
Содержание страницы
ETL Best Practices
Процессы извлечения, преобразования и загрузки данных (ETL) являются центральными в стратегии управления данными любой организации. Каждый шаг в процессе ETL — получение данных из различных источников, изменение их формы/структуры, применение бизнес-правил, загрузка в хранилище и проверка результатов — является важным этапом в процессе передачи данных.
Ниже перечислены некоторые основы, которые являются ключевыми для большинства имплементаций ETL.
Описание ключевых процессов ETL согласно лучшим практикам
What is ETL (Что такое ETL)
ETL (Extraction, Transformation, Loading) является сокращением от процессов извлечения, преобразования и загрузки данных, которые используются при наполнении данными хранилища.
При работе с операциями ETL вы обычно слышите термин конвейер данных/data pipeline (или просто «конвейер/pipeline»). Легко визуализировать такой процесс, как конвейер, в который поступают необработанные данные и выходит полезная информация.
Некоторые данные могут быть переданы в специальное место для очистки, а некоторые данные могут быть помечены как плохие и отправлены в область хранения плохих данных.
Конвейер данных может быть простым и прямым или может иметь множество изгибов и разветвлений. В большинстве случаев этот виртуальный конвейер данных существует в RAM на компьютере/сервере, на котором выполняются операции ETL, также данные могут быть временно сохранены в промежуточные или временные таблицы по мере необходимости.
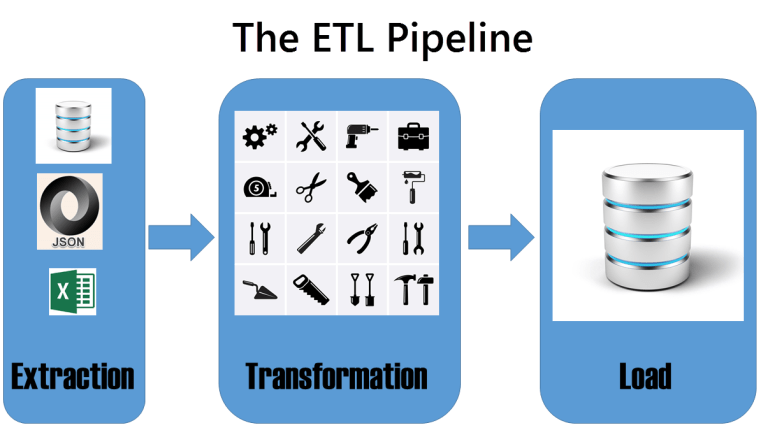
Как следует из названия, в ETL-операциях существует три разных этапа.
Extraction (Экстракция или выгрузка данных)
На этом этапе данные извлекаются из источника и попадают в конвейер. Источником может быть реляционная база данных, плоский файл (csv, excel, txt, и т.д.), API, устройство IOT, веб-сайт — почти все, что может создавать и/или хранить данные, может использоваться в качестве источника в процессе ETL. Этот этап не ограничен одним источником данных. Обычно для операций выгрузки данных характерно использование нескольких источников.
Хотя извлечение данных обычно является самой простой частью процесса ETL, иногда процесс выгрузки данных может приобретать сложную форму. Например, при выгрузке очень больших наборов данных, экстракция данных может выполняться длительное время, поэтому может потребоваться реализация дополнительной логики для создания инкрементальной выгрузки данных.
Также при выгрузке данных из API сервисов, таких как Youtube API, Facebook API при большом объеме данных может портебоваться специальная логика, т.к. многие сервисы отдают данные в рамках доступного лимита (например, лимит по количеству запросов или скорости обращения к API).
Transformation (Преобразование)
На этапе преобразования/трансформации данных могут выполняться следующие манипуляции над данными:
- Data reshaping: Изменение формы данных
- Изменение гранулярности данных (data granularity), когда одна входная строка становится несколькими выходными или наоборот
- Изменения типа данных (например, преобразование текста в целое число)
- Устранение дубликатов
- Использование таблицы поиска или маппинга (lookup tables/mappings) для проверки значений или для подстановки значения по ключу
- Удаление пробелов в начале или в конце строки, а также удаление других непечатных символов (их кстати можно обнаружить в MS Word или Notepad++, если вставить в документ и включить режим отображения символов)
- Привести текст к единому виду: например, стандартизировать регистр и заглавные буквы
- Выявление и перенаправление неверных или подозрительных строк данных
- Применение бизнес-логики
- Парсинг отдельных значений из строк, например, с помощью RegEx и создание на основе полученных значений дополнительного атрибута данных/транзакций
Не каждый процесс ETL требует всех перечисленных манипуляций. Большинство процессов будет использовать только их часть, либо отдельные методы для решения конкретной задачи. Степень преобразования данных зависит от качества и формы исходных данных, а также от того, насколько хорошо они соответствуют потребностям бизнеса и от поставленных задач самим бизнесом.
Некоторые наборы данных потребуют минимального преобразования, в то время как другие наборы данных потребуют значительной переработки. Для финансовых данных очень часто требуется реализация специальной логики аллокаций расходов, что порой приводит к большому числу обрабатывающих скриптов для небольшого объема данных по сравнению с остальными доменами.
Преобразование данных является наиболее сложной частью процесса ETL. Фактически, для большинства инициатив по перемещению данных, разработка процесса преобразования данных (включая сбор требований, разработку и тестирование) является наиболее трудоемкой частью всего проекта.
Совет по ETL для project managers: не стоит недооценивать время или усилия, необходимые для создания процесса преобразования данных. Проекты могут значительно задерживаться по срокам, потому что архитекторы или разработчики недооценили время, необходимое для разработки и тестирования этапа преобразования данных.
Load (Загрузка)
Фаза загрузки является последним этапом процесса ETL. На этом этапе данные передаются в структуры (data storage), в которых они будут храниться постоянно.
К тому времени, когда данные достигают фазы загрузки, все обновления завершены и данные уже подготовлены.
Собираем все этапы вместе
Три фазы каждой операции извлечения, преобразования и загрузки обычно тесно связаны друг с другом. Конвейер данных обычно работает в оперативной памяти сервера. ETL обычно разбивается на отдельные цепочки выгрузки, трансформации данных.
Иногда и загрузка данных в хранилище включается в эту цепочку.
Logging (Ведение журнала)
Logging (Ведение журнала). Правильная стратегия ведения журнала является ключом к успеху любой архитектуры ETL.
Если бы вы опрашивали специалистов по данным, над какими задачами им больше всего нравится работать, журналирование ETL, вероятно, не попало бы в список. Тем не менее, для успеха любой архитектуры ETL важно установить соответствующую стратегию ведения журнала. Отличной метафорой хорошей инфраструктуры логирования процесса ETL является водопровод дома: он не виден внешне, не является очень интересным, но вы наверняка со временем узнаете, правильно ли он спроектирован и смонтирован (или не установлен вовсе) при возникновении первых проблем с ним.
Что такое Logging?
Что же такое протоколирование ETL (или Logging). Протоколирование ETL — это журнал активности соответствующих событий, которые происходят до, во время и после выполнения процесса extract-transform-load.
Ведение журнала обычно осуществляется в самом программном обеспечении ETL, но может также включать другие журналы (например, в средствах планирования заданий) для получения дополнительных сведений по процессам ETL. Эти журналы будут различаться по степени детализации и объему записей, некоторые из них описывают метрики уровня нагрузки (сколько времени занимал весь процесс, сколько ресурсов потребовалось для работы), а другие относятся к одному небольшому сегменту нагрузки (сколько строк было загружено на шаге N).
Не существует универсального подхода к ведению журнала. В идеале каждый процесс должен оцениваться для определения стратегии ведения журнала на основе критичности данных, частоты выполнения, вероятности отказа и других факторов, которые важны в вашей среде.
Что следует логировать (писать в журнал)?
Как отмечалось выше, для ведения журнала требуется нечто большее, чем просто подход к работе с файлами cookie, поскольку каждый процесс может иметь немного разные потребности при ведении журнала. Однако в реальном мире большинство организаций применяют подход «все или ничего» ко всем процессам ETL:
- либо они вообще не регистрируются,
- либо все возможные метрики регистрируются и сохраняются навсегда.
Хотя для каждого из них есть некоторые крайние случаи, ответ почти всегда лежит где-то посередине (хотя, мы надеемся, ближе к способу «регистрировать все»).
Минималистичный подход может включать в себя просто запись времени начала и окончания всего процесса. Подобный урезанный подход работает лучше всего, когда объем возможных ошибок невелик, и когда процесс может быть перезапущен без больших временных и стоимостных издержек.
Это успешно используется для некоторых этапов загрузки, когда данные загружаются в изменяемые промежуточные таблицы. Большинство этапов загрузки включают в себя сначала удаление старых данных из целевых таблиц, что означает, что они могут запускаться повторно, не вызывая случайного дублирования данных. Следовательно, использование минималистического подхода к ведению журнала может быть использовано при таких типах нагрузок, поскольку точки отказа довольно минимальны, и процесс может быть легко перезапущен, если потребуется дальнейшая диагностика.
Однако большинство процессов требуют более интенсивного ведения журнала. Чтобы по-настоящему фиксировать то, что происходит внутри каждого процесса загрузки, а не просто измерять процесс в целом, для каждой задачи должен существовать пошаговый журнал. Если конкретное задание ETL имеет, например, десять шагов, в идеальном проекте будет регистрироваться запуск и остановка каждой задачи, любые исключения на уровне задачи, а также любая необходимая информация для аудита.
Следующие атрибуты logging могут использоваться в качестве приблизительного руководства по типам событий и метрик, которые нужно регистрировать во время логирования:
- Запуск и остановка событий. Начальная и конечная временные метки для процесса ETL в целом, а также их отдельные шаги должны быть сохранены.
- Статус. Шаги процесса могут быть успешными или неудачными по отдельности, и поэтому их состояние (not started, running, succeeded, или failed) должно регистрироваться индивидуально.
- Ошибки и другие исключения. Сбои и аномалии ведения журнала часто являются наиболее трудоемкой частью построения инфраструктуры ведения журнала. Это также та часть, которая приносит наибольшую пользу при тестировании и устранении неисправностей.
- Аудиторская информация. Это может варьироваться от простого захвата количества строк, загруженных при каждом выполнении процесса, до полного анализа количества строк и значений в единицах измерения на пути от источника к месту назначения.
- Тестирование и отладка информации. Это особенно полезно на этапе разработки и тестирования, в частности, для процессов, которые сильно влияют на преобразование ETL.
При планировании стратегии ведения журнала обычно просто регистрируют все события. Некоторые инструменты ETL, в том числе службы интеграции SQL Server , позволяют относительно легко перейти в режим захвата всех событий.
Регистрировать слишком много информации лучше, чем недостаточно, при прочих равных условиях. Однако с ведением журнала всегда связаны затраты: накладные расходы на обработку, пропускная способность сети и требования к хранилищу должны учитываться при определении того, как будут регистрироваться процессы ETL. Регистрация каждого доступного показателя и события может быть проще, но это не бесплатно.
Помните: соблюдайте баланс между тем, что вы хотели бы получить при ведении журнала, и затратами (жесткими и мягкими) на стратегию ведения журнала.
Как следует использовать Logs?
Давайте на минутку предположим, что ваша инфраструктура логирования построена и работает так, как ожидалось. Как вы передаете эту информацию нужным людям?
Очень часто бывает так: процессы ETL полностью регистрируются, но никто не знает, что именно регистрируется и где хранится информация. Если процессы регистрируются в черной дыре, информация о регистрации — это просто данные; они должны быть доступны и понятны, прежде чем эти данные можно будет классифицировать как информацию.
Большинство фанатов данных на самом деле предпочитают иметь доступ к необработанным, нефильтрованным данным журнала, чтобы можно было писать собственные запросы для получения именно тех исходных данных для детального понимания процессов ETL. Другие люди, которые не так любят писать SQL, вероятно, добились бы большего успеха с более упорядоченной информацией по логированию. Все чаще другим, часто полутехническим или нетехническим людям, также необходим доступ к журналам ETL. Администраторам баз данных, сотрудникам службы поддержки, бизнес-аналитикам и аудиторам, возможно, потребуется увидеть, что находится в журналах, и каждая группа, вероятно, имеет совершенно разные ожидания того, как получить эти данные. Некоторые топ менеджеры также могут периодически просматривать данные журнала ETL.
