значения из DataFrame из 10 наблюдений.
import pandas as pd
import numpy as np
df = pd.DataFrame({'HEIGHT': [170,78,99,160,160,130,155,70,70,20],
'WEIGHT': [50,60,70,80,90,90,90,50,60,70]},
index=['A','B','C','D','E','F','G','H','I','J'])
print(df)
HEIGHT WEIGHT
A 170 50
B 78 60
C 99 70
D 160 80
E 160 90
F 130 90
G 155 90
H 70 50
I 70 60
J 20 70
dfl = df.nlargest(3,'HEIGHT')
print(dfl)
HEIGHT WEIGHT
A 170 50
D 160 80
E 160 90
Если есть связь, то есть несколько вариантов, которые можно разрешить с помощью «first», «last», «all» (по умолчанию «first»). Сохраняйте все случаи. Мы попытаемся найти две самые большие высоты в примерах ниже.
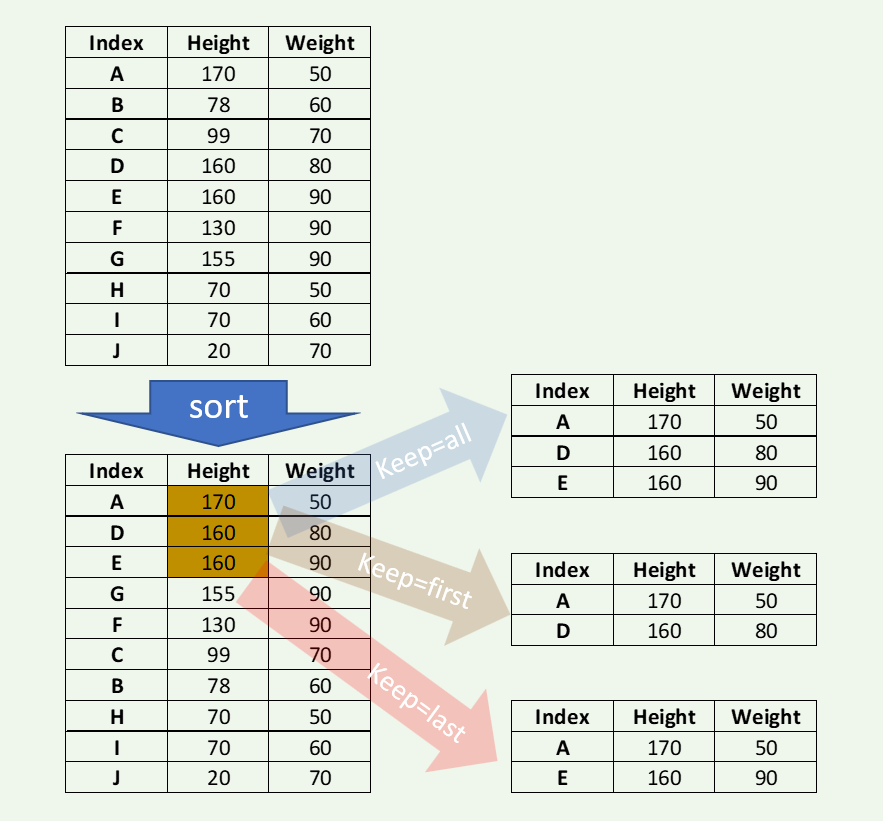
dfl = df.nlargest(2,'HEIGHT',keep='all') print(dfl) HEIGHT WEIGHT A 170 50 D 160 80 E 160 90
Сохраните последнее вхождение.
dfl = df.nlargest(2,'HEIGHT',keep='last') print(dfl) HEIGHT WEIGHT A 170 50 E 160 90
Сохраните первое вхождение.
dfl = df.nlargest(2,'HEIGHT',keep='first') print(dfl) HEIGHT WEIGHT A 170 50 D 160 80
Более подробную информацию о параметрах и других настройках см. в документации Pandas nlargest().
nsmallest() — функция Python Pandas
nsmallest() также работает аналогичным образом, но с учетом самого маленького фильтра. Обратитесь к примеру ниже, в котором осуществляется поиск двух наименьших веса.
import pandas as pd
import numpy as np
df = pd.DataFrame({'HEIGHT': [170,78,99,160,160,130,155,70,70,20],
'WEIGHT': [50,60,70,80,90,90,90,50,60,70]},
index=['A','B','C','D','E','F','G','H','I','J'])
print(df)
HEIGHT WEIGHT
A 170 50
B 78 60
C 99 70
D 160 80
E 160 90
F 130 90
G 155 90
H 70 50
I 70 60
J 20 70
dfs = df.nsmallest(3,'WEIGHT')
print(dfs)
HEIGHT WEIGHT
A 170 50
H 70 50
B 78 60
Более подробную информацию о параметрах и других настройках см. в документации Pandas nsmallest.