
Содержание страницы
Введение. Почему в сфере работы с данными важно уделять внимание очистке данных и качеству данных?
Независимо от вашего опыта работы с данными и построения отчетности — плохие данные практически всегда приводят к неверным решениям.
Независимо от класса информационных систем, профессиональности специалистов по работе с данными, всегда выполняется условие:
Мусор на входе => мусор на выходе.
На качество данных в первую очередь влияют бизнес-процессы, которые организованы в компании по занесению бизнес-сущностей в информационную систему.
Например, как вводятся накладные, как разносятся накладные по платежкам, как выставляются счета. Все ли взаимосвязано для расчета дебиторской задолженности в автоматическом режиме и т.д.
За все это как раз и отвечают бизнес-процессы. Если компания маленькая, то все можно собрать в ручном режиме и бизнес-процессы (точнее их отсутствие) не оказывают большого влияния на бизнес. Но для среднего и крупного бизнеса бизнес-процессы по занесению и ведению информации — очень критичный вид деятельности.
Для любого специалиста по работе с данными очень важным «параметром деятельности» является авторитет данных, заработать который зачастую не так-то просто, а вот потерять его можно очень быстро.
Если Вы на основе грязных данных разработаете отчеты, а потом скажете своей компании сделать что-то с этими результатами, которые окажутся неверными, то у Вас будет много неприятностей!
Неверные или противоречивые данные приводят к ложным выводам. То, насколько хорошо вы очищаете и понимаете данные, оказывает большое влияние на качество результатов.
Зачастую простой алгоритм может превзойти сложный алгоритм только потому, что ему были предоставлены более качественные данные.
Качество данных превосходит модные алгоритмы.
Что это означает качество данных? Каковы показатели качества данных?
Прежде чем предпринимать какие-либо действия, важно понять Вашу цель. Что Вы пытаетесь достичь, куда Вы хотите попасть в конце пути?
Качество данных — Data Quality (Validity, Accuracy, Completeness, Consistency, Uniformity)
Существует много определений качества данных, в общем, качество данных — это оценка того, насколько данные пригодны для использования и соответствуют его контексту обслуживания. Многие факторы помогают измерять качество данных, такие как: Согласованность данных, Точность данных, Уникальность данных, Полнота данных, Своевременность данных, Доступность и т.д.
Достоверность данных — Validity
Степень, в которой данные соответствуют определенным бизнес-правилам или ограничениям.
- Ограничения типа данных (Data-Type Constraints): значения в определенном столбце должны иметь определенный тип данных, например, логическое, числовое, формат даты и т.д.
- Ограничения диапазона (Range Constraints): как правило, числа или даты должны попадать в определенный диапазон.
- Обязательные ограничения (Mandatory Constraints): некоторые столбцы не могут быть пустыми.
- Ограничения уникальности (Unique Constraints): поле или комбинация полей должны быть уникальными в наборе данных.
- Ограничения Set-Membership: значения столбца происходят из набора дискретных значений, например, пол человека может быть «мужской» или «женский». Т.е. фиксированный, редко изменяемый набор значений (или никогда не изменяющийся).
- Ограничения внешнего ключа: как и в реляционных базах данных, столбец внешнего ключа не может иметь значение, которого нет в указанном первичном ключе.
- Шаблоны регулярных выражений: текстовые поля, которые должны быть в определенном шаблоне. Например, для телефонных номеров может потребоваться шаблон (999) 999–9999.
- Проверка между полями (Cross-field validation): должны выполняться определенные условия, охватывающие несколько полей. Например, дата выписки пациента из больницы не может быть раньше даты госпитализации.
Точность — Accuracy
Степень, в которой данные близки к истинным значениям.
Хотя определение всех возможных допустимых значений позволяет легко обнаружить недействительные значения, это не означает, что они являются точными.
Действительный почтовый адрес не может существовать на самом деле. А действительный цвет глаз человека, скажем, синий, может быть действительным, но не соответствовать реальности.
Еще одна вещь, которую следует отметить, это разница между достоверностью и точностью. Сказать, что вы живете на земле, на самом деле правда. Но не точно. Где на земле? Точнее сказать, что вы живете по определенному адресу.
