
Содержание страницы
Вводная часть по Python 3 Tutorial — Data Wrangling
Биткойн и криптовалюта сейчас в тренде… но как специалисты по данным, мы эмпиристы, верно? Мы не хотим просто поверить на слово другим… мы хотим посмотреть на данные из первых рук! В этом уроке будут описаны общие и мощные методы обработки данных в Python.
Python 3 Tutorial — Data Wrangling
Вообще говоря, обработка данных (Data Wrangling) — это процесс преобразования, агрегирования, разделения или иного преобразования ваших данных из одного формата в более подходящий.
Например, мы хотим провести пошаговый анализ очень элементарной торговой стратегии, которая выглядит следующим образом:
- В начале каждого месяца мы покупаем криптовалюту, которая имела наибольший прирост цены за последние 7, 14, 21 или 28 дней. Мы хотим оценить каждое из этих временных окон.
- Затем мы держим ровно 7 дней и продаем нашу позицию. Обратите внимание: это целенаправленно простая стратегия, которая предназначена только для иллюстративных целей.
Как мы будем оценивать эту стратегию?
Это хороший вопрос для демонстрации методов обработки данных, потому что вся тяжелая работа заключается в преобразовании вашего набора данных в правильный формат. Когда у вас есть соответствующая аналитическая базовая таблица (analytical base table, ABT), ответить на вопрос становится просто.
Чем это руководство не является:
Это не руководство по инвестиционным или торговым стратегиям, и не призыв за или против торговли криптовалютами. Потенциальные инвесторы должны самостоятельно формировать свои взгляды, но в этом руководстве будут представлены инструменты для этого.
Опять же, основное внимание в этом руководстве уделяется методам обработки данных и возможности преобразования необработанных наборов данных в форматы, которые помогут вам ответить на интересные вопросы.
Быстрый совет, прежде чем мы начнем:
Этот учебник предназначен для быстрого ознакомления, и он не будет охватывать ни одну тему слишком подробно. Ознакомьтесь дополнительно с Tutorial по библиотеке Pandas.
Содержание учебника по обработке данных Python — Data Wrangling Tutorial
Вот шаги, которые мы пройдем в рамках нашего анализа:
- Настройка среды.
- Импорт библиотек и наборов данных.
- Первичное знакомство с данными.
- Фильтр нежелательных наблюдений (подмножеств).
- Вращение набора данных — Pivot the dataset.
- Сдвиг развернутого набора данных — Shift the pivoted dataset.
- Melt сдвинутого набора данных — Melt the shifted dataset.
- Уменьшение-объединение (Reduce-merge) melted data.
- Агрегация данных с помощью group-by.
Шаг 1. Настройка среды программирования Python
Сначала убедитесь, что на вашем компьютере установлено ПО:
- Python 2.7+ или Python 3
- Pandas
- Jupyter Notebook (необязательно, но рекомендуется)
Мы настоятельно рекомендуем установить дистрибутив Anaconda, который поставляется со всеми этими пакетами. Просто следуйте инструкциям на этой странице загрузки.
Jupyter Notebook – это бесплатная интерактивная оболочка для языка программирования Python, позволяющая объединить код, изображения, комментарии, формулы и графики/диаграммы.
После установки Anaconda запустите Jupyter Notebook (Anaconda3):
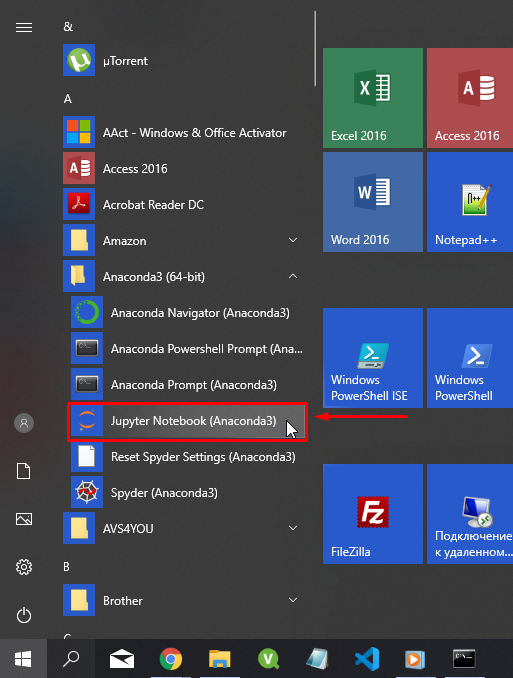
Откроется окно в браузере. В нем создайте новое окно Python3:
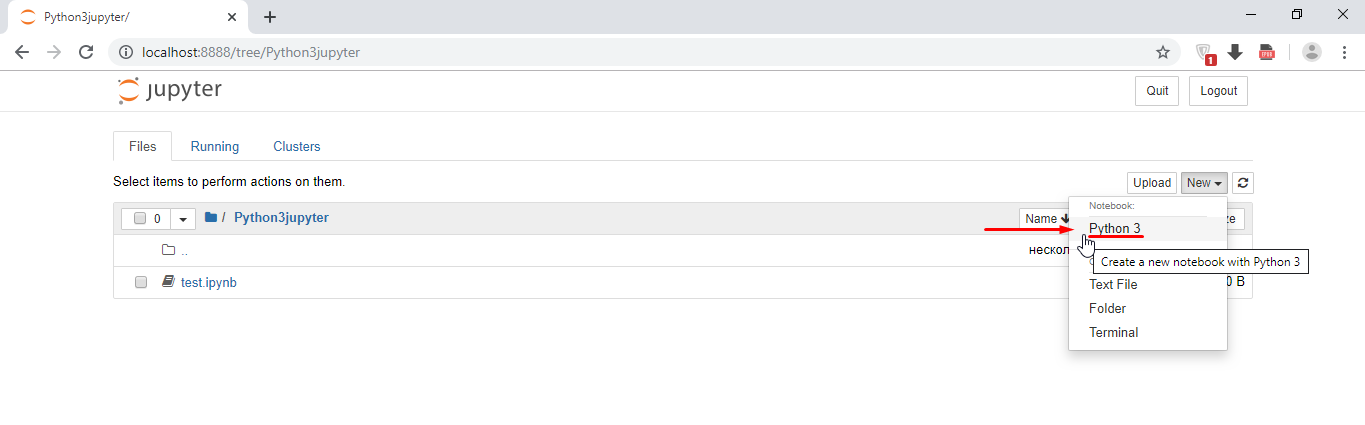
Откроется новая вкладка, на ней Вы можете поменять название документа.