При рассмотрении того, как будет использоваться информация о регистрации, учтите следующее:
- Кто будет основной аудиторией для этих журналов?
- Каким другим аудиториям может понадобиться доступ к этой информации?
- Будут ли данные проверяться в режиме ad-hoc, или их необходимо формализовать с помощью принудительной доставки через уведомления или с помощью различных dashboards?
- В каком формате информация будет доставлятся наиболее понятным способом?
- Существуют ли проблемы безопасности, требующие фильтрации данных на уровне пользователя?
Ответы на эти вопросы будут определять стратегию раскрытия данных журнала. Это может быть так же просто, как предоставить другим администраторам баз данных местоположение данных журнала, или более формализованным, например, создать отчет через службу отчетов SQL Server или создать отдельную панель мониторинга Power BI.
Независимо от того, какой подход используется, цель состоит в том, чтобы донести необходимую информацию до целевой аудитории максимально понятным способом.
Политика хранения (Retention Policy)
Часто клиенты спрашивают: «Как долго необходимо хранить журналы ETL?».
Оптимальный ответ таков: «Храните их столько, сколько нужно, но не дольше». Да, это стереотипный ответ консультанта, но на самом деле ответ полностью зависит от ожиданий того, как будут использоваться эти журналы.
Вот общий диалог, который случается при обсуждении краткосрочной и долгосрочной стратегии хранения для журналов ETL:
- Короткий срок хранения : «Короткий срок хранения гарантирует, что вы не будете заполнять свои диски кучей старых данных журнала, которые вы никогда не будете использовать. Ведение журналов всего за несколько месяцев или за год обеспечивает достаточную историю для устранения любых недавних логических проблем или проблем с производительностью в вашем ETL. Короткие сроки хранения могут работать хорошо для вас, если вы в основном заинтересованы в оперативной поддержке и не используете свои журналы для долгосрочного анализа производительности или аудита».
- Длительный срок хранения : «Да, в хранилище вам дороже хранить журналы в течение более длительного периода времени. Но кого это волнует? Хранение относительно недорого, и вы можете архивировать старые логи на более медленные и более дешевые диски. Сохраняя свои журналы в течение более длительного периода, вы можете анализировать рабочие нагрузки и производительность ETL с течением времени, чтобы увидеть, как вы оцениваете тенденции по сравнению с прошлым годом. А если вы находитесь в среде с жестким аудитом, длительное хранение журналов может удовлетворить большую часть (или даже все) ваши требования аудита ETL».
Как и с большинством других концепций, не существует единого подхода для удовлетворения каждой ситуации. Однако в большинстве случаев следует ориентироваться на более длительный срок хранения журналов ETL, если только нет явной причины избегать этого. Лучше иметь данные, которые вы никогда не будете использовать, чем если вам потребуются данные, которых у вас нет.
Также можно агрегировать информацию из логов и наиболее старые данные хранить в виде сводной информации по дням или месяцам.
При создании стратегии хранения журналов ETL необходимо задать следующие ключевые вопросы:
- Будем ли мы использовать данные журнала ETL для тактического устранения неполадок или анализа тенденций и аудита?
- Сколько данных журнала мы генерируем каждый день / месяц / год?
- Сколько стоит хранение данных журнала?
- Насколько сложно и дорого будет архивировать старые логи в более дешевое и медленное хранилище?
- Каковы нормативные и/или аудиторские требования для журналов ETL?
Вывод
Построение правильной архитектуры ведения журнала ETL является одним из самых основных компонентов стратегии управления данными предприятия. Слишком часто ведение журнала является запоздалой мыслью, связанной с тем, что все остальное завершено или почти завершено. Точно так же, как сантехника в вашем доме спроектирована параллельно с остальной частью дома, ваша стратегия logging должна быть центральной частью вашей архитектуры ETL.
Дизайн ведения журнала ETL будет отличаться в разных организациях и даже может отличаться в разных проектах одной и той же компании. Рассмотрение всех переменных — какой уровень ведения журнала требуется, кто будет его использовать и как долго его следует хранить — поможет сформировать дизайн вашей архитектуры ведения журнала ETL.
ETL Auditing (Аудит)
Auditing (Аудит). Загрузка данных без ошибок не обязательно является успешной загрузкой. Хорошо продуманный процесс не только проверяет ошибки, но также поддерживает аудит количества строк, финансовых сумм и других показателей.
Это случается слишком часто: после того, как процесс ETL был протестирован и успешно выполнен, нет никаких дальнейших проверок, чтобы убедиться, что операция действительно сделала то, что должна была сделать. Иногда на это уходит день, иногда — год, но в конце концов от клиента, коллеги или начальника поступает звонок: «Что не так с этими данными?» В этот момент потребность в аудите ETL, который, к сожалению, часто рассматривается как необязательная функция, становится совершенно очевидной.
В этом совете по лучшей практике ETL я собираюсь обсудить аудит ETL и его важность в хорошо разработанной стратегии загрузки данных.
ETL Аудит
Начнем с определения аудита ETL. Аудит в процессе извлечения, преобразования и загрузки предназначен для достижения следующих целей:
- Проверка наличия аномалий в данных, помимо простой проверки серьезных ошибок.
- Захват и хранение электронного следа любых существенных изменений, внесенных в данные во время преобразования.
Если процесс ETL — это автомобиль, то аудит — это страховой полис. Аудит ETL помогает подтвердить отсутствие аномалий в данных даже при отсутствии ошибок. Хорошо продуманный механизм аудита также повышает целостность процесса ETL, устраняя двусмысленность в логике преобразования путем перехвата и отслеживания каждого изменения, вносимого в данные по пути. Есть некоторые общие черты поведения аудита и линии передачи данных.
Проверка аномалий данных
Допустим, вы загружаете данные из OLTP в хранилище данных с помощью своего любимого инструмента ETL. Эта конкретная загрузка извлекает 1,5 миллиона строк из источника OLTP. По пути он проходит несколько шагов преобразования и успешно завершает все свои задачи, загружая данные в пункт назначения. Однако быстрая проверка места назначения показывает, что было загружено только 1 499 990 строк. Что случилось с теми недостающими 10 строками данных?
Вот небольшой грязный секрет, который существует в программном обеспечении ETL: относительно легко просто потерять данные. Даже в таком инструменте ETL как SSIS, не так уж сложно настроить пакет, который позволяет данным попадать в битовое ведро (bit bucket) без каких-либо предупреждений или ошибок. А обновить данные — возможно, неправильно — даже проще, чем просто потерять данные. Это не дисфункция программного обеспечения, а функция его гибкости. Инструмент ETL не сможет долго продержаться на рынке, если он не позволит разработчикам сгибать, изменять форму и преобразовывать данные неортодоксальными способами. Эта гибкость связана с ответственностью за правильное использование инструментов; при плохой настройке данные могут просто исчезнуть или неправильно преобразоваться. Даже самые опытные и благонамеренные ETL-инженеры время от времени обнаруживали, что их данные где-то пошли не в ту сторону.
Противоядием от этого является проверка данных на наличие несоответствий, даже если ошибок не обнаружено. Даже в самых элементарных архитектурах ETL можно проверить несколько высокоуровневых метрик, чтобы убедиться, что загружены именно те данные, которые ожидались. Как минимум, критически важные процессы ETL должны проверять следующее, чтобы убедиться, что входные данные соответствуют выходным:
- Общее количество строк
- Совокупные итоги (которые могут включать финансовые суммы или другие сводные данные)
Некоторые процессы потребуют более тщательного аудита. Те, кто, как и я, когда-либо тратили время на перемещение и преобразование данных главной бухгалтерской книги, подтвердят, что даже подсчета строк и финансовых сумм недостаточно; обеспечение того, чтобы конечный баланс соответствовал начальному балансу плюс все транзакции за этот период. В других случаях может потребоваться проверка, чтобы убедиться, что данные находятся в разумных пределах.
Последнее замечание по проверке аномалий данных: не забывайте проверять случаи, когда данные не загружены. Это случается чаще, чем вы думаете. Исходный файл данных, не содержащий данных, неправильно сконфигурированный запрос, не возвращающий строк, или пустой исходный каталог, предназначенный для хранения одного или нескольких файлов, — все это может привести к успешному выполнению процесса ETL, но загрузке ровно нулевых строк данных. Бывают случаи, когда это уместно, в частности, при выполнении инкрементальной загрузки данных, которые могли измениться или не измениться. Однако, если данный процесс всегда должен приводить к загрузке ненулевого числа строк, обязательно добавьте шаг аудита, чтобы проверить это.
Журнал изменений скриптов трансформации данных
Разработчики ETL имеют значительные возможности для изменения данных. Часть «T» ETL подразумевает, что создаваемые нами процессы будут обновлять данные из их исходного состояния. Когда возникают проблемы с ETL-нагрузками, они очень часто коренятся в этих преобразованиях: сталкиваются бизнес-правила, процессы очистки, дедупликации и другие настройки, что приводит к неожиданному выводу данных.
Слишком часто процессы ETL превращаются в черные ящики, понятные только их создателю, с малой прозрачностью в отношении того, что происходит внутри.
Когда данные изменяются процессом ETL, должна быть запись об этом изменении. Это может быть столь же общим, как публикация для потребителей данных списка бизнес-правил и других преобразований, которые применяются к данным по мере их перемещения по цепочке ETL.
В некоторых случаях это включает в себя тщательную регистрацию каждого изменения, которое происходит в границах ETL, фиксируя картину данных до и после каждого изменения. Глубина этой регистрации зависит от многих факторов:
- Насколько критичен этот процесс?
- Сколько преобразований выполняется с данными?
- Насколько сложно неспециалисту понять, какие изменения происходят по замыслу в процессе ETL?
- В какой степени эти данные регулируются HIPAA , SOX или другими правилами?
Фиксация преобразующих изменений в процессе ETL делает процесс более прозрачным и заслуживающим доверия и может защитить разработчика ETL, когда возникают вопросы о том, что было изменено, когда и почему.
Построение системы аудита ETL
Способы добавления аудита в существующий процесс ETL сильно различаются в зависимости от используемой платформы и требуемого объема аудита. В большинстве программных пакетов ETL есть инструменты, которые могут помочь в процессе регистрации, а некоторые сторонние поставщики программного обеспечения предлагают компоненты и платформы аудита. Иногда в этом может помочь и само ядро базы данных: и SQL Server , и Oracle предлагают функции сбора измененных данных для отслеживания всех операций вставки, обновления и удаления в отслеживаемых таблицах.
Независимо от того, является ли ваша архитектура ETL простой, как набор пакетных файлов, выполняющих операторы SQL, или сложной, как сотни или тысячи вложенных пакетов SSIS, добавление логики аудита достижимо. Даже при наличии программного обеспечения, специально созданного для аудита ETL, считается, что подход, который работает лучше всего заключается в настройке логики аудита для каждого процесса. С аудитом сложно справиться с помощью шаблонного подхода (даже в большей степени, чем с логированием), и то, что вы получаете в удобстве, дорого обходится в гибкости.
Можно проводить аудит процессов ETL в индивидуальном порядке, не изобретая каждый раз велосипед. Я держу под рукой общий набор определений таблиц и поддерживающую логику, чтобы сократить путь к следующим целям аудита:
- Простой совокупный аудит количества строк, финансовых данных и других ключевых показателей.
- Шаблоны документации для сопоставления источника и цели и логики преобразования
- Облегченный аудит изменений на уровне пакетов
- Полный аудит каждого изменения, внесенного в процессе трансформации
В зависимости от формы и типа данных, потребностей бизнеса, а также политик и правил, касающихся изменения данных, используется один или несколько, а иногда и все четыре вышеперечисленных дизайна в процессах ETL. Там, где вы можете, найдите воспроизводимые шаблоны, которые можно использовать в нескольких процессах, но не поддавайтесь привычке копировать и вставлять логику. Почти каждый процесс потребует различного уровня аудита.
Вывод
Аудит процессов ETL часто считается роскошью, несущественной необходимостью, которую можно добавить, если позволяет время. Однако пропуск этого критического элемента хорошо спроектированной архитектуры ETL почти всегда приведет к трениям или путанице в отношении того, как и почему данные выглядят именно так. Аудит ETL редко является наиболее заметным элементом архитектуры, но это необходимый страховой полис для защиты целостности данных и процесса.