Завершенность — Completeness
Степень, в которой все необходимые данные известны.
Отсутствие данных случается по разным причинам. Можно смягчить эту проблему, по возможности, задавая вопрос первоисточнику, скажем, повторное интервьюирование человека.
Скорее всего, субъект либо даст другой ответ, либо ответ будет трудно снова найти.
Консистенция — Consistency
Степень соответствия данных в одном наборе данных или в нескольких наборах данных.
Несоответствие возникает, когда два значения в наборе данных противоречат друг другу.
Допустимый возраст, скажем, 10, может не совпадать с семейным положением, скажем, в разводе. Клиент записывается в две разные таблицы с двумя разными адресами.
Какой из них является правдой?
Единообразие — Uniformity
Степень, в которой данные указываются с использованием одной и той же единицы измерения.
Вес может быть записан в фунтах или килограммах. Дата может соответствовать формату США или европейскому формату. Валюта иногда в долларах, а иногда в иенах.
И поэтому данные должны быть преобразованы в одну единицу измерения.
Рабочий процесс — Workflow (inspection, cleaning, verifying, reporting)
Рабочий процесс представляет собой последовательность из трех этапов, направленных на получение высококачественных данных, с учетом всех критериев, о которых мы говорили.
- Проверка (Inspection): обнаружение неожиданных, неправильных и противоречивых данных.
- Очистка (Cleaning): исправить или удалить обнаруженные аномалии.
- Проверка (Verifying): После очистки результаты проверяются для проверки правильности.
- Отчетность (Reporting): записывается отчет об изменениях и качестве сохраненных данных.
То, что вы видите как последовательный процесс, на самом деле является итеративным, бесконечным процессом. Можно переходить от проверки к проверке, когда обнаруживаются новые недостатки в данных.
Проверка — Inspection
Проверка данных занимает много времени и требует использования многих методов для исследования основных данных для обнаружения ошибок. Вот некоторые из них:
Профилирование данных — Data profiling
Сводные статистические данные о данных, которые называются профилирование данных, очень полезно, чтобы дать общее представление о качестве данных.
Например, проверьте, соответствует ли определенный столбец определенным стандартам или образцу. Столбец данных записан в виде строки или числа?
Сколько значений пропущено? Сколько уникальных значений в столбце и какого их распределение? Связан ли этот набор данных с другим набором данных?
Зрительные — Visualizations
Анализируя и визуализируя данные с использованием статистических методов, таких как среднее значение, стандартное отклонение, диапазон или квантили, можно найти значения, которые являются неожиданными и, наиболее вероятно, ошибочными.
Например, визуализируя средний доход по странам, можно увидеть, что есть некоторые выбросы.

В некоторых странах есть люди, которые зарабатывают намного больше, чем кто-либо другой. Эти выбросы заслуживают изучения, но не обязательно, это это неверные данные.
Пакеты программ — Software packages
Несколько пакетов программного обеспечения или библиотек, доступных на вашем языке, позволят вам указать ограничения и проверить данные на предмет нарушения этих ограничений.
Более того, они могут не только создать отчет о том, какие правила были нарушены и сколько раз, но также создать график того, какие столбцы связаны с какими правилами.

 Возраст, например, не может быть отрицательным, а значит и рост. Другие правила могут включать несколько столбцов в одной строке или в наборах данных.
Возраст, например, не может быть отрицательным, а значит и рост. Другие правила могут включать несколько столбцов в одной строке или в наборах данных.
Очистка — Cleaning
Очистка данных включает различные методы, основанные на проблемах и типах данных. Различные методы могут быть применены с каждым атрибутом данных, но имеют свои собственные особенности применения.
В целом, неверные данные либо удаляются, исправляются, либо присваиваются.
Нерелевантные данные — Irrelevant data
Нерелевантные данные — это те, которые на самом деле не нужны и не вписываются в контекст проблемы, которую мы пытаемся решить.
Например, если бы мы анализировали данные об общем состоянии здоровья населения, номер телефона не был бы необходим.
Точно так же, если бы вы были заинтересованы только в одной конкретной стране, вы не хотели бы включать в набор данных все другие страны. Или изучать только тех пациентов, которые ходили на операцию, мы бы не включали всех пациентов клиники.