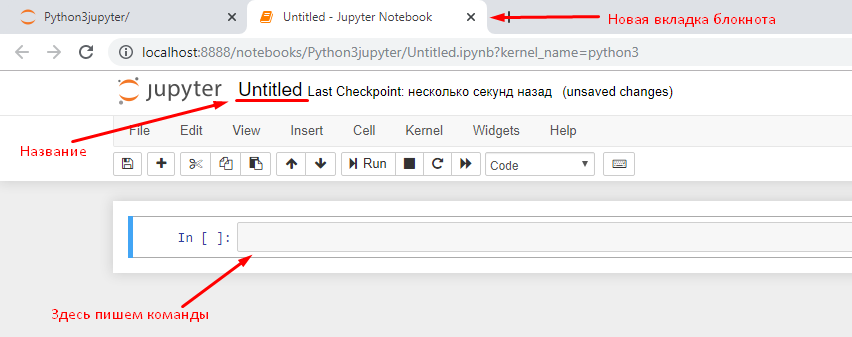
Интерфейс Jupyter Notebook
В Jupyter Notebook есть два важных термина: cells (ячейки) и kernels (ядра) являются ключом как к пониманию Jupyter.
- kernel (Ядро) – это «вычислительный движок», который выполняет код, содержащийся в документе Notebook.
- cell (Ячейка) – это контейнер для текста, который будет отображаться в Notebook, или код, который будет выполняться ядром записной книжки.
Запуск и прерывание выполнения кода в Jupyter Notebook
Если ваша программа зависла, то можно прервать ее выполнение выбрав на панели меню пункт Kernel -> Interrupt.
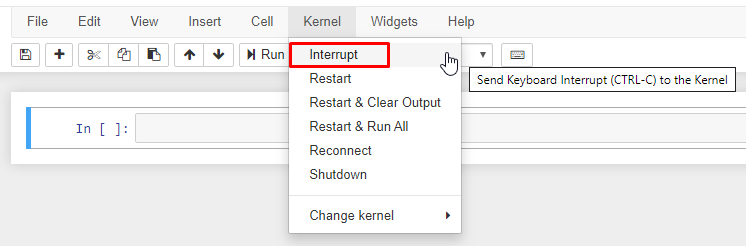
Для добавления новой ячейки используйте Insert->Insert Cell Above и Insert->Insert Cell Below.
Для запуска ячейки используете команды из меню Cell, либо следующие сочетания клавиш:
- Ctrl+Enter – выполнить содержимое ячейки.
- Shift+Enter – выполнить содержимое ячейки и перейти на ячейку ниже.
- Alt+Enter – выполнить содержимое ячейки и вставить новую ячейку ниже.
Шаг 2: Импортируем библиотеки и загружаем набор данных
Сначала мы импортируем библиотеку Pandas (лучшая библиотека для обработки реляционных наборов данных в табличном формате).
Библиотеке Pandas мы дадим alias (псевдоним). Позже мы сможем вызывать библиотеку с помощью pd.
# Pandas for managing datasets import pandas as pd
Далее, давайте немного подправим параметры отображения чисел. Во-первых, давайте отобразим числа с плавающей точкой с двумя десятичными разрядами, чтобы сделать таблицы менее загруженными. Не волнуйтесь — это только настройка дисплея, которая не снижает основную точность. Давайте также расширим ограничения на количество отображаемых строк и столбцов.
# Display floats with 2 decimal places
pd.options.display.float_format = '{:,.2f}'.format
# Expand display limits
pd.options.display.max_rows = 200
pd.options.display.max_columns = 100
В этом уроке мы будем использовать набор данных о ценах Brave New Coin и распространяемый в Quandl. Полная версия отслеживает индексы цен для 1900+ фиат-крипто трейдинговых пар, но требует премиальной подписки, поэтому мы предоставили небольшую выборку с небольшим количеством криптовалют.
Чтобы использовать набор данных в своей программе скачайте файл BNC2_sample.csv.