Data Lineage (Линия данных или Наследование данных ETL)
Data Lineage (Линия данных). Понимание того, откуда берутся данные, когда они были загружены и как они были преобразованы, крайне важно для целостности последующих данных и процесса их перемещения.
Прежде чем я начал свою техническую карьеру более полутора десятилетий назад, я несколько лет работал в правоохранительных органах. В этой области одной из вещей, которую нужно быстро усвоить, является концепция цепочки хранения доказательств. Мы должны были следовать многочисленным процедурам, чтобы убедиться, что улики не просто собраны и сохранены, но полностью задокументированы в отношении того, когда и где они были собраны, кто, когда и по какой причине завладел ими. Эти процессы, хотя и жесткие и трудоемкие, помогли создать необходимый след документации для защиты как доказательств, так и тех, кто ими владеет. Хотя нечасто ставилась под сомнение целостность доказательств, наличие хорошо задокументированной цепи хранения устранило бы двусмысленность в отношении того, откуда взялись доказательства и кто мог иметь к ним доступ.
Я нахожу параллель между цепочкой хранения доказательств и необходимостью фиксировать происхождение данных во время процессов перемещения и преобразования. Данные могут передаваться из одной системы в другую или даже между процессами в одной системе много раз в течение одного цикла загрузки. Данные могут поступать из нескольких систем одновременно, часто быстро и параллельно. В некоторых случаях сама загрузка ETL может генерировать новые данные. Несмотря на все это, мы все еще должны быть в состоянии ответить на два фундаментальных вопроса: откуда взялись эти данные и как они сюда попали ?
В мире данных шаблон проектирования линии передачи данных ETL — это наша цепочка поставок. В этом совете ETL Best Practices я расскажу о важности происхождения данных ETL и продемонстрирую некоторые советы по проектированию, как добавить это в ваши новые и существующие процессы.
ETL Data Lineage
Почему важна линия передачи данных?
- Он укрепляет доверие к данным, разъясняя происхождение данных
- Упрощает процесс устранения неполадок, позволяя отслеживать данные на уровне строк
- Снижает риск потери данных ETL, делая «дыры» в процессе более заметными
- Обеспечивает лучшую видимость бизнес-правил, которые в противном случае были бы скрыты в процессе загрузки ETL
Концепция происхождения данных относительно проста: построить процессы ETL таким образом, чтобы можно было проследить одну строку данных до источника, откуда они пришли и как они пришли сюда. Достаточно просто как шаблон дизайна, верно? Однако «простое» не означает «простое», и в результате я обнаружил, что большинство процессов ETL не определяют четкую линию данных. Правильное построение и тестирование элементов отслеживания происхождения данных требует времени и усилий. Требуются положения в самих данных — некоторые ключи или ключи, позволяющие отслеживать данные из исходного источника в конечный пункт назначения, — а также тщательная документация процессов, через которые они проходят, чтобы туда попасть. В большинстве случаев установление происхождения данных также включает в себя аудит изменений, которые происходят на различных этапах ETL.
Относительная и Абсолютная Линия Данных
Существует два варианта построения линии данных ETL: либо отследить каждую строку до ее исходного значения, используя первое доступное значение ключа (абсолютное происхождение), либо для процесса ETL с несколькими шагами настройте каждую таблицу так, чтобы каждый row будет иметь указатель на ключ из таблицы, которая непосредственно предшествовала этому процессу загрузки (относительное происхождение). Первый шаблон лучше подходит для более простых установок, когда есть только одна или две фазы (или шлюзы) ETL-преобразования, и прохождение данных от одного шлюза к другому является четким и однозначным. Однако модель абсолютного происхождения данных легко перерастает, что требует перехода к относительной модели происхождения данных.
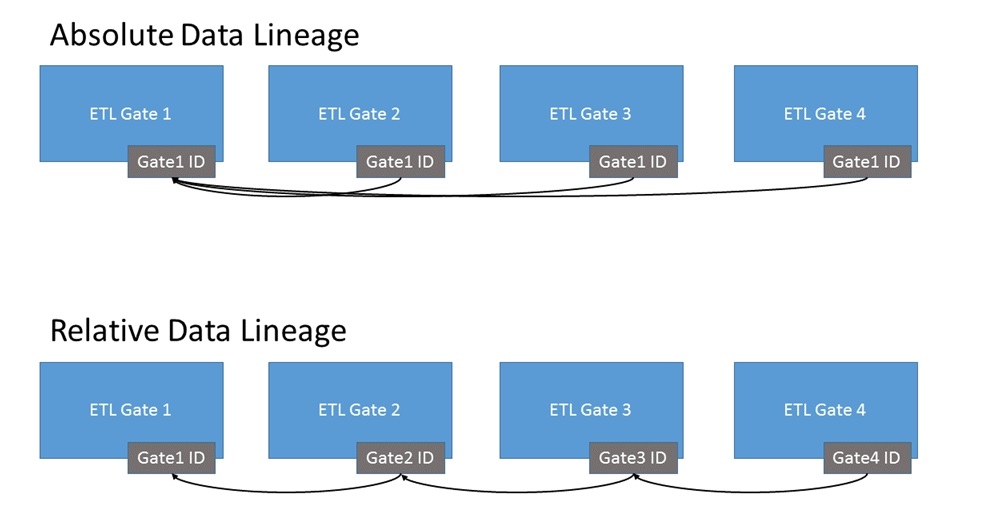
Как показано в приведенной выше модели, модель относительного происхождения данных является немного более сложной, требующей обхода нескольких шлюзов для определения происхождения конкретной строки. Тем не менее, относительная модель происхождения данных также гораздо легче масштабируется и упрощает процесс отслеживания нетипичных моделей нагрузки (например, таких, когда один из этапов в процессах ETL может генерировать новые данные без соответствующей строки из источника).
Как выглядит Data Lineage?
Давайте установим конкретный пример этого. Знакомый сценарий: клиент отправляет нам данные с помощью Excel. Ниже приведен фрагмент этого файла данных.

Быстрый взгляд показывает некоторые очевидные закономерности в этих данных:
- В этом файле представлены две разные категории данных: демография пациентов и детали транзакций.
- Существует уникальный ключ уровня строки. PatientID специфичен для пациента, но у нас есть дублированные значения для пациента «Уэйн, Брюс»
- Грязно. Имена появляются в двух разных форматах.
- Это неполно Количество отсутствует в одной строке, а в другой отсутствует Итоговая строка и Новый баланс.
- У него есть запись Джона Доу. Возможно, это потребует особой обработки?
Одна из основ происхождения данных — наличие одного или нескольких полей, обеспечивающих уникальность на уровне строк. В этом случае у нас нет таких полей из источника, поэтому нам нужно будет создать свои собственные в этом случае. Даже в тех случаях, когда поле (или комбинация полей), по-видимому, обеспечивает уникальность на уровне строк, я рекомендую вам не поддаваться искушению использовать естественный уникальный ключ (ключи) для целей происхождения данных. Хотя он может сохранить дополнительный столбец, пропуская суррогатный уникальный ключ, в ряде случаев использование естественных ключей может вызвать проблемы: заполнение одной и той же таблицы из нескольких источников потенциально перекрывающимися значениями; непреднамеренные повторяющиеся значения ключей, когда ни один из них не ожидается процессом ETL; и тип 2 медленно меняющиеся размерыгде дублирование бизнес-ключей ожидается в соответствии с замыслом. Для использования суррогатного уникального ключа требуется немного больше усилий и дополнительное пространство для хранения, но преимущества намного перевешивают затраты.
При создании идентификаторов строк на уровне таблицы лучше всего работает целое число (целое число 4 или 8 байтов). Чтобы поместить эти данные в таблицу базы данных, я бы создал дополнительный столбец в виде автоматически увеличивающегося целочисленного значения, которое в большинстве систем баз данных упоминается как значение идентификатора, чтобы обеспечить привязку на уровне строк для уникальности и отслеживания происхождения данных. Ниже я показываю промежуточную таблицу, используемую для получения данных из файла выше. Обратите внимание, что на данный момент я не вносил изменений в схему, за исключением добавления этого нового столбца идентификаторов (SourceRowID) и столбца ETLID для отслеживания идентификатора операции ETL, которая обработала загрузку (подробнее об этом позже).

Новый столбец SourceRowID теперь будет использоваться для целей происхождения данных.
В большинстве корпоративных систем ETL данные проходят через несколько шлюзов для изменения, очистки и стандартизации данных. В случае вышеупомянутой выборки данных первый элемент преобразования будет состоять в том, чтобы разделить две части данных — пациента и элемент оплаты — на отдельные выходные таблицы. Вывод позиции начисления проще, поскольку показанный образец данных соответствует ровно одному элементу начисления на строку данных. Простой захват этих элементов, специфичных для элементов начислений, вместе с вновь добавленными метаданными происхождения данных приводит к таблице вывода элементов начислений, аналогичной приведенному ниже примеру.
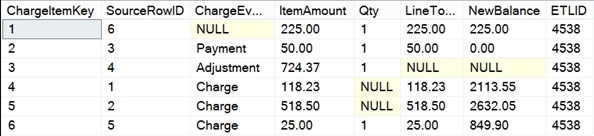
Как показано, перемещение данных элемента начисления в его собственную таблицу сохраняет строки, относящиеся к отдельным позициям начисления, а также значение SourceRowID, сгенерированное, когда данные попали в исходную промежуточную таблицу выше. В этой таблице я также добавил поле идентификации ChargeItemKey, которое однозначно идентифицирует каждый элемент начисления. Поле ChargeItemKey не является обязательным для этого дизайна, но я обычно использую столбец идентификаторов в каждой новой таблице в стробированном дизайне ETL — особенно, когда данные изменяются при прохождении через эти ворота. Использование этого шаблона создания нового суррогатного идентификатора для каждой таблицы также поддерживает гибкий шаблон относительного происхождения данных, упомянутый выше.
Работа с информацией о пациенте из исходного файла данных немного сложнее, чем элементы оплаты. Поскольку в данных есть известные дубликаты, перемещение данных в таблицу с детализацией на уровне пациента потребует некоторой дедупликации. Существует много методов для выполнения дедупликации, поэтому я сохраню специфику этой операции для другого дня. После дедупликации мы получаем таблицу подготовки пациентов, которая выглядит примерно так.
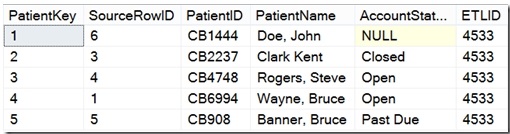
Как и прежде, специфичные для зерна поля передаются в новую таблицу пациентов. SourceRowID сохраняется как указатель на исходные данные, сохраняя происхождение данных. Поскольку эти ворота также управляли дедупликацией записей о пациентах, выходные данные представляют собой пять строк, а не шесть, показанные в оригинале. Обратите внимание, что процесс дедупликации в этом примере явно не отслеживает запись пациента для SourceRowID 2 (дубликат пациента «Уэйн, Брюс»), так как данные уровня пациента были свернуты в строку, помеченную SourceRowID 1. В некоторых При планировании линий данных ETL может возникнуть необходимость отслеживать строки, которые намеренно отбрасываются из-за дедупликации. Вот где может пригодиться хорошая стратегия аудита ETL , отслеживая те строки, которые приносятся в жертву дедупликации и другим бизнес-правилам.
Этот относительно тривиальный пример показывает краткое описание конструкции, в которой уникальный идентификатор строки создается и сохраняется на протяжении двух этапов ETL. Очевидно, что состояние этих данных, скорее всего, будет и дальше меняться: очистка данных будет выполняться по формату столбца с именем, столбцы с нулевыми числами, скорее всего, должны быть очищены, а запись Джона Доу имеет некоторые недостатки (нет AccountStatus или Значения ChargeEvent), которые могут потребовать либо создания значения, либо перенаправления всей строки для сортировки. Независимо от того, имеет ли этот процесс два шлюза или двадцать, один и тот же шаблон происхождения данных ETL будет по-прежнему оставаться верным: каждая строка должна быть прослеживаемой до своего происхождения либо напрямую (через абсолютное происхождение), либо косвенно (используя относительное происхождение).