Только если вы уверены, что часть данных не важна, вы можете удалить ее. В противном случае изучите матрицу корреляции между атрибутами объекта.
И даже если вы не заметили никакой корреляции, вы должны спросить кого-то, кто является экспертом в области. Вы никогда не знаете, что функция, которая кажется неактуальной, может быть очень актуальной с точки зрения предметной области, например с клинической точки зрения.
Дубликаты — Duplicates
Дубликаты — это значения, которые повторяются в вашем наборе данных (повторяться могут как транзакции, так и сущности в различных справочниках).
Дублирование часто случается, когда, например,
- Данные объединены из разных источников
- Пользователь может дважды нажать кнопку «Отправить», думая, что форма фактически не была отправлена.
- Запрос на онлайн-бронирование был подан дважды, исправляя неверную информацию, которая была введена случайно в первый раз.
Распространенным симптомом является случай, когда два пользователя имеют одинаковый идентификационный номер. Или одна и та же статья была отменена дважды.
И поэтому они просто должны быть удалены.
Тип преобразования — Type conversion
Убедитесь, что числа хранятся в виде числовых типов данных. Дата должна храниться в виде объекта даты или метки времени Unix (количество секунд) и т.д.
Категориальные значения могут быть преобразованы в/из чисел при необходимости.
Это можно быстро определить, взглянув на типы данных каждого столбца в сводке (мы обсуждали выше).
Предупреждение: значения, которые нельзя преобразовать в указанный тип, следует преобразовать в значение NA (или любое другое) с отображением предупреждения. Это указывает на неправильное значение, которое должно быть исправлено.
Синтаксические ошибки — Syntax errors
Удалить пробелы: следует удалить лишние пробелы в начале или конце строки.
" hello world " => "hello world"
Строки заполнения: строки могут быть дополнены пробелами или другими символами до определенной ширины. Например, некоторые числовые коды часто представлены с предшествующими нулями, чтобы они всегда имели одинаковое количество цифр.
313 => 000313 (6 digits)
Исправьте опечатки: строки могут быть введены разными способами, и неудивительно, что могут быть ошибки.
Gender m Male fem. FemalE Femle
Считается, что эта категориальная переменная имеет 5 разных классов, а не 2, как ожидалось: мужской и женский, поскольку каждое значение различно.
Bar plot полезно визуализировать все уникальные значения. Можно заметить, что некоторые значения различны, но означают одно и то же, то есть «information_technology» и «IT». Или, возможно, разница только в заглавных буквах, то есть в «other» и «Other».
Следовательно, наша обязанность состоит в том, чтобы по приведенным выше данным определить, является ли каждое значение мужским или женским. Как мы можем сделать это?.
Первое решение состоит в том, чтобы вручную сопоставить каждое значение с «мужской» или «женский».
dataframe['gender'].map({'m': 'male', fem.': 'female', ...})
Второе решение — использовать сопоставление с образцом. Например, мы можем искать вхождение m или M в поле в начале строки.
re.sub (r "\ ^ m \ $", ' Male ', ' male ', flags = re. IGNORECASE )
Третье решение заключается в использовании нечеткого сопоставления: алгоритм, который определяет расстояние между ожидаемой строкой(-ами) и каждой из заданных. Его базовая реализация подсчитывает, сколько операций необходимо, чтобы превратить одну строку в другую.
Gender male female m 3 5 Male 1 3 fem. 5 3 FemalE 3 2 Femle 3 1
Кроме того, если у вас есть переменная, такая как название города, вы подозреваете, что опечатки или похожие строки должны обрабатываться одинаково.
Например, “lisbon” можно ввести как “lisboa”, “lisbona”, “Lisbon”, и т.д.
City Distance from "lisbon" lisbon 0 lisboa 1 Lisbon 1 lisbona 2 london 3 ...
Если это так, то мы должны заменить все значения, которые означают одно и то же, на одно уникальное значение. В этом случае замените первые 4 строки на «lisbon».
Следите за значениями, такими как «0», «Не применимо», «NA», «None», «Null» или «INF», они могут означать одно и то же: значение отсутствует.
Стандартизация данных
Наша обязанность — не только распознать опечатки, но и поместить каждое значение в один и тот же стандартизированный формат.