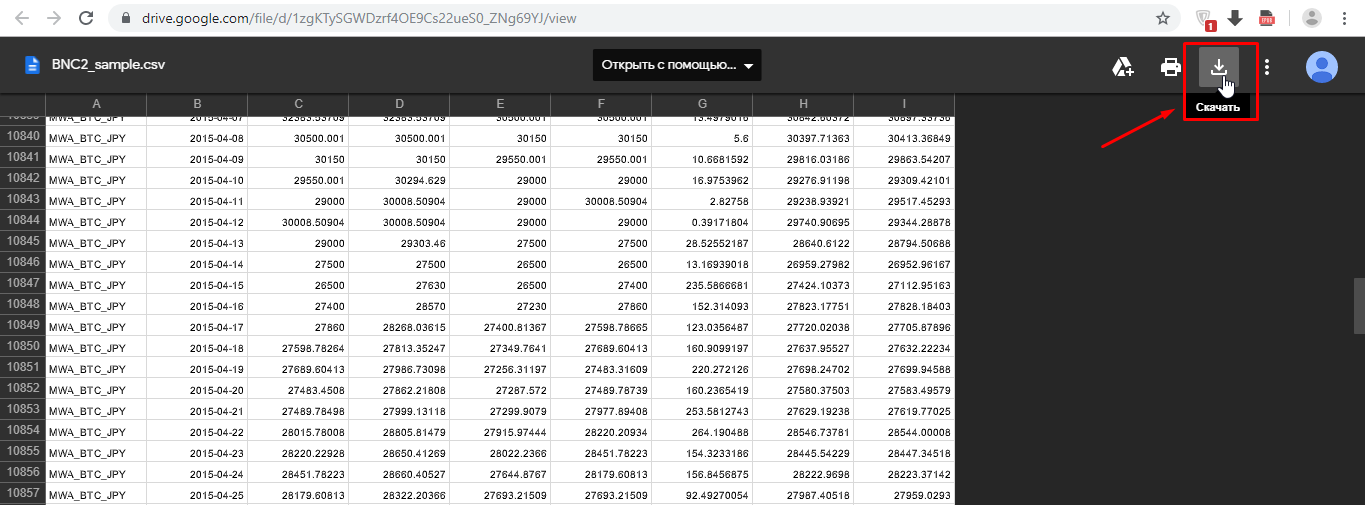
После того, как вы скачали набор данных, разместите его в том же каталоге, что и сохраненный блокнот.
Набор данных можно загрузить как непосредственно в директорию на диске в windows:
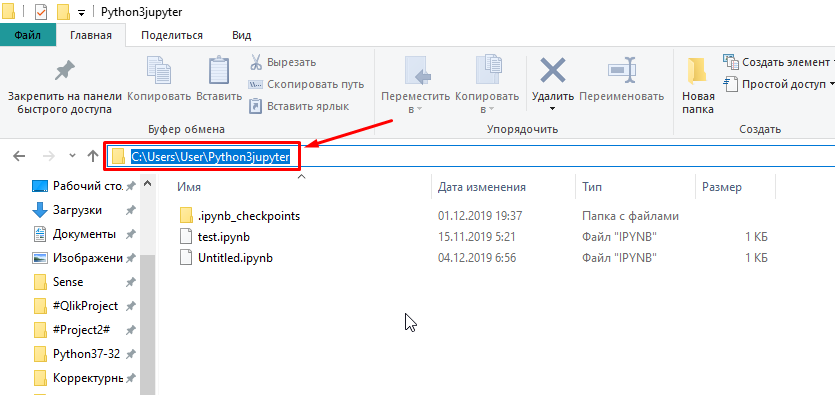
Также можно загрузить файл из интерфейса Jupyter:

Если Вы все правильно сделали, то файл разместится рядом с вашим проектом:
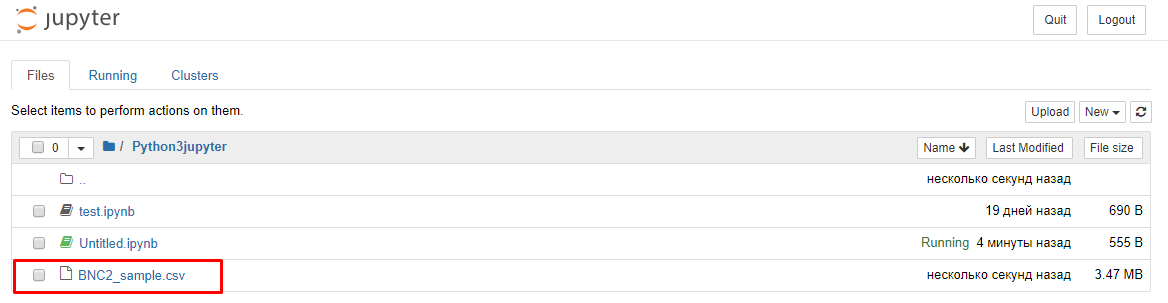
Далее запускаем следующий код, чтобы прочитать набор данных из csv файла и создать DataFrame (набор данных библиотеки Pandas). Далее выводим примеры записей.
# Read BNC2 sample dataset
df = pd.read_csv('BNC2_sample.csv',
names=['Code', 'Date', 'Open', 'High', 'Low',
'Close', 'Volume', 'VWAP', 'TWAP'])
# Display first 5 observations
df.head()
Запускаем наш скрипт и получим следующий результат:
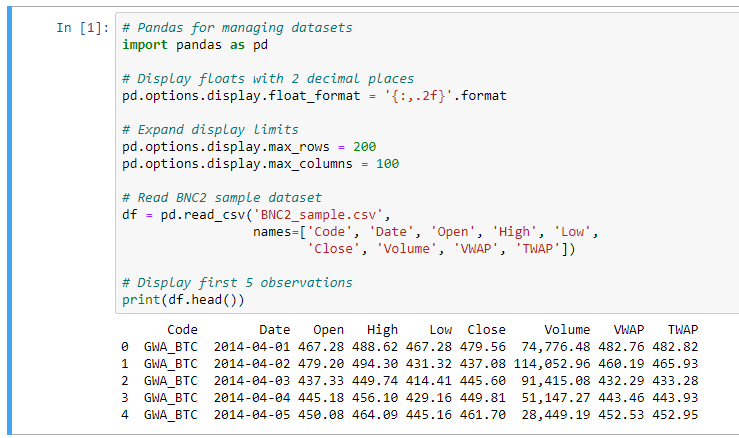
Обратите внимание, что мы используем аргумент names = для pd.read_csv(), чтобы установить наши собственные имена столбцов, потому что исходный набор данных не содержит заголовка таблицы (наименования столбцов).