Отслеживание процесса ETL
При реализации линии данных я почти всегда добавляю также идентификаторы линии процесса ETL. Эти идентификаторы процесса, представленные в приведенном выше примере в столбце ETLID, идентифицируют экземпляр выполнения процесса ETL, который загрузил данные. Как показано выше, эти идентификаторы отличаются от одной таблицы к другой, но дублируются в каждой таблице. Это по замыслу; все строки, вставленные или обновленные в данной таблице в одном и том же цикле ETL, будут совместно использовать значение идентификатора ETL, и в большинстве случаев эти идентификаторы ETL являются специфическими для каждой загрузки таблицы. Отслеживание происхождения линии на уровне, а также идентификаторов операций ETL помогает создать электронный след, показывающий путь, по которому каждая строка данных проходит через конвейер ETL.
заявка
Все ли процессы ETL требуют отслеживания происхождения данных? Нет. Меньшие, менее сложные процессы ETL могут не требовать того же уровня (если вообще) отслеживания происхождения, который был бы обнаружен при большой загрузке хранилища данных с несколькими шлюзами. Больше гейтов и / или преобразований, которые происходят во время ETL, увеличат потребность в полном отслеживании линии передачи данных. В случае сомнений, я рекомендую потратить дополнительное время на встраивание происхождения данных ETL в ваш конвейер данных. Лучше иметь это и не нуждаться в этом, чем наоборот.
Вывод
Отслеживание происхождения данных ETL — это необходимый, но, к сожалению, недостаточно используемый шаблон проектирования. Правильная идентификация линии передачи данных помогает создать более надежный и надежный процесс ETL, который легче контролировать, проще устранять неисправности и более понятен в своей работе.
ETL Modularity (ETL Модульность)
ETL Modularity (ETL Модульность). Создание многократно используемых структур кода важно в большинстве областей разработки, и особенно в процессах ETL. Модуляризация ETL помогает избежать многократного написания одного и того же сложного кода и уменьшает общие усилия, необходимые для поддержки архитектуры ETL.
Представьте на минуту, что вы создали программную вещь. На самом деле, мы будем называть это Вещи. Вы вложили много работы в The Thing, и она делает именно то, что вы хотели. Вы вводите The Thing в игру как часть более крупного решения, и после нескольких ревизий его поведение проверяется, и оно считается готовым к производству. Месяцы спустя, создавая другое программное решение, вы столкнетесь с проблемой, аналогичной той, которую вы решили с The Thing. Вы делаете копию оригинальной The Thing, настраиваете ее для этой цели и помещаете в новое решение. Повторите этот цикл несколько раз. Пять лет спустя вы смотрите вверх и понимаете, что у вас есть две дюжины адаптаций The Thing, несколько отличающихся друг от друга и разбросанных по всей ширине базы кода.
Так, дорогие читатели, так разрабатывается большинство решений ETL.
Этот дизайн, который часто приводит к десяткам — возможно, даже сотням — копий одной и той же логики, создан с благими намерениями. Мне нужно использовать Вещи здесь, я делаю копию последней Вещи и изменяю ее для этого случая использования. Это быстро решает проблему. Тем не менее, это техническое поведение, вызывающее долги, стоит гораздо дороже при длительном обслуживании, чем количество времени, сэкономленное за счет рефакторинга копии существующего фрагмента кода.
Это затруднение не уникально для ETL. Каждый проект по кодированию в каждой организации имеет некоторое количество целенаправленного дублирования кода. Проекты ETL, однако, кажутся особенно восприимчивыми к этой проблеме. Разработчики, архитекторы и менеджеры проектов опасаются незавидного определения лица, нарушившего фид хранилища данных, загрузку данных клиентов или отчет акционеров. Короткий путь заключается в дублировании и адаптации. Но так ли это?
В своей продолжающейся серии статей о лучших практиках ETL я поделюсь некоторыми соображениями о том, почему модульность ETL помогает сократить общее время разработки и затраты на владение.
ETL Модульность
Из всех шаблонов проектирования ETL, о которых я пишу, нет ни одного, который обеспечил бы большую отдачу от ваших временных затрат, чем модульность ваших процессов ETL. В двух словах, модульность ETL предполагает абстрагирование общих задач в повторно используемые единицы работы. В качестве более конкретного примера рассмотрим сценарий загрузки файла с FTP-сервера, что является обычной задачей в большинстве инфраструктур ETL. Поскольку большинство пакетов программного обеспечения ETL имеют встроенные задачи для обработки загрузок по FTP, общая схема проектирования заключается в том, чтобы включать эту задачу (с жестко заданными путями к исходному файлу и локальной папке назначения) в каждый процесс ETL, требующий загрузки по FTP. Как описано, процесс загрузки и импорта будет иметь следующий поток.

Этот шаблон прекрасно работает для одного процесса. Однако у вас никогда не будет только одного процесса ETL, который загружает файл с FTP. Эти вещи всегда путешествуют в стадах, так что вероятность того, что у вас есть тонна связанных задач, велика. Когда вы устанавливаете их по частям в течение месяцев или даже лет, ваши шаблоны начинают выглядеть примерно так.

Видишь что случилось? Мы начали с хорошего паттерна в процессе ETL A, но два других слегка различались в своих подходах, каждый из которых упускал что-то из исходного паттерна. На самом деле разработчик (и) ETL мог намеренно целенаправленно проектировать эти процессы с различным поведением. Однако в большинстве случаев это не так — разница между этими шаблонами проектирования вызвана ошибкой человека, а не намерением.
Модуляризация процессов ETL может помочь избежать подобных проблем. Модульная конструкция включает в себя разделение общих операций на отдельные и отдельные процессы, которые можно вызывать в общем. Эти модульные процессы параметризованы для обеспечения возможности передачи рабочих значений во время выполнения и централизованно хранятся, чтобы они были доступны и отображались для общего использования.
Среди преимуществ модульности процессов ETL:
- Стандартизированное поведение в основных функциях, а также в периферийных задачах, таких как ведение журнала и обработка ошибок
- Уменьшите дублирующую работу в будущем развитии ETL
- Более легкие процессы изменения
- Более простое модульное тестирование
- Упрощенный обмен задачами разработки между несколькими разработчиками
- Меньшая площадь поверхности для устранения неполадок, когда что-то идет не так
Создание архитектуры ETL с использованием модульных и многократно используемых компонентов требует времени и усилий для внедрения, и, как и любая другая часть программного обеспечения, со временем будет развиваться при надлежащем уходе и питании. Работа модуляризации обычно включает четыре этапа:
- Инвентаризация общих задач. Что может быть модульным? Насколько большими или маленькими должны быть эти единицы работы? Я не хочу упрощать работу, которая входит в этот этап, потому что решение, какие задачи можно использовать повторно, чтобы оправдать работу (и, что более важно, может быть сделано универсальным без чрезмерной сложности), требует больших усилий. Просмотр журналов прошлых выполнений, изучение возможных процессов, которые могут быть объединены, и создание прототипов — все это требуется для правильной работы.
- Построить модульный процесс. Этот этап может быть облегчен путем повторного использования некоторых зрелых компонентов существующих процессов (если они уже существуют).
- Выявление и вывод значений во время выполнения. Любое значение, которое может быть изменено (например, имя FTP-сервера или место загрузки в приведенном выше примере), должно быть задано как параметр времени выполнения, а не как жестко заданное значение.
- Стандартизация использования. Этот этап в основном включает документацию и обучение и предназначен для устранения быстрых и простых (и вызывающих технический долг) жестко закодированных шагов, смоделированных выше.
В приведенном выше кратком примере проектов есть две легко идентифицируемые возможности для модульности: загрузка файлов с FTP и перемещение файлов в архив. Поскольку эти типы операций очень распространены, и каждый из них включает в себя этапы ведения журнала для сбора некоторой информации об операции (всегда хорошая практика — см. Мой пост по разработке ведения журнала ETL в этой серии), оба они будут хорошими кандидатами для модульности. Инкапсулируя общее поведение и параметрируя значения, необходимые во время выполнения, следующий дизайн можно использовать повторно и намного проще в обслуживании.
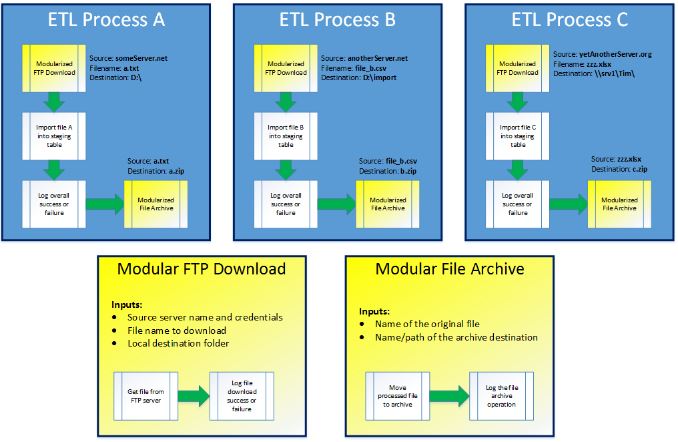
Как показано, высокоуровневые нагрузки (процессы ETL A, B и C) блаженно не знают, что входит в загрузку с FTP или операцию архивирования файлов. Единственное, что важно для этих трех процессов — это требуемые параметры и результат каждой операции. По мере добавления новых процессов разработчики могут просто вызывать модули для загрузки по FTP и / или файлового архива по мере необходимости, без необходимости каждый раз переписывать эти фрагменты логики. Хотя этот шаблон требует дополнительной предварительной работы, усилия, необходимые для обновления модульной логики или добавления новых процессов с использованием указанной логики, намного меньше, чем поддержание множества копий одних и тех же задач ETL.
Последнее замечание о модульности ETL: не все может быть сделано достаточно общим, чтобы соответствовать этому шаблону. Вы заметите, что в приведенном выше примере не была предпринята попытка обобщить импорт данных плоского файла в промежуточную таблицу. Это было сделано намеренно, чтобы продемонстрировать тот факт, что некоторые компоненты ETL все еще требуют частичной разработки. Операции с потоками данных — в частности, те, которые связывают вместе метаданные из источника в место назначения — особенно сложны для модульности. Я не говорю, что это не может быть сделано, но усилия, чтобы сделать это, часто больше, чем последующая выгода. Как отмечалось ранее, одна из самых сложных задач, которые вам предстоит пройти, — это выяснить, какие операции могут быть разумно модульными, а какие — нет.
Вывод
Построение модульных процессов ETL является сложной задачей и требует дисциплины, особенно при первом запуске по пути модульности. Тем не менее, правильно разработанная модульность ETL экономит время и усилия, упрощает тестирование и устранение неполадок, а также снижает текущие расходы на операции ETL.
ETL Atomicity (ETL Атомность)
ETL Atomicity (ETL Атомность). Насколько большим должен быть каждый процесс ETL?
Я до сих пор помню первый настоящий процесс ETL, который я разработал. В то время я работал в больнице, проходя серьезную реализацию системы, когда мы заменили 17-летнюю систему на основе UNIX более современным набором медицинских приложений с серверной частью SQL Server. Мне было поручено создать, протестировать и выполнить процессы ETL для этого преобразования. Несмотря на то, что я имел опыт работы с базами данных, я все еще был новичком в мире ETL и нашего предпочтительного инструмента, SSIS. Моей первой и единственной заботой было перемещение данных как единовременной операции, поэтому я поместил все в один огромный пакет служб SSIS. В этом пакете были десятки задач, которых было слишком много, чтобы их можно было разместить на одном экране, и только метаданные для этого пакета имели размер более 5 МБ.
В конце концов, монолитный процесс, который я построил, сделал то, что должен был сделать. Он был разработан для одноразового использования и больше не будет вызываться после окончательной загрузки данных в новую систему. Тем не менее, я извлек некоторые ценные уроки о возможности повторного использования и тестируемости в ходе разработки этого процесса, и в результате я полностью изменил способ, которым я строил процессы ETL с этого момента. Это тот шаблон проектирования, которым я поделюсь с вами в этой части моей серии ETL Best Practices .