Для строк убедитесь, что все значения указаны в нижнем или верхнем регистре.
Для числовых значений убедитесь, что все значения имеют определенную единицу измерения.
Высота, например, может быть в метрах и сантиметрах. Разница в 1 метр считается такой же, как разница в 1 сантиметр. Итак, задача здесь состоит в том, чтобы преобразовать высоты в одну единицу.
Для дат, версия для США отличается от европейской версии. Запись даты в качестве метки времени (количество миллисекунд) не совпадает с записью даты в качестве объекта даты.
Масштабирование / Преобразование — Scaling / Transformation
Масштабирование означает преобразование ваших данных таким образом, чтобы они соответствовали определенному масштабу, например 0–100 или 0–1.
Например, баллы по экзамену студента могут быть пересчитаны в процентах (0–100) вместо среднего балла (0–5).
Это также может помочь упростить построение определенных типов данных. Например, мы могли бы хотеть уменьшить асимметрию, чтобы помочь в построении графика (когда есть такое большое количество выбросов). Наиболее часто используемые функции — это log, square root и инверсия.
Масштабирование также может выполняться для данных, которые имеют разные единицы измерения.
Счета учеников на разных экзаменах, скажем, SAT и ACT, не могут сравниваться, поскольку эти два экзамена имеют разную шкалу. Разница в 1 балл SAT считается такой же, как разница в 1 балл ACT. В этом случае нам нужно изменить шкалу SAT и ACT, чтобы взять числа, скажем, между 0–1.
Масштабируя, мы можем построить и сравнить различные оценки.
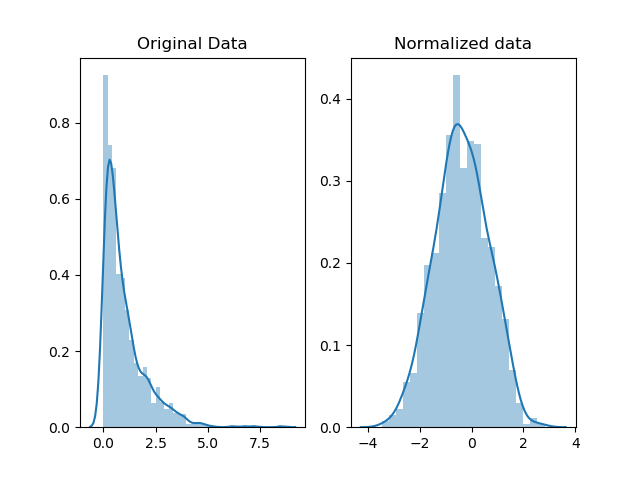
Нормализация — Normalization
В то время как нормализация также изменяет значения в диапазоне от 0 до 1, цель здесь состоит в том, чтобы преобразовать данные так, чтобы они нормально распределялись.
Почему?
В большинстве случаев мы нормализуем данные, если будем использовать статистические методы, основанные на нормально распределенных данных.
Как?
Можно использовать log функцию или, возможно, использовать один из этих методов .
В зависимости от используемого метода масштабирования форма распределения данных может измениться.Например, «Стандартная оценка Z» и «t-статистика Стьюдента» (приведенные в ссылке выше) сохраняют форму, в то время как log функция не может.

Недостающие значения — Missing values
Учитывая тот факт, что отсутствующие значения неизбежны, возникает вопрос: что делать, когда мы сталкиваемся с ними? Игнорирование пропущенных данных — это то же самое, что создание дыр в лодке — она будет тонуть.
Есть три, или, возможно, больше, способов справиться с ними.
— Первый способ. Удаление — Drop.
Если пропущенные значения в столбце встречаются редко и происходят случайным образом, то самое простое и прямое решение — отбросить наблюдения (строки) с пропущенными значениями.
Если большинство значений столбца отсутствуют и встречаются случайным образом, типичным решением является удаление всего столбца.
Это особенно полезно при проведении статистического анализа, поскольку заполнение пропущенных значений может привести к неожиданным или необъективным результатам.
— Второй способ. Внести значение — Impute.
Это значит рассчитать недостающее значение на основе других наблюдений. Есть много способов сделать это.