Словарь данных (для кода GWA_BTC):
- Date: день, в который были рассчитаны значения индекса.
- Open: дневной индекс цен на биткойны в долларах США.
- High: максимальное значение индекса цен на биткойны в долларах США за день на дату.
- Low: самое низкое значение индекса цен на биткойны в долларах США за день на дату.
- Close: дневной индекс цен на биткойны в долларах США.
- Volume: объем торговли биткойнами в этот день.
- VWAP: средневзвешенная цена за биткойн, торгуемая в этот день.
- TWAP: средневзвешенная по времени цена Биткойна, торгуемая в этот день.
Шаг 3: Понимание данных. Изучение данных
Одна из наиболее распространенных причин для обработки данных — это когда «слишком много» информации упаковано в одну таблицу, особенно при работе с данными временных рядов.
Как правило, все наблюдения (записи/транзакции) должны быть эквивалентны по степени детализации и в единицах измерения.
Существуют исключения, но по большей части это правило поможет вам избежать многих головных болей.
- Эквивалентность в гранулярности — например, вы можете иметь 10 строк данных по 10 разным криптовалютам. Однако у вас не должно быть 11-й строки со средними или суммарными значениями из других 10 строк. Эта 11-я строка будет агрегацией и, следовательно, не эквивалентна по гранулярности с другими 10.
- Эквивалентность в единицах — у вас может быть 10 строк с ценами в долларах США, собранных на разные даты. Однако у вас не должно быть еще 10 строк с ценами, указанными в евро. Любые агрегаты, распределения, визуализации или статистика станут бессмысленными.
Наш текущий набор необработанных данных нарушает оба эти правила!
Данные, хранящиеся в CSV-файлах или базах данных, часто имеют формат «стопки» или «запись». Они используют один столбец «Код» в качестве универсального для метаданных. Например, в примере набора данных у нас есть следующие коды:
# Unique codes in the dataset print( df.Code.unique() )
Результат выполнения:
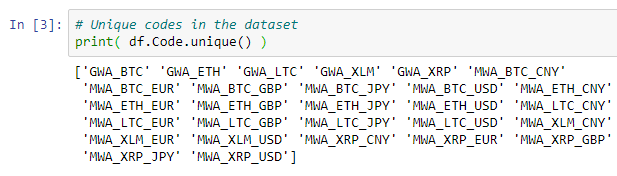
Во-первых, посмотрите, что некоторые коды начинаются с GWA, а другие — с MWA? На самом деле это абсолютно разные типы индикаторов согласно странице документации.
- MWA означает «средневзвешенное значение по рынку», и они показывают региональные цены. Существует несколько кодов MWA для каждой криптовалюты, по одному на каждую местную фиатную валюту.
- С другой стороны, GWA означает «средневзвешенное значение по всему миру», которое показывает глобально проиндексированные цены. Таким образом, GWA — это совокупность MWA, а не эквивалентность по гранулярности. (Примечание: в образец набора данных включен только поднабор региональных кодов MWA)
Например, давайте посмотрим на коды Биткойн в ту же дату:
# Example of GWA and MWA relationship df[df.Code.isin(['GWA_BTC', 'MWA_BTC_JPY', 'MWA_BTC_EUR']) & (df.Date == '2018-01-01')]
Результат выполнения команды:
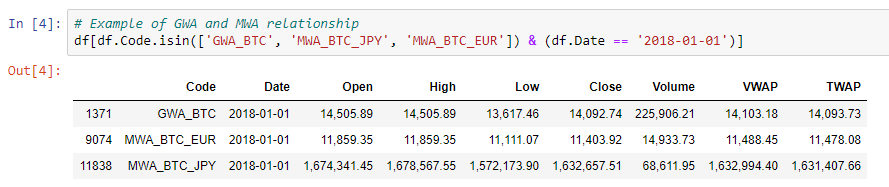 Как видите, у нас есть несколько записей для криптовалюты на данную дату. Чтобы еще больше усложнить ситуацию, региональные данные MWA выражены в местной валюте (то есть в неэквивалентных единицах), поэтому вам также понадобятся исторические обменные курсы.
Как видите, у нас есть несколько записей для криптовалюты на данную дату. Чтобы еще больше усложнить ситуацию, региональные данные MWA выражены в местной валюте (то есть в неэквивалентных единицах), поэтому вам также понадобятся исторические обменные курсы.
Наличие разных уровней детализации и/или разных единиц делает анализ в лучшем случае громоздким, а в худшем — невозможным.
К счастью, как только мы обнаружили эту проблему, исправить ее на самом деле тривиально!
Шаг 4: Отфильтруем нежелательные наблюдения (записи/строки)
Одним из самых простых, но наиболее полезных методов обработки данных является удаление нежелательных наблюдений.
На предыдущем этапе мы узнали, что коды GWA являются агрегированием региональных кодов MWA. Поэтому для проведения нашего анализа нам нужно только сохранить глобальные коды GWA:
# Number of observations in dataset print( 'Before:', len(df) ) # Get all the GWA codes gwa_codes = [code for code in df.Code.unique() if 'GWA_' in code] # Only keep GWA observations df = df[df.Code.isin(gwa_codes)] # Number of observations left print( 'After:', len(df) )
Результат работы скрипта Python 3 в Jupyter Notebook:
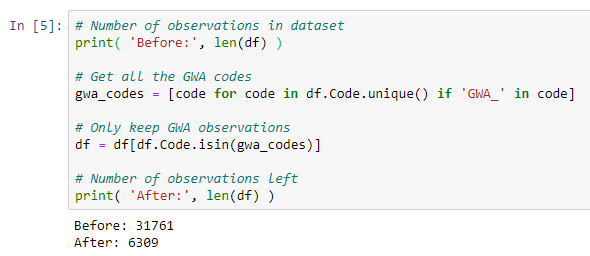
Теперь, когда у нас остались только коды GWA, все наши наблюдения эквивалентны по степени детализации и единицах измерения. Мы можем продолжать обработку данных.