ETL Atomicity
Атомность — чрезмерно причудливое слово, чтобы описать разбивание вещей на отдельные части. Шаблон проектирования атомарности ETL включает в себя определение отдельных единиц работы и создание небольших и индивидуально выполняемых процессов для каждого из них. В отличие от архитектуры моего первого в истории проекта ETL, в котором вся логика содержалась в одном процессе, атомарный проект разбивает отдельные части нагрузки на более мелкие куски логики, каждый из которых может быть вызван самостоятельно. В то время как функциональные результаты двух разных шаблонов проектирования должны быть одинаковыми, атомный дизайн, состоящий из более мелких частей, а не из нескольких более крупных, делает процесс более зрелым.
Проект атомарности ETL требует анализа частей процесса, которые тесно связаны друг с другом, вместо того, чтобы сосредоточиться на высоком уровне на том, что должно быть сделано всем проектом в целом. Я немного говорил об этом в своем посте о модульности ETL , в котором я обсуждал абстрагирование часто используемых функций, позволяющих легко использовать их повторно. Проектирование ETL-процессов атомарно делает этот шаг еще дальше, отделяя не только части, которые могут быть повторно использованы в других нагрузках, но и выделяя любую часть нагрузки, которую, возможно, потребуется изменить, протестировать или выполнить самостоятельно.
Почему ETL Atomicity?
Существует множество преимуществ для создания небольших узкопрофильных подпроцессов, а не для монолитных пакетов «все».
Опыт тестирования и отладки . Если вы когда-либо пытались выполнить модульное тестирование или отладку процесса с помощью множества движущихся частей, вы знаете, какое это может быть время. Если что-то ломается или не ведет себя должным образом, обход кода для поиска проблемной логики является излишне сложным и отнимает много времени. Разбивая нагрузку на функциональные блоки, тестирование и отладку можно выполнять индивидуально для выявления ошибок до того, как будет проведено полное интеграционное тестирование.
Техническое обслуживание . Каждый процесс ETL нужно будет пересмотреть и настроить в какой-то момент. Разделяя функции на их собственные процессы, обновлять или заменять эти поведения становится легче, потому что теперь это модульная конструкция.
Разделение обязанностей по развитию . Если вы работаете в среде с несколькими разработчиками, и у вас есть несколько сотрудников, работающих над одной и той же нагрузкой, процесс разработки будет намного проще, если каждый разработчик будет работать над своим назначенным подпроцессом, а не пытаться согласовать изменения в одном монолитном коде. файл. Как сторонние разработчики служб SSIS: если вы никогда не пытались использовать файл пакета служб SSIS, не делайте этого; это бесполезное упражнение. Разделите свою логику на несколько пакетов, если вы разрабатываете как часть команды.
Пользовательский интерфейс . Большинство инструментов ETL имеют графический интерфейс, который может стать очень занятым, когда задействовано много движущихся частей. Кроме того, многие из них (включая мой инструмент выбора, SQL Server Integration Services) выполняют проверку во время разработки, пока вы редактируете пакеты, и наличие большого количества соединений и конечных точек может замедлить этот процесс проверки. Разделение функциональных блоков работы на отдельные подпроцессы обеспечивает более удобный и отзывчивый интерфейс.
Возможность повторного использования . Как уже отмечалось, сохранение процессов ETL небольшим и сфокусированным не обязательно должно быть связано с возможностью повторного использования, но это может быть дополнительным преимуществом атомарности ETL. С более мелкими и более конкретными функциональными блоками вы сможете повторно использовать некоторые компоненты в том же процессе или даже в других процессах.
При использовании атомарного дизайна ETL вы обычно получаете больше кода. Но действительно ли это имеет значение? Как профессионалы в области данных, наша основная цель должна заключаться не в том, чтобы уменьшить объем кода, который мы пишем, а в том, чтобы написать максимально эффективный код. Если атомарный ETL-дизайн означает, что у вас на 20% больше кода (что является очень либеральной оценкой), вы в разы вернете свои затраты времени и памяти за счет более простого тестирования, более простого обслуживания и лучшего повторного использования.
Насколько маленькими должны быть эти процессы?
При проектировании атомарности ETL должна быть только одна движущаяся часть на процесс, или две, или десять? Как это часто бывает, ответ — это зависит . Я не стремлюсь к определенному размеру или количеству движущихся частей; скорее, я сосредотачиваюсь на функциональной единице работы . Все задачи или шаги в рамках одного процесса должны быть непосредственно связаны с другими. Оценивая отдельные этапы процесса, чтобы определить, какие (или группы) должны стоять самостоятельно, я задаю следующие вопросы:
- Не упростит ли это процесс тестирования, если я сам протестирую эту задачу?
- Что касается этого процесса, нужно ли мне когда-либо выполнять эту задачу самостоятельно?
- Будет ли этот процесс иметь логику после этой задачи, которая будет по-разному реагировать на успех или провал этой задачи?
- Может ли логика в этой задаче быть изменена или заменена без принудительного изменения других частей процесса?
- Может ли логика в этой задаче быть повторно использована в других частях этого процесса или других процессов?
Чем больше ответов «Да» я получу выше, тем больше вероятность того, что задача или группа задач будут преобразованы в отдельный подпроцесс.
В качестве более конкретного примера представьте себе процесс, который будет загружать zip-файл с сайта SFTP, извлекать содержащиеся в нем файлы, обрезать набор промежуточных таблиц, загружать эти файлы в промежуточные таблицы и затем архивировать zip-файл. Учитывая вышеупомянутые краткие детали, я склоняюсь к следующему дизайну:
- Подпроцесс для выполнения загрузки SFTP. Я хотел бы сделать это как можно более универсальным, чтобы его могли использовать другие процессы, поскольку подключение к SFTP-серверам для обмена данными довольно часто встречается в рабочих нагрузках ETL.
- Подпроцесс для извлечения архивных файлов. Опять же, поскольку это довольно часто встречается в операциях ETL, я бы сделал этот процесс модульным .
- Подпроцесс для усечения промежуточных таблиц и загрузки этих таблиц с извлеченными файлами в качестве источника. Обратите внимание, что в этом подпроцессе есть две разные задачи. Это сделано намеренно, поскольку маловероятно, что мне нужно будет усекать промежуточные таблицы без последующей их перезагрузки, и я определенно не хочу загружать в изменчивые промежуточные таблицы без предварительного их усечения.
- Подпроцесс для перемещения zip-файла в расположение архива.
Как показано, это не всегда дизайн с одной задачей на подпроцесс. Группировка задач целесообразна, когда коллекция работает вместе для выполнения единой единицы работы, и когда выполнение или тестирование одного фрагмента из этой группы не добавляет ценности.
Связывая все вместе
Имейте в виду, что разделение процессов на группы тесно связанных задач не означает, что у вас все еще не может быть одного процесса, контролирующего выполнение. В атомарном процессе ETL обычно существует процесс оркестровки, который объединяет все движущиеся части для сквозной нагрузки, обеспечивая единую точку вызова для этой нагрузки. Разница между этим шаблоном и монолитом, который я описал в начале поста, состоит в том, что этот шаблон встраивает рабочую логику (где выполняется «настоящая работа») в эти подпроцессы, а процесс оркестровщика или контроллера обрабатывает поток из одного подпроцесса. другому.
Вывод
Модульность ETL облегчает задачу разработки и поддержки процессов извлечения, преобразования и загрузки. Разбивая функциональные блоки работы на индивидуально тестируемые, заменяемые и исполняемые подпроцессы, общий механизм загрузки становится более устойчивым.
Error Handling (Обработка ошибок)
Error Handling (Обработка ошибок). Что происходит, когда что-то идет не так? В этом разделе рассматриваются шаблоны проектирования для предотвращения и управления ошибками в процессах ETL.
При разработке правильной архитектуры ETL есть два ключевых вопроса, на которые необходимо ответить. Первый: «Что должен делать этот процесс?» Определение начальной и конечной точек данных, преобразований, фильтрации и других шагов должно быть выполнено, прежде чем можно будет продолжить любую другую работу. Второй вопрос, на который необходимо ответить: «Что должно произойти, если процесс завершится неудачей?» Слишком часто дизайн останавливается, не задав и не ответив на этот второй вопрос. Обработка ошибок ETL становится запоздалой мыслью, а не ключевой частью дизайна.
В этой части моей серии ETL Best Practices я расскажу о важности логики обработки ошибок в процессах ETL.
Fail-First Design
Правильная обработка ошибок ETL — это не то, что можно просто закрепить в конце проекта. Скорее, это должно быть частью архитектуры от первоначального дизайна. Создание логики ошибок после построения процессов ETL сродни добавлению сантехники в дом после того, как все стены уже подняты: это можно сделать, но это уродливо. Правильное управление ошибками требует, чтобы эти части разрабатывались и создавались вместе с ядром приложения ETL, а не после него. По этой причине я практикую то, что я называю отказоустойчивым дизайном . В этом проекте я уделяю одинаковое внимание тому, что происходит, когда нагрузка идет правильно или неправильно. Этот подход занимает больше времени, но он также обеспечивает более надежное и предсказуемое поведение.
Обработка ошибок ETL
Управление логикой ошибок в процессах ETL — это широкая тема, но ее можно разбить на следующие подходы.
- Предотвращение ошибок: исправить или обойти условие ошибки, чтобы остановить процесс сбоя.
- Реакция на ошибку: когда сбой неизбежен, критически важно правильно реагировать на ошибку.
Чтобы быть понятным, управление условиями отказа не означает, что вы должны выбрать один из двух вышеуказанных подходов. Эффективные архитектуры ETL обычно включают в себя как предотвращение, так и реагирование, формируя двусторонний подход к управлению ошибками. Я расскажу о каждом из этих подходов ниже.
Предотвращение ошибок
Существуют некоторые условия, которые вызывают сбои в процессах загрузки, которые можно предотвратить с помощью логики обработки ошибок ETL. Среди случаев, когда предотвращение ошибок полезно:
- Процесс загрузки состоит из нескольких этапов, но один сбой не должен прерывать остальную нагрузку
- В некоторых частях данных существует известный недостаток, который можно исправить как часть процесса ETL
- Некоторая часть процесса ETL является нестабильной, и вам необходимо повторить попытку в случае сбоя
Первый пункт в списке выше — это наиболее распространенный сценарий, в котором предотвращение ошибок полезно. Допустим, вы выполняете операции ETL, собирая данные о розничных продажах по всему миру и в каждом часовом поясе. Для загрузки в одном часовом поясе могут быть торговые точки, данные которых еще не доступны (магазин оставался открытым поздно, задержки в сети и т. Д.). Этот сценарий не обязательно представляет ошибку, просто задержка в обработке. В этом примере бизнес-загрузка имеет смысл при загрузке доступных данных, пропуская источники, которые еще не готовы. В таком случае, как правило, допускается сбой отдельных задач без прерывания процесса ETL, а затем сбой процесса в целом после выполнения всех задач. Процесс может попытаться выполнить все задачи загрузки, завершившись с ошибкой только в случае сбоя одного или нескольких отдельных шагов.
Хотя предотвращение ошибок является полезным инструментом в вашем наборе трюков ETL, позвольте мне призвать вас не подавлять условия ошибок просто для того, чтобы заставить ваши процессы ETL успешно работать. Хотя это, как правило, имеет хорошие намерения, оно может вызвать некоторые неожиданные проблемы, если не будет сделано должным образом. То, что ошибку можно предотвратить, не означает, что она должна быть! Предотвращение ошибок часто является решением бизнес-логики, а не техническим. Прежде всего, убедитесь, что любое предотвращение или подавление ошибок решает деловую проблему под рукой.
Ответ об ошибке
Не все ошибки ETL должны быть предотвращены. Фактически, большинство бизнес-случаев поддается ошибочному реагированию, а не предотвращению. Как бы странно это ни звучало, есть смысл в том, чтобы позволить процессам ETL не работать:
- Управление зависимостями: если шаг B зависит от успеха шага A, то шаг B не должен выполняться в случае сбоя A.
- Отчет об ошибках: часто уведомления запускаются из-за ошибок. Разрешение сбоя процессов обеспечивает выполнение этих уведомлений.
- Триггеры ошибок: задачи, которые не выполняются, могут инициировать логику ответа об ошибках для дополнительных уведомлений, операций очистки и т. Д.