— Сначала используются статистические значения, такие как среднее значение, медиана. Тем не менее, ни один из них не гарантирует непредвзятых данных, особенно если есть много пропущенных значений.
Среднее значение наиболее полезно, когда исходные данные не искажены, а медиана более устойчива, не чувствительна к выбросам и, таким образом, используется при искажении данных.
В нормально распределенных данных можно получить все значения, которые находятся в пределах 2 стандартных отклонений от среднего. Затем, заполните пропущенные значения, генерируя случайные числа между (mean — 2 * std) & (mean + 2 * std)
rand = np.random.randint(average_age - 2*std_age, average_age + 2*std_age, size = count_nan_age) dataframe["age"][np.isnan(dataframe["age"])] = rand
Второе. Используя линейную регрессию. На основании существующих данных можно рассчитать линию наилучшего соответствия между двумя переменными, скажем, цена дома против размера м².
Стоит отметить, что модели линейной регрессии чувствительны к выбросам.
— в-третьих. Hot-deck: Копирование значений из других похожих записей. Это полезно, только если у вас достаточно доступных данных. И это может быть применено к числовым и категориальным данным.
Можно использовать случайный подход, где мы заполняем отсутствующее значение случайным значением. Сделав этот подход еще на шаг вперед, можно сначала разделить набор данных на две группы (страты) на основе некоторой характеристики, например, пола, а затем заполнить пропущенные значения для разных полов по отдельности, случайным образом.
При последовательном вменении «горячей колоды» столбец, содержащий пропущенные значения, сортируется в соответствии со вспомогательной(-ыми ) переменной(-ами), поэтому записи, имеющие похожие вспомогательные элементы, появляются последовательно. Затем каждое пропущенное значение заполняется значением первой следующей доступной записи.
Что еще интереснее, так это то, что вложение ближайшего соседа, которое классифицирует похожие записи и объединяет их, также может быть использовано. Пропущенное значение затем заполняется путем нахождения первых ? записей, ближайших к записи с пропущенными значениями. Затем значение выбирается из (или вычисляется из) ? ближайших соседей. В случае вычислений могут использоваться статистические методы, такие как среднее (как обсуждалось ранее).
— Третье. Flag.
Некоторые утверждают, что заполнение пропущенных значений приводит к потере информации, независимо от того, какой метод вменения мы использовали.
Это потому, что утверждение о том, что данные отсутствуют, само по себе информативно, и алгоритм должен знать об этом. В противном случае мы просто усиливаем шаблон, уже существующий другими функциями.
Это особенно важно, когда пропущенные данные не случаются случайно. Возьмем, к примеру, проведенный опрос, в котором большинство людей из определенной расы отказываются отвечать на определенный вопрос.
Пропущенные числовые данные можно заполнить, скажем, 0, но эти нули необходимо игнорировать при вычислении любого статистического значения или построении графика распределения.
В то время как категориальные данные могут быть заполнены, скажем, «Отсутствует»: новая категория, которая сообщает, что этот фрагмент данных отсутствует.
— Принимать во внимание …
Отсутствующие значения не совпадают со значениями по умолчанию. Например, ноль можно интерпретировать как отсутствующий или по умолчанию, но не оба.
Отсутствующие значения не являются «неизвестными». Проведенное исследование, в котором некоторые люди не помнят, подвергались ли они издевательствам в школе или нет, должно рассматриваться и обозначаться как неизвестное и не пропущенное.
Каждый раз, когда мы отбрасываем или приписываем значение, мы теряем информацию. Таким образом, пометка может прийти на помощь.
Выпадающие значения — Outliers
Это значения, которые значительно отличаются от всех других наблюдений. Любое значение данных, которое находится на расстоянии более (1,5 * IQR) от квартилей Q1 и Q3, считается выбросом.
Выбросы невиновны, пока их вина не доказана. С учетом сказанного, их не следует удалять, если для этого нет веских причин.
Например, можно заметить некоторые странные, подозрительные значения, которые вряд ли произойдут, и поэтому решает удалить их. Тем не менее, они заслуживают расследования, прежде чем удалить.
Стоит также отметить, что некоторые модели, такие как линейная регрессия, очень чувствительны к выбросам. Другими словами, выбросы могут отбросить модель, из которой собрана большая часть данных.