Шаг 5: Pivot the dataset — Развернем набор данных
Далее, чтобы проанализировать нашу стратегию торговли по импульсам, описанную выше, для каждой криптовалюты нам потребуется рассчитать доходность за предыдущие 7, 14, 21 и 28 дней для первого дня каждого месяца.
Тем не менее, было бы очень сложно производить этот расчет с текущим «сложенным» набором данных («stacked» dataset). Это потребует написания вспомогательных функций, циклов и множества условной логики. Вместо этого мы будем использовать более элегантный подход.
Во-первых, мы повернем набор данных, оставив только один ценовой столбец. В этом уроке мы сохраним столбец VWAP (средневзвешенная цена).
# Pivot dataset pivoted_df = df.pivot(index='Date', columns='Code', values='VWAP') # Display examples from pivoted dataset pivoted_df.tail()
Результат:
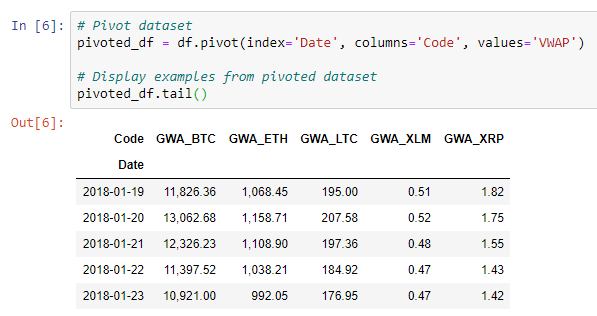
Как видите, каждый столбец в нашем сводном наборе данных (pivoted dataset) теперь представляет цену за одну криптовалюту, а каждая строка содержит цены за одну дату. Все объекты теперь выровнены по дате.
Шаг 6: Сдвиг развернутого набора данных — Shift the pivoted dataset
Чтобы легко рассчитать returns за предыдущие 7, 14, 21 и 28 дней, мы можем использовать метод shift из библиотеки Pandas.
Эта функция сдвигает индекс dataframe на указанное количество периодов. Например, вот что происходит, когда мы сдвигаем наш pivoted dataset на 1:
print( pivoted_df.tail(3) )

print( pivoted_df.tail(3).shift(1) )
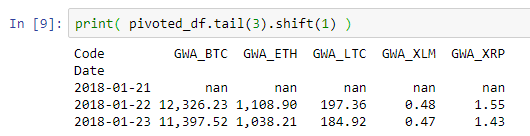
Обратите внимание, как смещенный набор данных теперь имеет значения за 1 день до этого? Мы можем воспользоваться этим, чтобы рассчитать prior returns для 7, 14, 21, 28 дней.
Например, для расчета доходности за 7 дней этого нам понадобится prices_today / prices_7_days_ago - 1.0, что означает:
Рассчитать returns для всех наших периодов так же просто, как написать цикл и сохранить его в словаре:
# Calculate returns over each window and store them in dictionary
delta_dict = {}
for offset in [7, 14, 21, 28]:
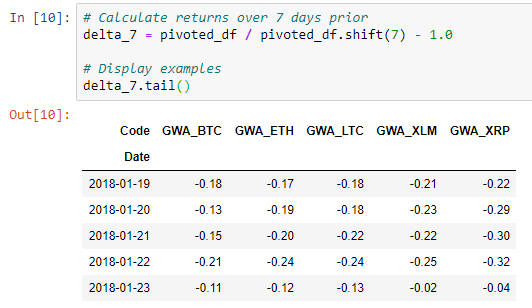
delta_dict['delta_{}'.format(offset)] = pivoted_df / pivoted_df.shift(offset) - 1.0
# Display result "delta_dict"
delta_dict

Полный список результата (out):
{'delta_7': Code GWA_BTC GWA_ETH GWA_LTC GWA_XLM GWA_XRP
Date
2014-04-01 nan nan nan nan nan
2014-04-02 nan nan nan nan nan
2014-04-03 nan nan nan nan nan
2014-04-04 nan nan nan nan nan
2014-04-05 nan nan nan nan nan
... ... ... ... ... ...
2018-01-19 -0.18 -0.17 -0.18 -0.21 -0.22
2018-01-20 -0.13 -0.19 -0.18 -0.23 -0.29
2018-01-21 -0.15 -0.20 -0.22 -0.22 -0.30
2018-01-22 -0.21 -0.24 -0.24 -0.25 -0.32
2018-01-23 -0.11 -0.12 -0.13 -0.02 -0.04
[1394 rows x 5 columns],
'delta_14': Code GWA_BTC GWA_ETH GWA_LTC GWA_XLM GWA_XRP
Date
2014-04-01 nan nan nan nan nan
2014-04-02 nan nan nan nan nan
2014-04-03 nan nan nan nan nan
2014-04-04 nan nan nan nan nan
2014-04-05 nan nan nan nan nan
... ... ... ... ... ...