Именно в дизайне ответа на ошибку я свободно использую фразу, изящно терпящую неудачу, При разработке процессов, которые построены так, что они терпят неудачу, вы должны учитывать, как что-то может пойти не так, и решить, что должно произойти, когда это произойдет. Для многих процессов изящный сбой — это просто сбой без других действий. Рассмотрим пример процесса, который загружает энергозависимую промежуточную таблицу. Обычно это включает усечение этой таблицы с последующей перезагрузкой этой таблицы. Если произойдет сбой этого процесса, очистить нечего — просто исправьте недостаток и повторите последовательность усечения / перезагрузки. Однако при загрузке данных транзакций в рабочую таблицу дело обстоит иначе. Если эта транзакционная нагрузка завершится неудачей на полпути, вы получите частично загруженную целевую таблицу. Вы не можете просто перезапустить процесс, чтобы избежать дублирования транзакций. В таком случае,
В некоторых случаях можно прогнозировать сбой и реагировать соответствующим образом. Некоторые инструменты ETL, включая мой любимый такой инструмент (SSIS), включают функциональность для проверки возможных сбоев перед выполнением. В службах SSIS вы можете запустить проверку пакета без фактического выполнения указанного пакета. Хотя этот процесс проверки не обнаруживает все возможные ошибки, он проверяет некоторые общие точки ошибок. Другие этапы проверки можно выполнить вручную, например, проверить, существует ли каталог или есть ли у учетной записи выполнения разрешение на загрузку.
При разработке логики реагирования на ошибки обязательно определите гранулярность. Хотя обычно мы говорим об управлении ошибками на уровне задач, можно управлять ошибками на уровне строк. Управление ошибками на уровне строк обычно классифицируется как операция качества данных, а не как управление ошибками. Однако, поскольку одна неверная строка данных может прервать успешную загрузку, она становится частью этого домена. При выборе стратегии управления ошибками на уровне строк дизайн становится более сложным: что мы делаем с плохими строками данных? Должен ли определенный процент неверных данных вызывать сбой всей нагрузки? При реализации такого дизайна должна быть деловая ценность в загрузке хороших данных, в то время как пропуск (или загрузка в сортировку) плохих данных.
Детали логики ответа на ошибку будут разными для каждого процесса. Опять же, это часто деловые решения, а не технические. В конечном счете, дизайн любого процесса загрузки ETL должен включать в себя обеспечение операций после сбоя. Используя конструкцию с первым отказом, предположим, что каждый процесс ETL завершится с ошибкой, и выполните сборку соответствующим образом.
Сбой рано, если это возможно
При прочих равных условиях лучше потерпеть неудачу рано, чем поздно в процессе. Ранний сбой позволяет избежать ненужных накладных расходов, если весь процесс придется перезапускать в случае сбоя. Неудача раньше, чем позже, также снижает вероятность необходимости очистки данных после сбоя. Есть случаи, когда поздние неудачи неизбежны (или даже предпочтительнее). Тем не менее, для большинства сценариев загрузки ETL это правило остается верным: по возможности сбой рано .
логирование
Редко я пишу пост о ETL, в котором нет напоминания о регистрации . Нигде логирование не является более важным, чем в дизайне обработки ошибок. Если ваш процесс ETL ничего не делает после сбоя, как минимум, он должен регистрировать детали сбоя. Сбор информации о сбоях очень важен для улучшения сортировки и архитектуры. Это вдвойне верно, если ваш процесс ETL подавляет или предотвращает ошибки. Единственный механизм, который дает вам историческое понимание логики ошибок, — это хорошая подсистема журналирования. Независимо от того, используете ли вы инструменты, встроенные в ваше программное обеспечение ETL, или пишете собственные, убедитесь, что вы собираете достаточно информации для регистрации, чтобы полностью документировать любые и все сбои.
Логика ошибок тестирования
Ранее я отмечал, что логика ошибок часто является запоздалой мыслью. Это еще более верно для проверки логики ошибок. Построение тестов на основе логики предотвращения ошибок и ответов так же важно, как тестирование логики загрузки ядра. Я даже не могу вспомнить, сколько раз мне звонили, чтобы помочь с процессами ETL, чтобы выяснить, что не только сбой загрузки, но и логика ошибок тоже. Тестирование процессов загрузки является сложным, а тестирование обработки ошибок ETL еще более. Однако только правильное тестирование обнаружит недостатки в вашей логике ошибок.
Вывод
Управление ошибками в ETL должно занимать центральное место в разработке этих процессов. У хорошей стратегии ETL будут меры по предотвращению и реагированию на ошибки при правильной детализации. Благодаря хорошо спроектированной обработке ошибок ETL процессы становятся более надежными, предсказуемыми и обслуживаемыми.
Managing Bad Data (Управление неверными данными)
Managing Bad Data (Управление неверными данными). Когда обнаружены подозрительные данные, должна срабатывать система для очистки или иного реагирования по устранению несоответствующих строкам данных. В этой статье я поделюсь некоторыми шаблонами проектирования для обработки неверных данных.
В последнем посте из моей продолжающейся серии статей о передовых практиках ETL я обсуждал важность обработки ошибок в процессах ETL , рассматривал передовые практики для потока приложений для предотвращения или постепенного восстановления после систематической ошибки или аномалии данных. В этой статье я углублюсь в эту тему, чтобы изучить шаблоны проектирования для управления неверными данными в процессах ETL.
Что такое плохие данные?
Плохой — это субъективный термин, и, соответственно, плохие данные . Следовательно, не существует единого неопровержимого определения неверных данных; она может и будет отличаться от одной организации к другой и от одного процесса ETL к другой. Тем не менее, вот общее руководство, которому я следую:
Неверные данные — это данные, происхождение или точность которых являются подозрительными, и в результате риск их использования превышает потенциальную ценность для бизнеса.
То, что считается плохими данными, будет широко варьироваться. При загрузке списка контактной информации для потенциальных потенциальных покупателей возможны пропущенные или неверные значения данных, которые, скорее всего, не являются дисквалифицирующим атрибутом. С другой стороны, при загрузке финансовых данных отсутствующее или недействительное значение для одной строки может сделать подозрительной всю загрузку данных. Точно так же происхождение данных может поставить под сомнение их значение (для любой загрузки в проверяемую систему) или может не оказать большого влияния (например, при расчете анализа настроений).
Часто первая и самая большая проблема при построении архитектуры ETL — решить, какие данные являются плохими. В конечном счете, бизнес-потребности — не обязательно технические требования — должны руководствоваться этой логикой.
Последний пункт определения границ неверных данных: это не всегда двоичное решение. На самом деле, большинство таких оценок являются «успешными / неудачными», но иногда возникает необходимость получить более детальную оценку качества данных. Создавайте эти относительные оценки качества данных, только если это необходимо; каждое создаваемое вами ведение увеличивает сложность и затраты на обслуживание.
Определение гранулярности
Определение гранулярности неправильной обработки данных обычно означает выбор одного из двух вариантов: строка за строкой или нагрузка в целом.
Управление подозрительными данными построчно
Обработка подозрительных данных обычно представляет собой построчную операцию. Из этих двух шаблонов проектирования обработка некорректных данных по очереди является гораздо более распространенным и более простым подходом. Используя этот подход, процесс ETL отфильтрует каждую подозрительную строку данных на основе критериев, установленных на предыдущем этапе, а затем очистит, перенаправит или удалит (подробнее об этих параметрах позже) каждую из этих строк.
Управление данными как нагрузка «все или ничего»
Существуют бизнес-кейсы, которые требуют подхода на уровне загрузки к неверным данным, когда весь процесс загрузки проходит успешно или завершается неудачей как единое целое. В этой схеме даже один подозрительный ряд данных среди миллионов может сделать недействительной всю нагрузку. Архитектура «все или ничего» требует механизма отката или удаления, который автоматически срабатывает в случае сбоя.
Прекрасным примером этого является процесс ETL, загружающий записи главной книги. В таких нагрузках исключение хотя бы одной строки данных из-за проблем с качеством данных может нарушить баланс всей нагрузки. Здесь лучше вообще не загружать данные, чем иметь частичный (и, следовательно, неверный) набор данных, записанных в место назначения.
Архитектура загрузки «все или ничего» более сложна, чем их построчная обработка ошибок. Используйте этот шаблон проектирования только в том случае, если этого требуют деловые или технические потребности; если есть сомнения, обработайте ошибки или другие аномалии на уровне строк.
Управление неверными данными в ETL
Как только определение неверных данных и детализация согласованы, следующим этапом является разработка тактического подхода к управлению неверными данными в ETL.
Хотя детали обработки неверных данных будут очень техническими, всегда имейте в виду, что деловые потребности должны определять поведение. Первой и главной проблемой при обработке неверных данных всегда должно быть влияние на бизнес.
Очистить в ETL
При обнаружении неверных данных используйте процесс ETL для очистки и продолжения обработки этих данных, если это возможно. Устранение недостатков данных в полете обычно имеет наименьшее количество остаточного багажа. Подозреваемые данные, которые могут быть очищены встроенными средствами, не страдают от задержки отдельного процесса (или, что еще хуже, вмешательства человека) для выполнения очистки перед использованием. Встроенная очистка данных также делает процесс очистки данных более четким, поскольку раздвоенный путь очистки обычно сливается с органически чистыми данными перед загрузкой в место назначения.

Как показано на блок-схеме выше, этот шаблон хранит заведомо исправные данные и подозрительные данные в параллельных конвейерах, объединяя их вместе после устранения недостатков. Этот шаблон предполагает гранулярность на уровне строк.
Прямая очистка данных — мой предпочтительный метод обработки подозрительных данных. Однако я не хочу подразумевать, что очистка данных — это простой процесс. Определение бизнес-правил и технических частей для обнаружения и очистки данных обычно требует значительных временных затрат, особенно когда эти бизнес-правила сложны.
Большинство систем ETL имеют встроенную логику для обработки некоторых наиболее распространенных операций очистки данных, а также интерфейсы сценариев, позволяющие вам создавать собственные решения для обеспечения качества данных. Для более сложных задач стороннее решение может быть правильным решением. Например, вы можете написать свою собственную логику проверки адресов, но создание этой логики И поддержание точной базы данных адресов, вероятно, будет стоить больше времени и денег, чем использование стороннего поставщика, уже оборудованного для таких операций. Обратите внимание на влияние на производительность и ограничения объема данных при использовании поставщика для работы с качеством данных, так как большинство из них используют облачный сервис и лицензируют свое программное обеспечение на основе объема данных.
При построении встроенной архитектуры очистки данных для управления неверными данными в ETL следует учитывать следующие особенности проектирования:
- Поскольку этот процесс будет изменять данные во время полета, обязательно сохраняйте контрольный журнал очистки изменений.
- Будут ли случаи, когда данные не могут быть исправлены? Если это так, создайте предохранительный клапан для сортировки (или удаления, если необходимо) неразрешимых неверных данных.
- Поскольку каждая подозрительная строка данных будет обрабатываться индивидуально, помните о возможных узких местах производительности, если для операции очистки требуется много системных ресурсов.
сортировка
Шаблон проектирования сортировки полезен для проблем качества данных, которые не могут быть решены в оперативном режиме. Здесь подозрительные строки остаются нетронутыми и записываются в альтернативное местоположение, которое будет рассматриваться в отдельном процессе. Процесс ETL становится системой с двумя выходами, где хорошие данные отправляются в свое обычное место назначения, в то время как подозрительные данные записываются в выходной сигнал сортировки.

Хотя эта блок-схема указывает на более простую конструкцию, чем встроенная архитектура очистки, это показывает только часть решения. Редко подозрительные данные остаются в сортировке навсегда; в большинстве случаев существуют дополнительные процессы — или, возможно, даже вмешательство человека — для исправления тригифицированных данных и загрузки их в конечный пункт назначения.
Этот шаблон проектирования полезен в случаях, когда исправление слишком сложно для моделирования в очищающем бизнес-правиле или когда бизнес-правила субъективны и требуют вмешательства человека для подтверждения любых изменений данных. Кроме того, этот шаблон может быть полезен, когда некоторые бизнес-правила зависят от агрегации всего набора данных, которые трудно обрабатывать в потоке.
Несколько вещей, которые следует иметь в виду при использовании вывода triage для сбора подозрительных данных:
- Обязательно тщательно протестируйте процесс (ы), которые взаимодействуют с обработанными данными. Недостаточно отправить подозрительные данные в triage, поэтому модульного тестирования вышеупомянутой архитектуры недостаточно.