Ошибки в записях и между наборами данных — In-record & cross-datasets errors
Эти ошибки возникают из-за наличия двух или более значений в одной строке или между наборами данных, которые противоречат друг другу.
Например, если у нас есть набор данных о стоимости жизни в городах. Общая колонка должна быть эквивалентна сумме арендной платы, транспорта и еды.
city rent transportation food total libson 500 20 40 560 paris 750 40 60 850
Точно так же ребенок не может быть женат. Заработная плата работника не может быть меньше рассчитанных налогов.
Та же идея применима к связанным данным в разных наборах данных.
Проверка (Верификация) — Verifying
Когда это сделано, следует проверить правильность, повторно проверив данные и убедившись, что они соблюдают правила и ограничения.
Например, после заполнения отсутствующих данных они могут нарушить любое из правил и ограничений.
Это может потребовать некоторой ручной коррекции, если не возможно иначе.
Составление отчетов — Reporting
Отчет о том, насколько здоровы данные, одинаково важен для очистки.
Как упоминалось ранее, программные пакеты или библиотеки могут генерировать отчеты о внесенных изменениях, какие правила были нарушены и сколько раз.
Помимо регистрации нарушений, следует учитывать причины этих ошибок. Почему они произошли в первую очередь?
Заключительная часть
Независимо от того, насколько надежным и сильным является процесс проверки и очистки, он будет страдать по мере поступления новых данных.
Лучше защититься от болезни, чем тратить время и силы на ее устранение.
Эти вопросы помогают оценить и улучшить качество данных:
Как собираются данные и при каких условиях? Среда, в которой были собраны данные, имеет значение. Окружающая среда включает в себя, помимо прочего, местоположение, время, погодные условия и т.д.
Опрос субъектов по поводу их мнения относительно независимо, пока они находятся на пути к работе не то же самое, в то время как они у себя дома. Пациенты в исследовании, которые испытывают трудности с использованием таблеток для ответа на вопросник, могут отбросить результаты.
Что представляют собой данные? Они включают всех? Только люди в городе? Или, возможно, только те, кто решил ответить, потому что у них было твердое мнение по теме.
Какие методы используются для очистки данных и почему? Различные методы могут быть лучше в разных ситуациях или с разными типами данных.
Вы вкладываете время и деньги в улучшение процесса? Инвестиции в людей и процесс так же важны, как и инвестиции в технологии.
Профилирование данных в Python 3 с помощью Pandas
Любой, кто работает с данными в Python, знаком с пакетом pandas. Если это не так, pandas — это пакет для большинства данных, отформатированных по строкам и столбцам. Если у вас еще нет библиотеки Pandas, обязательно установите ее, используя pip install в предпочитаемом вами терминале:
pip install pandas
Теперь давайте посмотрим, что может сделать для нас реализация pandas по умолчанию:
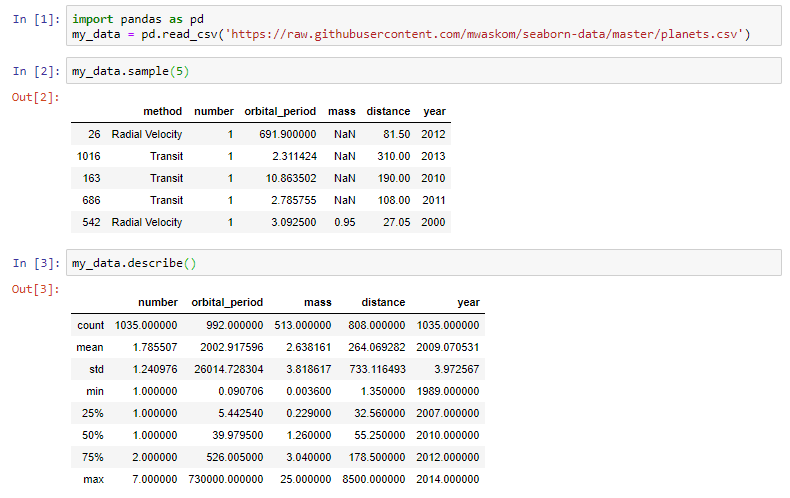
Любой ‘DataFrame’ в Pandas имеет метод .describe(), который возвращает приведенную выше сводку. Однако обратите внимание, что в выходных данных этого метода категориальные переменные отсутствуют. В приведенном выше примере столбец «method» полностью исключен из вывода!