2018-01-19 -0.29 0.05 -0.23 -0.27 -0.41
2018-01-20 -0.26 0.13 -0.29 -0.26 -0.42
2018-01-21 -0.29 -0.01 -0.32 -0.31 -0.51
2018-01-22 -0.29 -0.13 -0.30 -0.28 -0.52
2018-01-23 -0.31 -0.22 -0.32 -0.24 -0.48
[1394 rows x 5 columns],
'delta_21': Code GWA_BTC GWA_ETH GWA_LTC GWA_XLM GWA_XRP
Date
2014-04-01 nan nan nan nan nan
2014-04-02 nan nan nan nan nan
2014-04-03 nan nan nan nan nan
2014-04-04 nan nan nan nan nan
2014-04-05 nan nan nan nan nan
... ... ... ... ... ...
2018-01-19 -0.22 0.42 -0.24 0.88 0.02
2018-01-20 -0.05 0.60 -0.09 0.57 -0.26
2018-01-21 -0.11 0.51 -0.12 0.47 -0.28
2018-01-22 -0.19 0.36 -0.19 0.05 -0.35
2018-01-23 -0.25 0.13 -0.29 -0.10 -0.39
[1394 rows x 5 columns],
'delta_28': Code GWA_BTC GWA_ETH GWA_LTC GWA_XLM GWA_XRP
Date
2014-04-01 nan nan nan nan nan
2014-04-02 nan nan nan nan nan
2014-04-03 nan nan nan nan nan
2014-04-04 nan nan nan nan nan
2014-04-05 nan nan nan nan nan
... ... ... ... ... ...
2018-01-19 -0.17 0.57 -0.24 1.30 0.65
2018-01-20 -0.13 0.60 -0.27 1.23 0.53
2018-01-21 -0.12 0.65 -0.27 1.22 0.45
2018-01-22 -0.20 0.38 -0.33 1.09 0.30
2018-01-23 -0.31 0.29 -0.37 1.16 0.29
[1394 rows x 5 columns]}
Примечание. Для расчета returns путем смещения набора данных необходимо выполнить 2 допущения:
- наблюдения отсортированы ascending by date и
- отсутствуют пропущенные даты. Этого шага нет в статье, чтобы сделать этот урок лаконичным, рекомендуется проверить это самостоятельно.
Шаг 7: Сплавка смещенного набора данных — Melt the shifted dataset
Теперь, когда мы вычислили возвраты с использованием развернутого набора данных (Pivot dataset), мы собираемся «разворачивать (unpivot)» возвраты. Развернув (Unpivot) или расплавив данные, мы можем позже создать аналитическую базовую таблицу (АБТ — analytical base table, ABT), где каждая строка содержит всю необходимую информацию для конкретной монеты на определенную дату.
Мы не могли напрямую сместить исходный набор данных, потому что данные для разных монет были сложены друг на друга, поэтому границы могли бы перекрываться. Другими словами, данные BTC попадут в расчеты ETH, данные ETH попадут в расчеты LTC и так далее.
Чтобы расплавить данные, нам требуется:
- reset_index(), чтобы мы могли вызывать столбцы по имени;
- Вызовите метод melt();
- Передайте столбец (столбцы), чтобы сохранить в аргумент id_vars=;
- Назовите растопленный столбец (melted column), используя аргумент value_name=.
Вот как это выглядит для одного dataframe:
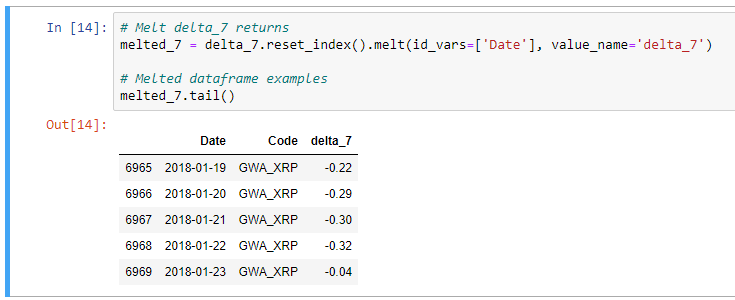
# Melt delta_7 returns melted_7 = delta_7.reset_index().melt(id_vars=['Date'], value_name='delta_7') # Melted dataframe examples melted_7.tail()
Результат:
Чтобы сделать это для всех возвращаемых DataFrame, мы можем просто перебрать delta_dict, вот так:
# Melt all the delta dataframes and store in list
melted_dfs = []
for key, delta_df in delta_dict.items():
melted_dfs.append( delta_df.reset_index().melt(id_vars=['Date'], value_name=key) )
melted_dfs
Результат:
[ Date Code delta_7 0 2014-04-01 GWA_BTC nan 1 2014-04-02 GWA_BTC nan 2 2014-04-03 GWA_BTC nan 3 2014-04-04 GWA_BTC nan 4 2014-04-05 GWA_BTC nan ... ... ... ... 6965 2018-01-19 GWA_XRP -0.22 6966 2018-01-20 GWA_XRP -0.29 6967 2018-01-21 GWA_XRP -0.30 6968 2018-01-22 GWA_XRP -0.32 6969 2018-01-23 GWA_XRP -0.04 [6970 rows x 3 columns], Date Code delta_14 0 2014-04-01 GWA_BTC nan 1 2014-04-02 GWA_BTC nan 2 2014-04-03 GWA_BTC nan 3 2014-04-04 GWA_BTC nan 4 2014-04-05 GWA_BTC nan ... ... ... ... 6965 2018-01-19 GWA_XRP -0.41 6966 2018-01-20 GWA_XRP -0.42 6967 2018-01-21 GWA_XRP -0.51 6968 2018-01-22 GWA_XRP -0.52 6969 2018-01-23 GWA_XRP -0.48 [6970 rows x 3 columns], Date Code delta_21 0 2014-04-01 GWA_BTC nan 1 2014-04-02 GWA_BTC nan 2 2014-04-03 GWA_BTC nan 3 2014-04-04 GWA_BTC nan 4 2014-04-05 GWA_BTC nan ... ... ... ... 6965 2018-01-19 GWA_XRP 0.02 6966 2018-01-20 GWA_XRP -0.26 6967 2018-01-21 GWA_XRP -0.28 6968 2018-01-22 GWA_XRP -0.35 6969 2018-01-23 GWA_XRP -0.39 [6970 rows x 3 columns], Date Code delta_28 0 2014-04-01 GWA_BTC nan 1 2014-04-02 GWA_BTC nan 2 2014-04-03 GWA_BTC nan 3 2014-04-04 GWA_BTC nan 4 2014-04-05 GWA_BTC nan ... ... ... ... 6965 2018-01-19 GWA_XRP 0.65 6966 2018-01-20 GWA_XRP 0.53 6967 2018-01-21 GWA_XRP 0.45 6968 2018-01-22 GWA_XRP 0.30 6969 2018-01-23 GWA_XRP 0.29 [6970 rows x 3 columns]]
Наконец, мы можем создать другой расплавленный фрейм данных, который содержит прогнозные 7-дневные возвраты. Это будет нашей «целевой переменной» для оценки нашей торговой стратегии.