- При создании тех периферийных процессов, которые очищают данные в triage, не забудьте извлечь из triage все очищенные строки и записать их в окончательный вывод. В противном случае таблица сортировки будет продолжать расти, и производительность в конечном итоге пострадает.
- Поскольку в этом шаблоне используются два (или, возможно, больше) выходных сигнала, возможно непреднамеренная потеря данных в конвейере ETL, если один из выходных сигналов не был правильно подключен. Настоятельно рекомендуется использовать аудит количества строк, чтобы убедиться, что все входящие строки данных учтены в одном из выходных данных.
Удалить
Я стесняюсь даже привести этот шаблон дизайна по причинам, которые я перечислю в ближайшее время. Однако в интересах всестороннего освещения этой темы я кратко опишу схему удаления неверных данных. Короче говоря, этот шаблон проектирования выглядит очень похоже на шаблон сортировки, описанный выше, за исключением того, что неверные данные просто отбрасываются.
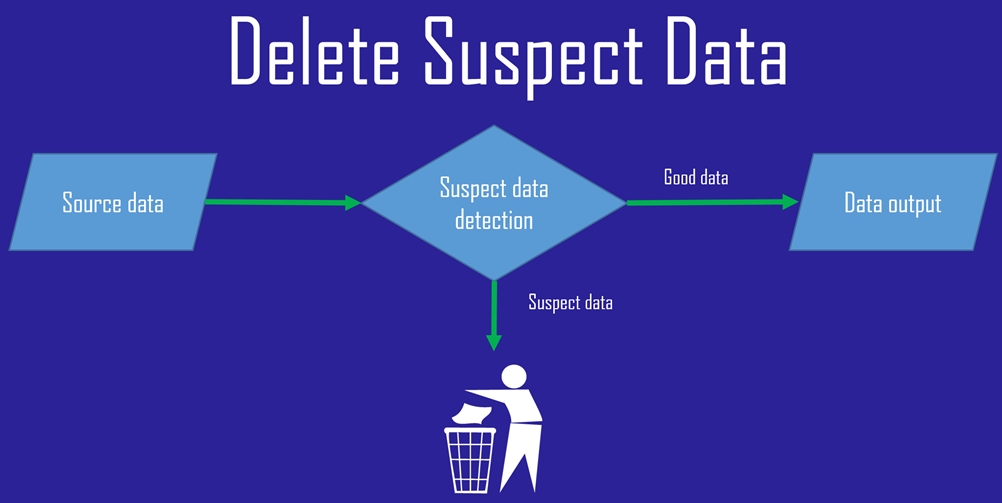
Как показано на приведенной выше блок-схеме, сохраняются только хорошие данные. Строки, не прошедшие проверку качества данных, отправляются в область битов.
Положительным моментом является то, что этот шаблон дизайна отличается простотой разработки. Недостатком является то, что я не могу особо подчеркнуть серьезность этого момента, вы потеряете данные . Не только данные — вы также потеряете любой контрольный журнал, показывающий, что данные были обработаны, но отклонены. Кроме того, вы потеряете способность проверять логику управления качеством данных с использованием исторических неверных данных. В некоторых крайних случаях это может быть приемлемым. Этот шаблон проектирования следует учитывать для обработки подозрительных неверных данных только в том случае, если выполняются все следующие условия:
- Не существует практического способа устранения недостатка данных, приводящего к тому, что записи переходят в состояние ошибки
- Нет никакого смысла в том, чтобы иметь какие-либо данные в любом столбце или поле в строке данных, которые не прошли проверку качества данных
- Удаление одной или нескольких записей не влияет на достоверность или полноту импортированных данных.
- В этом наборе данных нет процессов, требующих аудита
- Нет планов по изменению критериев, определяющих хороший или плохой ряд данных.
Лично, даже если все вышеприведенные утверждения верны, я все равно буду сопротивляться простому удалению этих подозрительных строк. Я ненавижу потерять данные, даже если это специально . Если ничего другого, хранение неверных данных в таблице дампа или файле может быть полезно для проверки логики оценки качества данных.
Гибридный подход
В действительности большинство конвейеров для управления неверными данными в ETL используют объединение вышеуказанных шаблонов проектирования. Часто я вижу встроенную очистку, используемую с шаблоном сортировки, при которой данные, которые невозможно очистить, отправляются в таблицу или файл сортировки. Кроме того, в проекте ETL, состоящем из множества отдельных процессов загрузки, обработка подозрительных данных может и будет варьироваться от одной загрузки к другой.
Аудиторская проверка
Я кратко упомянул об этом ранее, но это достаточно важно повторить. При создании процесса, который управляет неверными данными, убедитесь, что вы записываете цифровой контрольный журнал при манипулировании или фильтрации данных, прежде чем загружать их в конечный пункт назначения. Эта цепочка доказательств имеет решающее значение для устранения неполадок, документирования происхождения данных и, иногда, для целей CYA.
Вывод
Управление неверными данными в ETL является требованием во многих корпоративных проектах ETL. Данные могут быть очищены в ETL, сохранены в сортировке или просто отброшены, если обнаружены недостатки. Прежде всего, помните, что обработка подозрительных данных должна отвечать потребностям бизнеса.
Get Your Email Out Of My ETL (Получите ваш адрес электронной почты из моего ETL)
Get Your Email Out Of My ETL (Получите ваш адрес электронной почты из моего ETL). Для каждой работы есть подходящий инструмент. Внедрение уведомлений по электронной почте непосредственно в процессы ETL добавляет ненужную сложность и возможные точки отказа.
Версия этого поста — я позволил моим процессам extract-transform-load делать только ETL и оставлять уведомления системе планирования, которой они принадлежат.
Получите ваш электронный адрес из моего ETL
Прежде чем читать дальше, вы должны знать, что я выздоравливающий писатель ETL. Не так много лет назад я бы включил все — и я имею в виду все — в свои процессы ETL (обычно с использованием SSIS). Даже вещи, которые на самом деле не имеют ничего общего с перемещением данных. Конечно, это включало задачи уведомления по электронной почте. Однако за прошедшие годы я усвоил очень ценный урок: для каждой работы есть подходящий инструмент . Быстрые исправления приносят быстрое облегчение, но часто за счет устойчивости и общей стоимости владения.
Начнем с рассмотрения причин, по которым вы могли бы в первую очередь включить логику уведомлений по электронной почте в процессы ETL. Безусловно, наиболее распространенной причиной является уведомление кого-либо (или группы людей), когда что-то идет не так в процессе ETL. Менее распространенные причины включают в себя необходимость уведомлений о завершении каждого процесса (плохая идея сама по себе, но я оставлю это обсуждение на другой день) или желание отправить подмножество или совокупность данных (например, количество строк или долларовая сумма) для проверки. Каждый крупный поставщик ETL включает возможности электронной почты, которые соблазнительно легко внедрить в существующие загрузки ETL. И давайте не будем ошибаться: некоторые уведомления имеют решающее значение, особенно те, которые предназначены для привлечения внимания людей, которые должны реагировать на сбои загрузки данных или аномалии. Тем не мение,
В чем проблема?
Что плохого в использовании процессов загрузки ETL для прямой отправки электронной почты? Позвольте мне сосчитать пути.
Это еще одна потенциальная точка отказа для процесса ETL . Если загрузка ETL проходит нормально, но что-то идет не так с уведомлением по электронной почте, может показаться, что операция загрузки данных прервана, хотя на самом деле это всего лишь шаг электронной почты. Еще хуже, если уведомление по электронной почте происходит в середине загрузки с другими шагами за ним, теперь у вас остается частично завершенная загрузка — все из-за сбоя операции, даже не являющейся центральной для операций с данными.
С некоторыми низкоуровневыми сбоями вы никогда не получите уведомление . Мой инструмент ETL — SSIS , так что вот как это будет работать: некоторая часть структуры данных источника или назначения изменяется, и пакет SSIS обнаруживает, что ему нужно обновить метаданные. Поскольку этот этап проверки выполняется до начала какой-либо реальной работы, возможно, что ни одна часть пакета — даже обработка ошибок или логика уведомлений — не будет запущена. Дерево упадет в лес, и никто его не услышит.
Это удлиняет процесс разработки и тестирования . Процессы ETL часто бывают сложными и требуют нескольких недель или месяцев. Зачем излишне загромождать процесс разработки и тестирования большим количеством движущихся частей, которые не являются основной частью перемещения данных?
Несогласованность . В самой последней статье из серии ETL Best Practices я говорил о модульности кода . Одним из преимуществ модульных процессов является последовательность. Если вы вставляете множество специальных уведомлений об исключениях в пакеты ETL, их трудно поддерживать согласованными. Конечно, у вас может быть общий процесс, подобный тому, что я описал в модульном посте, но это требует дополнительной сложности, которая является второстепенной по отношению к основной цели процесса ETL.
Невозможно включить всю необходимую информацию для отладки в электронное письмо с уведомлением, Когда я советую клиентам и слушателям курсов не отправлять уведомления непосредственно из ETL, общий аргумент заключается в том, что они хотят включить как можно больше отладочной информации в электронное письмо с уведомлением, чтобы дать отвечающему технику или инженеру все, что им нужно для начала работы над проблемой. Для включения всей этой информации необходим доступ во время выполнения к сообщениям об ошибках, таким образом, аргумент для отправки электронной почты непосредственно из загрузки ETL. Моя реплика такова: насколько реально, что вы включите в электронное письмо всю информацию, необходимую для фактической диагностики проблемы? Любой, кто просматривал журналы из любой системы ETL, может засвидетельствовать тот факт, что каждая ошибка порождает пять других, и так далее. Выяснить истинную причину — это не то, что вы можете автоматизировать,
Это неуклюжее . Возможно, где-то есть лучшая мышеловка, но у систем ETL, с которыми я работал, есть интерфейсы электронной почты, которые в лучшем случае зачаточны. Задачи электронной почты в программном обеспечении ETL ограничены по функциональности и не совсем рассчитаны на надежность.
Лучший путь
Как я упоминал ранее, для каждой работы есть инструмент. При рассмотрении роли уведомлений по электронной почте это скорее механизм планирования, чем функция ETL. Поэтому я рекомендую всегда рассматривать ваш инструмент планирования в качестве основного средства для создания уведомлений об исключениях для нагрузок ETL. Каждый инструмент планирования предприятия, от агента SQL Server, включенного в состав SQL Server, до коммерческих продуктов, таких как Control-M или JAMS, имеет встроенные средства уведомления по электронной почте. Перенесите ваши уведомления об исключениях в любой инструмент, который планирует работу.
Чтобы ускорить процесс устранения неполадок, добавьте URL-адрес или другой ярлык к своим отчетам, содержащим информацию о вашей регистрации. Как отмечалось выше, пытаться втиснуть все связанные с этим ошибки в электронное письмо с уведомлением бесполезно, и в конце концов ответчик в любом случае просто перейдет к таблицам регистрации. Используйте уведомление по электронной почте, чтобы предоставить им этот ярлык.
Наконец, если вы убеждены в том, что вам действительно нужно включить информацию об ошибках в уведомления по электронной почте, вы можете воспользоваться для этого своими инструментами отчетности. Например, службы отчетов SQL Server позволят вам использовать управляемые данными подписки для отправки настроенных электронных писем для отправки отфильтрованных данных журнала нужным получателям.
Вывод
Использование уведомлений по электронной почте из вашего инструмента ETL может показаться быстрым и простым способом добавления предупреждений к загрузке данных, но в конечном итоге этот шаблон проектирования оказывается головной болью при обслуживании. Используйте правильный инструмент для работы, и пусть ваш инструмент планирования справится с этой задачей.
Using ETL Staging Tables (Использование промежуточных таблиц ETL)
Using ETL Staging Tables (Использование промежуточных таблиц ETL). Часто использование промежуточных таблиц может повысить производительность и снизить сложность процессов ETL.
Большинство традиционных процессов ETL выполняют свои загрузки, используя три отдельных и последовательных процесса: извлечение с последующим преобразованием и, наконец, загрузку в место назначения. Однако для некоторых больших или сложных нагрузок использование промежуточных таблиц ETL может повысить производительность и снизить сложность.
Как часть моей продолжающейся серии по ETL передовой практике , в этой статье я буду некоторые рекомендации по использованию таблиц ETL стадирования.