Pandas Data Profiling
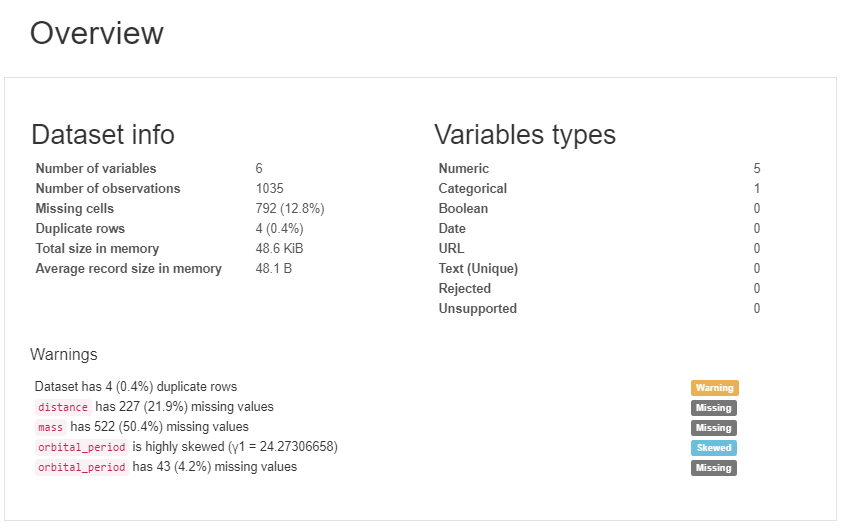
В этом разделе будет описана библиотека «Pandas Profiling». Эта библиотека формирует многостраничный отчет (на картинке ниже только небольшая часть этого отчета).
Как бы вам понравилось, если бы я сказал вам, что смогу создать следующую статистику всего с 3 строками Python (фактически, только с 1 строкой, если мы не посчитаем наш импорт.) :
- Основы : тип, уникальные значения, пропущенные значения
- Квантильная статистика, такая как минимальное значение, Q1, медиана, Q3, максимум, диапазон, межквартильный диапазон
- Описательные статистические данные, такие как среднее значение, мода, стандартное отклонение, сумма, среднее абсолютное отклонение, коэффициент вариации, эксцесс, асимметрия
- Наиболее частые значения
- Гистограмма
- Выделение корреляций высококоррелированных переменных, матрицы Спирмена, Пирсона и Кендалла
- Матрица отсутствующих значений , счетчик, тепловая карта и дендрограмма отсутствующих значений
(Список функций прямо из GitHub для профилирования Pandas )
Используя пакет Pandas Profiling!
Чтобы установить пакет Pandas Profiling, просто используйте pip install в своем терминале:
pip install pandas_profiling
Опытные аналитики данных на первый взгляд могут посмеяться над тем, что они пушистые и кричащие, но это, безусловно, может быть полезно для быстрого получения непосредственного представления о ваших данных:

Первое, что вы увидите, это обзор (см. Рисунок выше), который дает вам очень высокую статистику ваших данных и переменных, а также предупреждения, такие как высокая корреляция между переменными, высокая асимметрия и многое другое.