Просто сдвиньте сводный набор данных на — 7, чтобы получить «будущие» цены, например:
# Calculate 7-day returns after the date return_df = pivoted_df.shift(-7) / pivoted_df - 1.0 # Melt the return dataset and append to list melted_dfs.append( return_df.reset_index().melt(id_vars=['Date'], value_name='return_7') )
Теперь у нас есть 5 расплавленных фреймов данных, сохраненных в списке melted_dfs, по одному для каждого из ретроспективных 7, 14, 21 и 28-дневных возвратов и один для прогнозных 7-дневных возвратов.
Шаг 8: Уменьшить-объединить расплавленные данные — Reduce-merge the melted data
Все, что осталось сделать — это объединить наши расплавленные DataFrames в единую аналитическую базовую таблицу. Нам понадобятся два инструмента.
Первый инструмент — это функция слияния Pandas, которая работает как JOIN в SQL. Например, для того, чтобы объединить первые два расплавленных DataFrames:
# Merge two dataframes pd.merge(melted_dfs[0], melted_dfs[1], on=['Date', 'Code']).tail()
Результат:
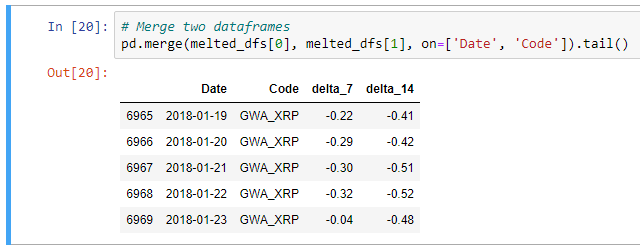
Посмотрите, теперь у нас delta_7 и delta_14 в одной строке! Это начало нашей аналитической базовой таблицы. Все, что нам нужно сделать сейчас — это объединить все наши расплавленные DataFrames с базовым DataFrame других функций, которые нам могут понадобиться.
Самый элегантный способ сделать это — использовать встроенную функцию уменьшения Python. Сначала нам нужно её импортировать:
from functools import reduce
Далее, прежде чем использовать эту функцию, давайте создадим список feature_dfs, который содержит базовые элементы из исходного набора данных плюс расплавленные наборы данных.
# Grab features from original dataset base_df = df[['Date', 'Code', 'Volume', 'VWAP']] # Create a list with all the feature dataframes feature_dfs = [base_df] + melted_dfs
Теперь мы готовы использовать функцию Reduce.
Reduce применяет функцию двух аргументов кумулятивно к объектам в последовательности (например, список).
Например,
reduce(lambda x,y: x+y, [1,2,3,4,5])
вычисляет
((((1+2)+3)+4)+5)
Таким образом, мы можем уменьшить-объединить все функции следующим образом:
# Reduce-merge features into analytical base table abt = reduce(lambda left,right: pd.merge(left,right,on=['Date', 'Code']), feature_dfs) # Display examples from the ABT abt.tail(10)
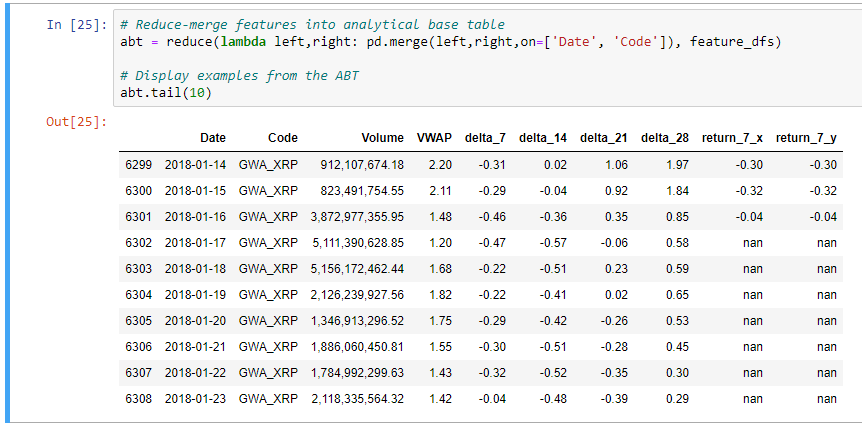
Словарь данных для нашей аналитической базовой таблицы (ABT):
- Date (Дата): день, в который были рассчитаны значения индекса.
- Code (Код): пара, какая криптовалюта.
- VWAP: средневзвешенная цена за день торгов на дату .
- delta_7: возврат за предыдущие 7 дней (1.0 = 100% возврат).