Обычный трехступенчатый ETL
Процессы извлечения, преобразования и загрузки, как подразумевается в этой метке, обычно имеют следующий рабочий процесс:
- Получить (извлечь) данные из их источника, который может быть реляционной базой данных, простым файлом или облачным хранилищем
- Изменять и очищать (преобразовывать) данные по мере необходимости, чтобы вписаться в схему назначения и применить любые правила очистки или бизнес-правила
- Вставьте (загрузите) преобразованные данные в место назначения, которое обычно (но не всегда) является таблицей реляционной базы данных
Этот типичный рабочий процесс предполагает, что каждый процесс ETL обрабатывает преобразование встроенно, обычно в памяти и до того, как данные попадают в место назначения. Для большинства потребностей ETL этот шаблон работает хорошо. Каждый инструмент ETL корпоративного класса построен со сложными инструментами преобразования, способными выполнять многие из этих общих задач очистки, дедупликации и преобразования. Этот трехэтапный процесс перемещения и манипулирования данными поддается простоте, а при прочих равных условиях чем проще, тем лучше.
Однако есть случаи, когда простое извлечение, преобразование и загрузка не подходят. Среди этих потенциальных случаев:
- Для каждой загружаемой строки требуется что-то из одной или нескольких других строк в том же наборе данных (например, определение порядка или группировки или промежуточного итога)
- Исходные данные используются для обновления (а не для вставки в) назначения
- Процесс ETL представляет собой инкрементную нагрузку, но объем данных является достаточно значительным, так что сравнение строк за строкой на этапе преобразования неэффективно
- Преобразование данных требует нескольких шагов, и вывод одного шага преобразования становится вводом другого
Хотя обычно все это можно выполнить с помощью одного этапа преобразования в процессе, это может привести к снижению производительности или излишней сложности. Я сторонник использования правильного инструмента для работы, и часто лучший способ обработать груз — это позволить базе данных назначения выполнить некоторые тяжелые работы.
Использование промежуточных таблиц ETL
Когда объем или детализация процесса преобразования приводит к плохой работе процессов ETL, рассмотрите возможность использования промежуточной таблицы в базе данных назначения в качестве средства для обработки результатов промежуточных данных. Промежуточные таблицы обычно рассматриваются как изменчивые таблицы, то есть они очищаются и перезагружаются каждый раз без сохранения результатов от одного выполнения к другому. Промежуточные таблицы следует использовать только для промежуточных результатов, а не для постоянного хранения.
При использовании схемы загрузки с промежуточными таблицами поток ETL выглядит примерно так:
- Удалить существующие данные в промежуточных таблицах
- Извлечь данные из источника
- Загрузите эти исходные данные в промежуточные таблицы
- Выполните реляционные обновления (обычно используя T-SQL, PL / SQL или другой язык, специфичный для вашей СУБД), чтобы очистить или применить бизнес-правила к данным, повторяя этот этап преобразования по мере необходимости
- Загрузите преобразованные данные из промежуточной таблицы (таблиц) в окончательную таблицу (таблицы) назначения
Этот шаблон проектирования нагрузки имеет больше шагов, чем традиционный процесс ETL, но он также обеспечивает дополнительную гибкость. Загрузив данные сначала в промежуточные таблицы, вы сможете использовать ядро базы данных для вещей, которые уже хорошо работают. Например, объединение двух наборов данных вместе для целей проверки или поиска может быть выполнено в большинстве инструментов ETL, но это тип задач, который механизм базы данных выполняет исключительно хорошо. То же самое с выполнением операций сортировки и агрегирования; Инструменты ETL могут делать эти вещи, но в большинстве случаев ядро базы данных делает это тоже, но гораздо быстрее.
Варианты промежуточных столов
При использовании промежуточных таблиц для сортировки данных вы включаете поведения СУБД, которые, вероятно, недоступны при обычном преобразовании ETL. Например, вы можете создавать индексы для промежуточных таблиц, чтобы повысить производительность последующей загрузки в постоянные таблицы. Вы можете запустить несколько преобразований для одного и того же набора данных, не сохраняя их в памяти на время этих преобразований, что может снизить влияние на производительность.
Промежуточные таблицы также позволяют легко запрашивать эти промежуточные результаты с помощью простого запроса SQL. Кроме того, вы можете повторно использовать некоторые поэтапные данные в тех случаях, когда относительно статические данные используются несколько раз при одной и той же загрузке или в нескольких процессах загрузки.
Кроме того, для некоторых крайних случаев я использовал шаблон, который имеет несколько слоев промежуточных таблиц, и первая промежуточная таблица используется для загрузки второй промежуточной таблицы. Это шаблон проектирования, которым я редко пользуюсь, но он пригодился в тех случаях, когда форма или структура данных должна была существенно измениться в процессе загрузки.
Это все еще ETL?
Те, кто педантичен по поводу терминологии (в эту группу часто входит и я), захотят знать: при использовании этого сценария постановки процесса этот процесс все еще называется ETL? Как правило, вы увидите этот процесс, называемый ELT — извлечение, загрузка и преобразование — потому что загрузка до места назначения выполняется до того, как произойдет преобразование. Я видел много вариантов этого, включая ELTL (извлечение, загрузка, преобразование, загрузка). Тем не менее, я склонен использовать ETL в качестве широкой метки, которая определяет получение данных из некоторого источника, некоторую меру преобразования по пути, сопровождаемую загрузкой в конечный пункт назначения. Семантически я считаю ELT и ELTL специфическими шаблонами проектирования в широкой категории ETL.
Также имейте в виду, что использование промежуточных таблиц должно оцениваться для каждого процесса отдельно. Промежуточная архитектура ETL является одним из нескольких шаблонов проектирования и не идеально подходит для всех нагрузок. Любая зрелая инфраструктура ETL будет иметь смесь обычных ETL, поэтапных ETL и других вариантов в зависимости от специфики каждой нагрузки.
Советы по использованию промежуточных таблиц ETL
Когда вы решите использовать промежуточные таблицы в процессах ETL, вот несколько соображений, о которых следует помнить:
Отделите промежуточные столы ETL от долговечных столов . Должно быть некоторое логическое, если не физическое, разделение между стойкими таблицами и теми, которые используются для подготовки ETL. Вы получите наибольшее преимущество в производительности, если они существуют в одном экземпляре базы данных, но хранение этих промежуточных таблиц в отдельной схеме — или, возможно, даже в отдельной базе данных — прояснит разницу между промежуточными таблицами и их надежными аналогами. Разделение их физически на разные файлы также может снизить конфликт дискового ввода-вывода во время загрузки.
Используйте постоянные промежуточные таблицы, а не временные таблицы . Основные поставщики реляционных баз данных позволяют создавать временные таблицы, которые существуют только на время соединения. Обычно я рекомендую избегать их, потому что запрос промежуточных результатов в этих таблицах (обычно для целей отладки) может оказаться невозможным вне рамок процесса ETL. Кроме того, некоторые инструменты ETL, включая службы интеграции SQL Server, могут сталкиваться с ошибками при попытке выполнить проверку метаданных по таблицам, которые еще не существуют.
Подумайте об индексации ваших промежуточных таблиц . Не произвольно добавляйте индекс для каждой промежуточной таблицы, но подумайте, как вы используете эту таблицу на последующих шагах загрузки ETL. В некоторых случаях использование правильно размещенного индекса ускорит процесс.
Рассмотрите возможность очистки промежуточного стола до и после загрузки . Вы наверняка захотите удалить данные из последней загрузки в начале выполнения процесса ETL, но подумайте и об их очистке позже. Особенно при работе с большими наборами данных очистка промежуточной таблицы приведет к сокращению времени и объема дискового пространства, необходимого для резервного копирования базы данных.
Вам нужно запустить несколько одновременных загрузок одновременно? Для большинства нагрузок это не будет проблемой. Однако некоторые нагрузки могут выполняться целенаправленно для перекрытия — то есть два экземпляра одного и того же ETL-процесса могут выполняться в любой момент времени — и в этих случаях вам потребуется более тщательная разработка промежуточных таблиц. Как правило, промежуточные таблицы просто усекаются для удаления предыдущих результатов, но если промежуточные таблицы могут содержать данные из нескольких перекрывающихся каналов, вам необходимо добавить поле, идентифицирующее эту конкретную нагрузку, чтобы избежать конфликтов параллелизма.
Правильно обрабатывать данные . Если ваши процессы ETL созданы для отслеживания происхождения данных , убедитесь, что ваши промежуточные таблицы ETL настроены для поддержки этого. Линия данных предоставляет цепочку доказательств от источника до конечного пункта назначения, обычно на уровне строк. Если вы отслеживаете происхождение данных, вам может потребоваться добавить один или два столбца в промежуточную таблицу, чтобы правильно отследить это.
Вывод
Хотя обычный трехэтапный процесс ETL очень хорошо обслуживает многие потребности в загрузке данных, бывают случаи, когда использование промежуточных таблиц ETL может повысить производительность и снизить сложность. Хороший шаблон проектирования для поэтапной загрузки ETL является неотъемлемой частью правильно оборудованного инструментария ETL.
Secure Your Data Prep Area (Защитите свою область подготовки данных)
Secure Your Data Prep Area (Защитите свою область подготовки данных). Staging или Landing area обрабатываемых в настоящее время данных не должна быть доступна потребителям данных. В противном случае вы можете получить неверные данные, противоречивую аналитику или потенциальные угрозы безопасности.
Я много лет строил процессы ETL, и я узнал две универсальные истины: подготовка данных грязная, и вы всегда должны защищать свою область подготовки данных. Область подготовки данных очень похожа на коммерческую кухню и так же, как клиенты не допускаются на кухню, поэтому следует избегать доступа потребителей к структурам данных в процессе.
Что такое область подготовки данных?
Прежде всего, давайте определимся с областью подготовки данных. Подготовка данных (prep) — это обычная фаза операций извлечения, преобразования и загрузки ( ETL ), в которой данные временно записываются для очистки, дедупликации, изменения формы или других изменений данных. Также иногда называемый областью посадки или промежуточной области, это общий шаблон проектирования при перемещении данных из хранилища данных, оптимизированных для оперативной обработки транзакций ( OLTP ), в модель данных, более удобную для аналитики или отчетности.
Область подготовки данных действительно очень похожа на кухню ресторана: иногда она хаотична, не удобна для потребителей и существует законный риск потребления полуфабрикатов.
Когда клиенты бродят по кухне
Несмотря на свое предназначение, потребители данных нередко имеют доступ к области подготовки данных. И я понял — иногда удобно позволить пользователям возиться с необработанными данными, особенно с навыками Excel на уровне мастера. Однако при открытии области подготовки данных для конечных пользователей существуют ощутимые риски:
- Данные находятся в промежуточном состоянии . По определению область подготовки или подготовки данных предназначена для временного хранения текущих операций с данными. Предоставление потребителям данных доступа к этим данным сродни тому, чтобы подавать им частично приготовленную еду. Средне-редкая курица, кто-нибудь?
- Нет единого источника правды . Наихудший возможный результат любого перемещения или преобразования данных состоит в том, что существует несколько возможных источников данных, дающих ответы на одни и те же вопросы. Если область подготовки данных является временной остановкой на пути к хранилищу данных или ODS, предоставление доступа к этой промежуточной станции практически гарантирует, что содержащиеся в ней данные будут конкурировать с полностью обработанными и проверенными данными в DW или ODS.
- Доступ пользователя может помешать подготовке данных . Если пользователи выполняют дорогостоящие запросы во время выполнения процессов ETL, производительность обоих процессов может снизиться. В области подготовки данных процессы ETL должны иметь приоритет.
- Возможные угрозы безопасности . Хотя это не должно быть так, область подготовки данных иногда не получает такой же уровень контроля безопасности, как хранилище данных или другие структуры, ориентированные на пользователя. Если пользователи обращаются к этому временному хранилищу данных напрямую, они могут случайно получить доступ, которого у них обычно не должно быть.
Защитите свою область подготовки данных!
Хотя это требует определенной институциональной дисциплины, я настоятельно рекомендую ограничить доступ пользователей к вашей области подготовки данных. Это помогает устранить некоторые риски получения плохих или противоречивых результатов и сохраняет эту зону посадки данных в соответствии с ее назначением.