Но это даже не близко ко всему. Прокручивая вниз, мы обнаруживаем, что этот отчет состоит из нескольких частей. Просто показывать результат этого 1-линейного с картинками не будет справедливо, поэтому я вместо этого сделал GIF:
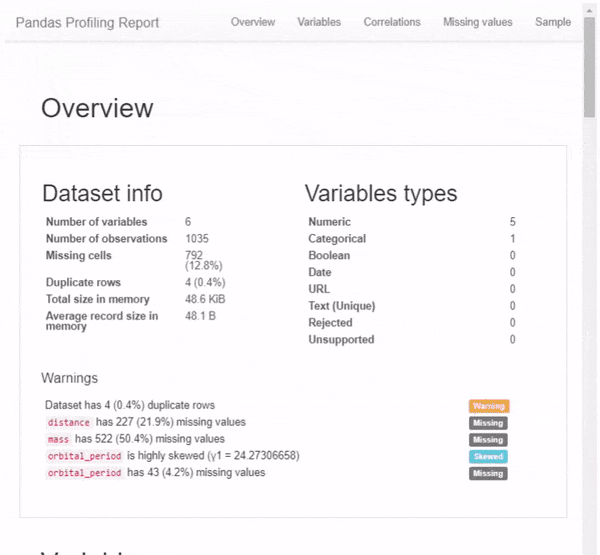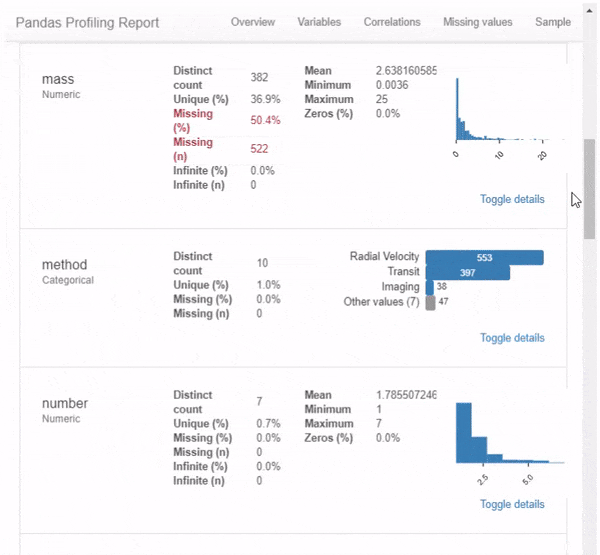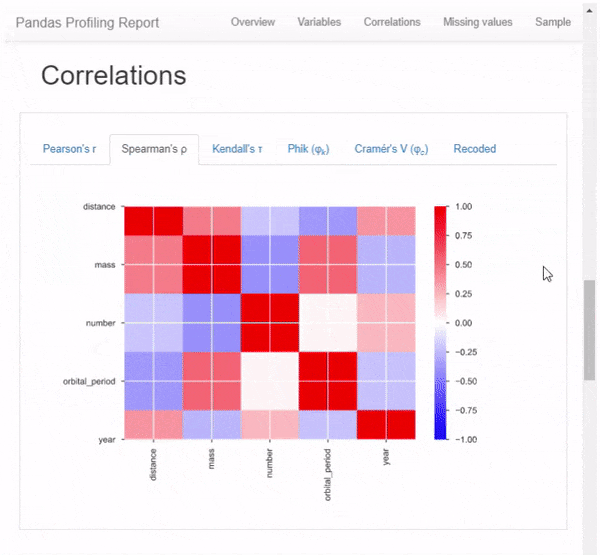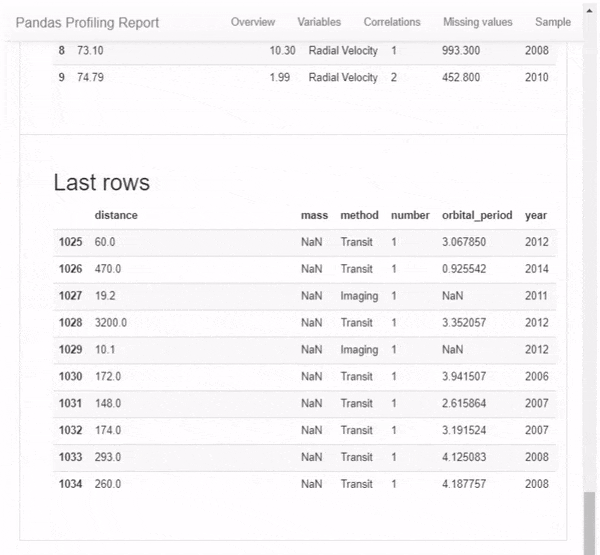
Я настоятельно рекомендую вам изучить возможности этого пакета самостоятельно — в конце концов — это всего лишь одна строка кода, и вы можете найти ее полезной для дальнейшего анализа данных.
import pandas as pd
import pandas_profiling
pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/planets.csv').profile_report()