- delta_14: возврат за предыдущие 14 дней (1.0 = 100% возврат).
- delta_21: возврат за предыдущие 21 день (1.0 = 100% возврат).
- delta_28: возврат за предыдущие 28 дней (1.0 = 100% возврат).
- return_7: будущий возврат в течение следующих 7 дней (1.0 = 100% возврат).
Кстати, обратите внимание, что последние 7 наблюдений не имеют значений для функции return_7? Это ожидаемо, так как мы не можем рассчитать «будущие 7-дневные доходы» за последние 7 дней набора данных.
Технически, с этой ABT, мы уже можем ответить на нашу первоначальную цель. Например, если мы хотим выбрать монету, которая имела наибольший импульс 1 сентября 2017 года, мы могли бы просто отобразить строки для этой даты и посмотреть на 7, 14, 21 и 28-дневный возврат:
# Data from Sept 1st, 2017 abt[abt.Date == '2017-09-01']

И если вы хотите программно выбрать криптовалюту (пару для торгов) с наибольшим импульсом (например, за предыдущие 28 дней), вы должны написать:
max_momentum_id = abt[abt.Date == '2017-09-01'].delta_28.idxmax() abt.loc[max_momentum_id, ['Code','return_7']]

Тем не менее, поскольку мы заинтересованы в торговле только в первый день каждого месяца, мы можем упростить ситуацию для себя…
Шаг 9: (Необязательно) Агрегация через Group By — Aggregate with group-by
В качестве последнего шага, если мы хотим сохранить только первые дни каждого месяца. Для этого мы можем использовать группирование с последующей агрегацией.
Сначала создайте новую функцию ‘month’ из первых 7 символов строк Date.
Затем сгруппируйте наблюдения по «Коду» и «месяцу». Pandas создадут «ячейки» данных, которые разделяют наблюдения по коду и месяцу.
Наконец, в каждой группе просто возьмите .first() и сбросьте индекс.
Примечание. Мы предполагаем, что ваш фрейм данных по-прежнему правильно отсортирован по дате.
Вот как все это выглядит вместе:
# Create 'month' feature abt['month'] = abt.Date.apply(lambda x: x[:7]) # Group by 'Code' and 'month' and keep first date gb_df = abt.groupby(['Code', 'month']).first().reset_index() # Display examples gb_df.tail()
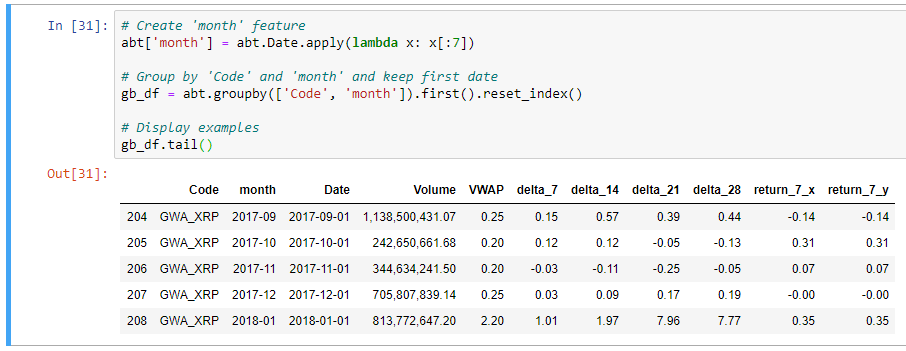
Как видите, теперь у нас есть правильная Аналитическая базовая таблица АБТ с:
- Только соответствующие данные с 1-го числа каждого месяца.
- Импульсные характеристики рассчитаны за предыдущие 7, 14, 21 и 28 дней.
- Прогноз будущих возвратов (future returns) через 7 дней.
Другими словами, у нас есть именно то, что нам нужно, чтобы оценить простую торговую стратегию, которую мы предложили в начале статьи!
Полный код от начала до конца
Вот весь основной код в одном месте, в одном скрипте.
# 2. Import libraries and dataset
import pandas as pd
pd.options.display.float_format = '{:,.2f}'.format
pd.options.display.max_rows = 200
pd.options.display.max_columns = 100
df = pd.read_csv('BNC2_sample.csv',
names=['Code', 'Date', 'Open', 'High', 'Low',
'Close', 'Volume', 'VWAP', 'TWAP'])
# 4. Filter unwanted observations
gwa_codes = [code for code in df.Code.unique() if 'GWA_' in code]
df = df[df.Code.isin(gwa_codes)]
# 5. Pivot the dataset
pivoted_df = df.pivot(index='Date', columns='Code', values='VWAP')
# 6. Shift the pivoted dataset
delta_dict = {}
for offset in [7, 14, 21, 28]:
delta_dict['delta_{}'.format(offset)] = pivoted_df / pivoted_df.shift(offset) - 1
# 7. Melt the shifted dataset
melted_dfs = []
for key, delta_df in delta_dict.items():
melted_dfs.append( delta_df.reset_index().melt(id_vars=['Date'], value_name=key) )
return_df = pivoted_df.shift(-7) / pivoted_df - 1.0
melted_dfs.append( return_df.reset_index().melt(id_vars=['Date'], value_name='return_7') )
# 8. Reduce-merge the melted data
from functools import reduce
base_df = df[['Date', 'Code', 'Volume', 'VWAP']]
feature_dfs = [base_df] + melted_dfs
abt = reduce(lambda left,right: pd.merge(left,right,on=['Date', 'Code']), feature_dfs)
# 9. Aggregate with group-by.
abt['month'] = abt.Date.apply(lambda x: x[:7])
gb_df = abt.groupby(['Code', 'month']).first().reset_index()
